VGGT-SLAM 2.0: Real time Dense Feed-forward Scene Reconstruction
作者: Dominic Maggio, Luca Carlone
分类: cs.CV, cs.RO
发布日期: 2026-01-27
💡 一句话要点
VGGT-SLAM 2.0:实时稠密前馈场景重建,提升精度与效率
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: SLAM 视觉几何图 场景重建 因子图优化 注意力机制 图像检索 实时系统
📋 核心要点
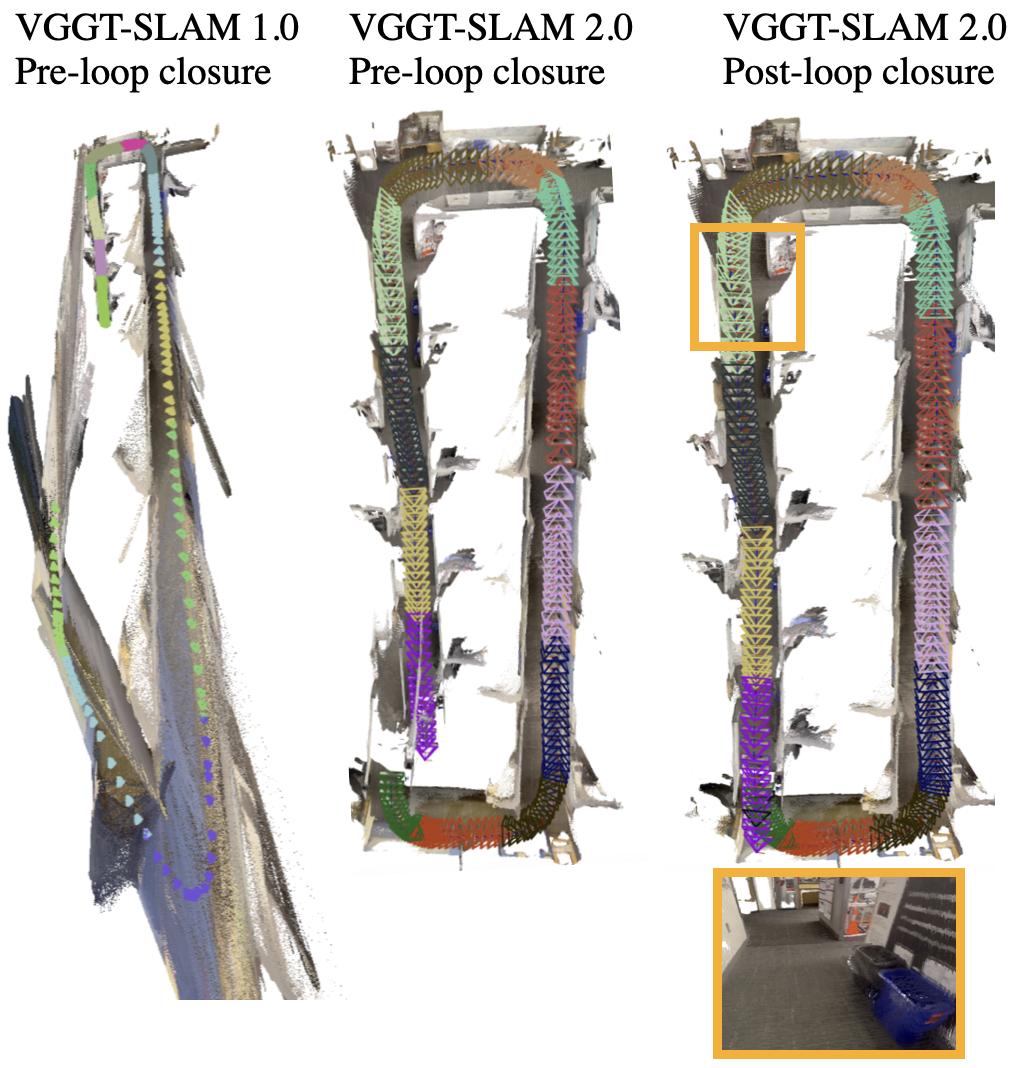
- 现有VGGT-SLAM存在高自由度漂移和平面退化问题,限制了其在复杂环境下的鲁棒性和精度。
- VGGT-SLAM 2.0通过设计新的因子图,并利用VGGT的注意力层进行图像检索验证,有效抑制漂移并提升回环检测能力。
- 实验表明,VGGT-SLAM 2.0在TUM数据集上精度显著提升,且能实时运行于Jetson Thor平台,并可扩展至开放集目标检测。
📝 摘要(中文)
本文提出了VGGT-SLAM 2.0,一个实时的RGB前馈SLAM系统,它在VGGT的基础上显著改进了增量对齐由VGGT创建的子地图。首先,通过创建一个新的因子图设计,消除了VGGT-SLAM中高维15自由度的漂移和平面退化,同时解决了在未知相机内参下VGGT的重建模糊性。其次,通过研究VGGT的注意力层,表明其中一层非常适合辅助图像检索验证,无需额外训练,从而能够拒绝假阳性匹配并完成更多的回环闭合。最后,进行了一系列实验,包括展示VGGT-SLAM 2.0可以轻松地适应开放集目标检测,并展示了在Jetson Thor上使用地面机器人的在线实时性能。还在杂乱的室内公寓和办公室场景以及4200平方英尺的谷仓等环境中进行了测试,并证明VGGT-SLAM 2.0在TUM数据集上实现了最高的精度,比VGGT-SLAM的位姿误差降低了约23%。代码将在发表后发布。
🔬 方法详解
问题定义:VGGT-SLAM虽然利用了视觉几何图(VGGT)进行场景重建,但在实际应用中,尤其是在大规模和长时间运行的情况下,会受到高维(15自由度)漂移和平面退化的影响,导致重建精度下降。此外,在未知相机内参的情况下,VGGT的重建结果存在模糊性。现有方法难以同时解决这些问题,限制了SLAM系统的鲁棒性和准确性。
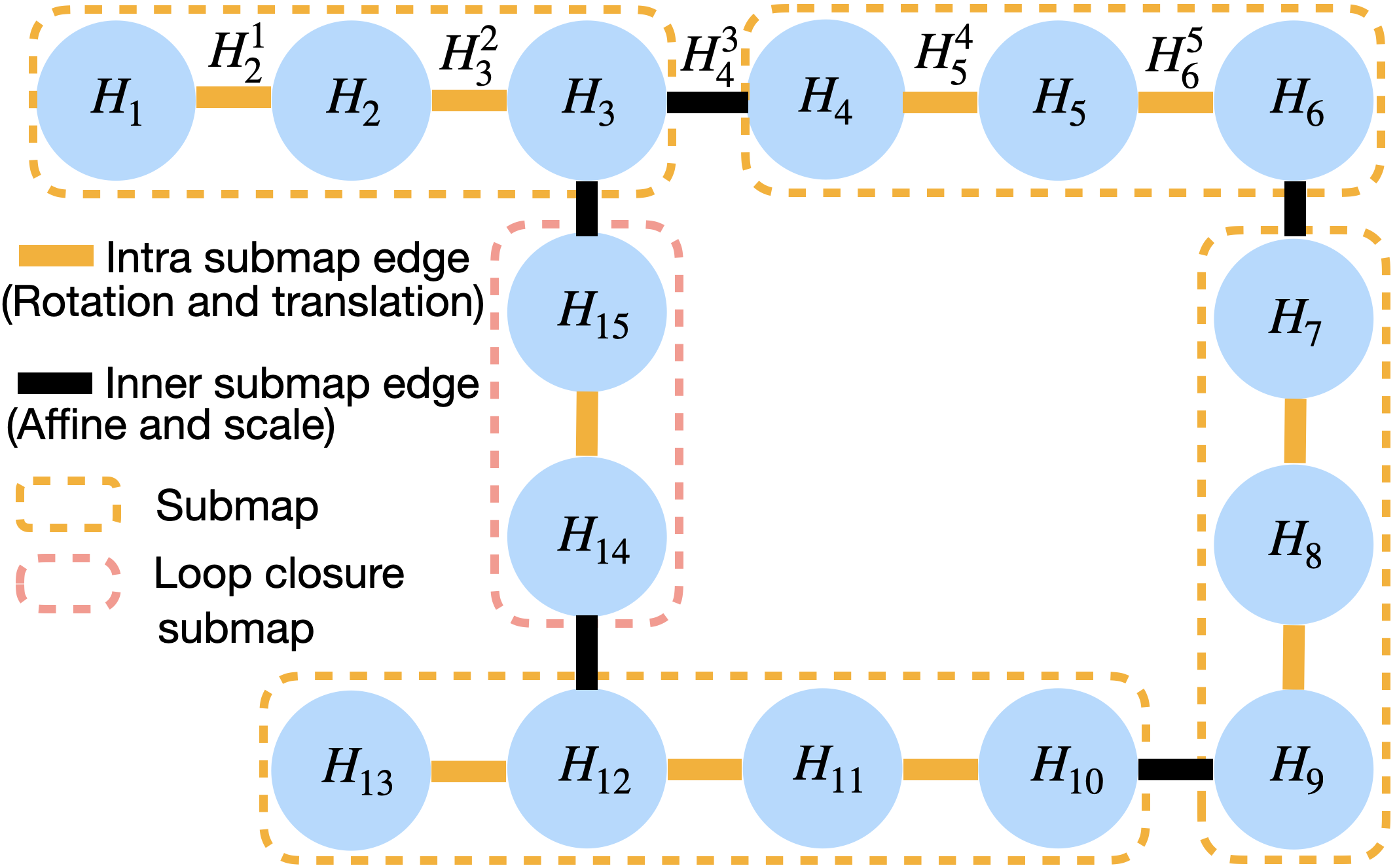
核心思路:VGGT-SLAM 2.0的核心思路是通过改进因子图设计来消除漂移和退化,并利用VGGT网络中的注意力层进行图像检索验证,从而提高回环检测的准确性和效率。这种设计旨在充分利用VGGT的特征提取能力,同时解决其固有的几何问题。
技术框架:VGGT-SLAM 2.0的整体框架仍然是基于SLAM系统,但其关键改进在于:1) 因子图优化:设计新的因子图结构,以约束高自由度的漂移和平面退化。2) 注意力层辅助图像检索:利用VGGT的注意力层提取的特征进行图像检索验证,过滤掉错误的匹配,并促进回环闭合。3) 增量式子地图对齐:通过上述改进,实现更准确的增量式子地图对齐,最终构建全局一致的场景地图。
关键创新:VGGT-SLAM 2.0最重要的创新在于将VGGT网络中的注意力机制应用于图像检索验证。通过分析VGGT的注意力层,发现其中一层的特征非常适合用于区分正确的和错误的图像匹配,从而避免了额外的训练成本,并显著提高了回环检测的可靠性。
关键设计:关于因子图的设计细节,论文中提到是“新的因子图设计”,但没有给出具体的公式或结构。关于注意力层的利用,论文提到是直接使用VGGT中已有的注意力层,无需额外训练,但没有详细说明如何提取和使用这些特征进行图像检索验证。这些细节需要在阅读论文全文后才能进一步了解。
🖼️ 关键图片

📊 实验亮点
VGGT-SLAM 2.0在TUM数据集上取得了最高的精度,位姿误差比VGGT-SLAM降低了约23%。此外,该系统能够在Jetson Thor平台上实时运行,并成功应用于地面机器人。实验还证明了VGGT-SLAM 2.0可以轻松地适应开放集目标检测任务,展示了其良好的泛化能力。
🎯 应用场景
VGGT-SLAM 2.0具有广泛的应用前景,包括但不限于:机器人导航、增强现实、虚拟现实、三维重建、自动驾驶等领域。其高精度和实时性使其能够应用于需要精确环境感知的场景,例如室内服务机器人、无人机巡检、以及自动驾驶车辆的环境建模。
📄 摘要(原文)
We present VGGT-SLAM 2.0, a real time RGB feed-forward SLAM system which substantially improves upon VGGT-SLAM for incrementally aligning submaps created from VGGT. Firstly, we remove high-dimensional 15-degree-of-freedom drift and planar degeneracy from VGGT-SLAM by creating a new factor graph design while still addressing the reconstruction ambiguity of VGGT given unknown camera intrinsics. Secondly, by studying the attention layers of VGGT, we show that one of the layers is well suited to assist in image retrieval verification for free without additional training, which enables both rejecting false positive matches and allows for completing more loop closures. Finally, we conduct a suite of experiments which includes showing VGGT-SLAM 2.0 can easily be adapted for open-set object detection and demonstrating real time performance while running online onboard a ground robot using a Jetson Thor. We also test in environments ranging from cluttered indoor apartments and office scenes to a 4,200 square foot barn, and we also demonstrate VGGT-SLAM 2.0 achieves the highest accuracy on the TUM dataset with about 23 percent less pose error than VGGT-SLAM. Code will be released upon publication.