DuwatBench: Bridging Language and Visual Heritage through an Arabic Calligraphy Benchmark for Multimodal Understanding
作者: Shubham Patle, Sara Ghaboura, Hania Tariq, Mohammad Usman Khan, Omkar Thawakar, Rao Muhammad Anwer, Salman Khan
分类: cs.CV
发布日期: 2026-01-27
备注: Accepted to EACL-2026 (Main Track)
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
提出DuwatBench:一个用于多模态理解的阿拉伯书法基准数据集。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 阿拉伯书法 多模态理解 基准数据集 视觉-文本对齐 文化遗产 阿拉伯语 文本识别
📋 核心要点
- 现有多模态模型在处理阿拉伯书法这种具有复杂笔画和风格变异的艺术化文本时,能力不足。
- DuwatBench通过提供包含多种书法风格和句子级别注释的数据集,弥合了语言和视觉遗产之间的差距。
- 实验表明,现有模型在DuwatBench上表现不佳,突显了该数据集对推进相关研究的价值。
📝 摘要(中文)
阿拉伯书法是阿拉伯语言最丰富的视觉传统之一,它将语言意义与艺术形式融合在一起。尽管多模态模型在各种语言中取得了进展,但它们处理阿拉伯文字的能力,尤其是在艺术化和风格化的书法形式方面,在很大程度上仍未被探索。为了解决这一差距,我们提出了DuwatBench,一个包含1,272个精心策划的样本的基准,其中包含六种古典和现代书法风格的约1,475个独特单词,每个样本都配有句子级别的检测注释。该数据集反映了阿拉伯写作中真实世界的挑战,例如复杂的笔画模式、密集的连字以及风格变化,这些变化通常会挑战标准的文本识别系统。我们使用DuwatBench评估了13个领先的阿拉伯语和多语种多模态模型,结果表明,虽然它们在干净的文本上表现良好,但在书法变体、艺术扭曲和精确的视觉-文本对齐方面表现不佳。通过公开发布DuwatBench及其注释,我们旨在推进具有文化基础的多模态研究,促进阿拉伯语言和视觉遗产在人工智能系统中的公平包容,并支持该领域的持续进步。我们的数据集和评估套件已公开发布。
🔬 方法详解
问题定义:论文旨在解决多模态模型在理解和处理阿拉伯书法时面临的挑战。现有的多模态模型在处理标准文本时表现良好,但在面对阿拉伯书法中常见的复杂笔画、密集连字和风格变异时,性能显著下降。这主要是因为现有模型缺乏针对阿拉伯书法特点的训练数据和评估基准。
核心思路:论文的核心思路是构建一个高质量的阿拉伯书法数据集DuwatBench,用于评估和提升多模态模型在理解阿拉伯书法方面的能力。通过提供包含多种书法风格和句子级别注释的数据集,可以帮助研究人员更好地了解现有模型的局限性,并开发更有效的模型。
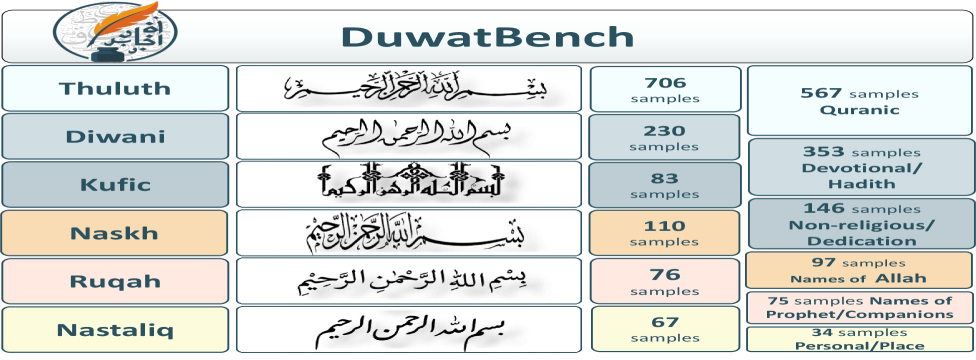
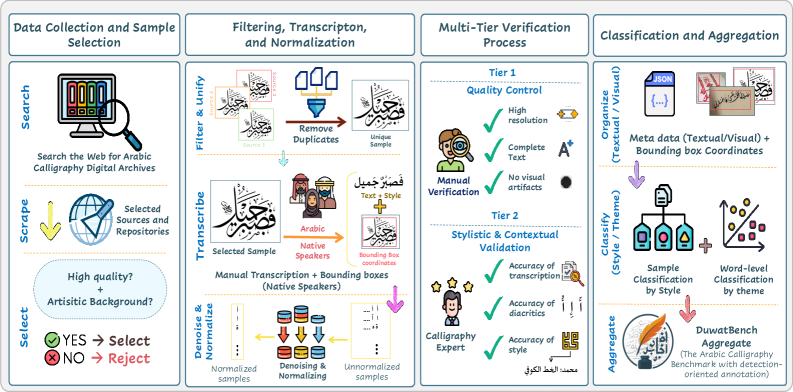
技术框架:DuwatBench数据集包含1,272个精心策划的样本,涵盖六种古典和现代书法风格。每个样本都包含阿拉伯书法图像以及相应的句子级别文本注释。数据集的构建流程包括:数据收集、数据清洗、数据标注和数据验证。此外,论文还提供了一个评估套件,用于评估多模态模型在DuwatBench上的性能。
关键创新:DuwatBench的主要创新在于它是第一个专门针对阿拉伯书法的多模态基准数据集。与现有的通用多模态数据集相比,DuwatBench更加关注阿拉伯书法的特点,例如复杂的笔画、密集连字和风格变异。这使得DuwatBench能够更准确地评估多模态模型在理解阿拉伯书法方面的能力。
关键设计:DuwatBench数据集包含六种不同的阿拉伯书法风格,涵盖了古典和现代风格。数据集中的每个样本都配有句子级别的文本注释,这使得研究人员可以评估模型在视觉-文本对齐方面的能力。此外,数据集还包含一些具有挑战性的样本,例如包含艺术扭曲和风格变异的样本,用于评估模型的鲁棒性。
🖼️ 关键图片

📊 实验亮点
研究人员使用DuwatBench评估了13个领先的阿拉伯语和多语种多模态模型。实验结果表明,这些模型在干净的文本上表现良好,但在书法变体、艺术扭曲和精确的视觉-文本对齐方面表现不佳。这表明DuwatBench能够有效地揭示现有模型在处理阿拉伯书法方面的局限性,并为未来的研究提供了方向。
🎯 应用场景
DuwatBench数据集可用于训练和评估多模态模型,以提高其在理解和处理阿拉伯书法方面的能力。这在文化遗产保护、艺术品数字化、古籍文献识别等领域具有重要的应用价值。此外,该数据集还可以促进阿拉伯语言和文化在人工智能系统中的公平包容,并推动相关领域的研究进展。
📄 摘要(原文)
Arabic calligraphy represents one of the richest visual traditions of the Arabic language, blending linguistic meaning with artistic form. Although multimodal models have advanced across languages, their ability to process Arabic script, especially in artistic and stylized calligraphic forms, remains largely unexplored. To address this gap, we present DuwatBench, a benchmark of 1,272 curated samples containing about 1,475 unique words across six classical and modern calligraphic styles, each paired with sentence-level detection annotations. The dataset reflects real-world challenges in Arabic writing, such as complex stroke patterns, dense ligatures, and stylistic variations that often challenge standard text recognition systems. Using DuwatBench, we evaluated 13 leading Arabic and multilingual multimodal models and showed that while they perform well on clean text, they struggle with calligraphic variation, artistic distortions, and precise visual-text alignment. By publicly releasing DuwatBench and its annotations, we aim to advance culturally grounded multimodal research, foster fair inclusion of the Arabic language and visual heritage in AI systems, and support continued progress in this area. Our dataset (https://huggingface.co/datasets/MBZUAI/DuwatBench) and evaluation suit (https://github.com/mbzuai-oryx/DuwatBench) are publicly available.