Youtu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
作者: Zhixiang Wei, Yi Li, Zhehan Kan, Xinghua Jiang, Zuwei Long, Shifeng Liu, Hongze Shen, Wei Liu, Xiaoyu Tan, Haojia Lin, Yubo Zhu, Qianyu Li, Di Yin, Haoyu Cao, Weibo Gu, Xin Li, Yinsong Liu, Deqiang Jiang, Xing Sun, Yunsheng Wu, Mingkong Tang, Shuangyin Liu, Lexiang Tang, Haodong Lin, Junru Lu, Jiarui Qin, Lingfeng Qiao, Ruizhi Qiao, Bo Ke, Jianfeng He, Ke Li, Yangning Li, Yunhang Shen, Mengdan Zhang, Peixian Chen, Kun Yin, Bing Liu, Yunfei Wu, Huang Chen, Zhongpeng Cai, Xiaotian Li
分类: cs.CV
发布日期: 2026-01-27
💡 一句话要点
Youtu-VL:通过统一的视觉-语言监督释放视觉潜力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 多模态学习 自回归模型 视觉理解 统一监督 视觉智能体
📋 核心要点
- 现有视觉-语言模型在细粒度视觉信息保留上不足,导致多模态理解能力受限,无法充分利用视觉信息。
- Youtu-VL 采用视觉-语言统一自回归监督范式,将视觉信号视为监督目标,而非仅作为输入条件。
- Youtu-VL 在通用多模态任务和视觉中心任务上表现出竞争力,为通用视觉智能体的开发奠定基础。
📝 摘要(中文)
现有的视觉-语言模型(VLMs)在保留细粒度视觉信息方面存在局限性,导致粗粒度的多模态理解。这种缺陷源于VLMs中固有的次优训练范式,该范式表现出以文本为主导的优化偏差,将视觉信号仅仅概念化为被动的条件输入,而非监督目标。为了缓解这个问题,我们引入了Youtu-VL,一个利用视觉-语言统一自回归监督(VLUAS)范式的框架,它从根本上将优化目标从“视觉作为输入”转变为“视觉作为目标”。通过将视觉tokens直接集成到预测流中,Youtu-VL将统一的自回归监督应用于视觉细节和语言内容。此外,我们将这种范式扩展到以视觉为中心的任务,使标准的VLM能够在没有特定任务添加的情况下执行以视觉为中心的任务。大量的实验评估表明,Youtu-VL在通用多模态任务和以视觉为中心的任务上都取得了有竞争力的性能,为开发全面的通用视觉智能体奠定了坚实的基础。
🔬 方法详解
问题定义:现有视觉-语言模型(VLMs)在训练过程中存在“文本主导”的优化偏差,即模型更多地关注文本信息的理解和生成,而忽略了对视觉信息的充分利用。视觉信息通常被视为一种条件输入,而不是需要精确预测的目标,导致模型在处理细粒度视觉信息时能力不足。这种缺陷限制了VLMs在需要精细视觉理解的任务中的表现,例如视觉问答、图像描述等。
核心思路:Youtu-VL的核心思路是将视觉信息也作为模型需要预测的目标,从而改变传统的“视觉作为输入”的模式。通过引入视觉-语言统一自回归监督(VLUAS)范式,模型不仅需要预测文本信息,还需要预测视觉tokens,从而迫使模型更加关注和理解视觉细节。这种设计旨在平衡文本和视觉信息在模型训练中的重要性,提升模型的多模态理解能力。
技术框架:Youtu-VL的技术框架基于Transformer架构,并采用自回归的方式进行训练。模型接收文本和视觉tokens作为输入,并预测下一个token,可以是文本token或视觉token。关键在于,视觉tokens被直接集成到预测流中,与文本tokens一起进行自回归预测。这种统一的预测方式使得模型能够同时学习文本和视觉信息的表示,并建立它们之间的关联。
关键创新:Youtu-VL最重要的技术创新点在于VLUAS范式,即视觉-语言统一自回归监督。与以往的VLMs不同,Youtu-VL将视觉信息视为与文本信息同等重要的预测目标,从而克服了“文本主导”的优化偏差。这种范式使得模型能够更加充分地利用视觉信息,提升多模态理解能力。此外,该框架还支持以视觉为中心的任务,无需额外的任务特定模块。
关键设计:Youtu-VL的关键设计包括:1) 使用视觉tokenizer将图像转换为视觉tokens;2) 将视觉tokens与文本tokens混合输入到Transformer模型中;3) 使用统一的自回归损失函数,同时监督文本和视觉tokens的预测;4) 通过调整视觉和文本tokens的比例,控制模型对视觉信息的关注程度。具体的网络结构和参数设置可能需要根据具体的任务进行调整。
🖼️ 关键图片
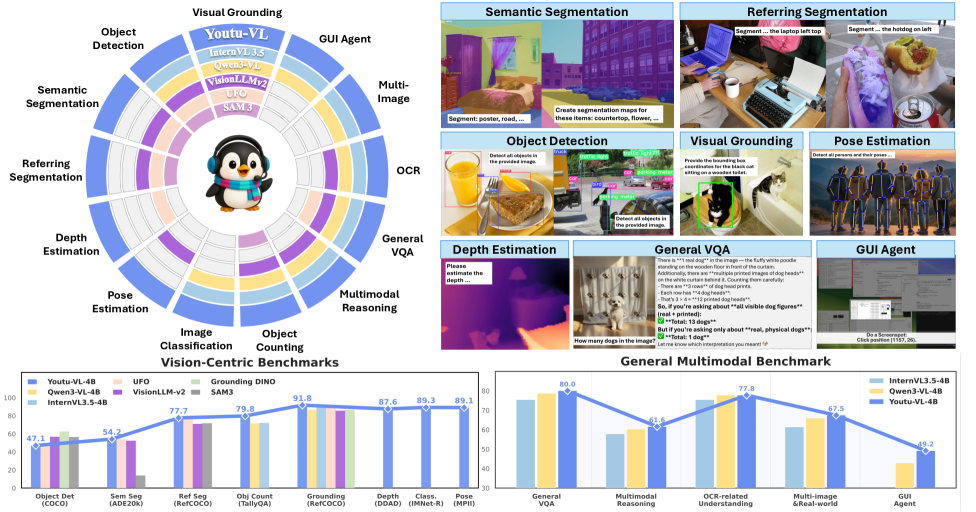


📊 实验亮点
Youtu-VL在通用多模态任务和视觉中心任务上都取得了有竞争力的性能。具体而言,该模型在多个视觉问答数据集上取得了显著的提升,并且在零样本图像分类任务中也表现出色。这些实验结果表明,Youtu-VL能够有效地利用视觉信息,提升多模态理解能力。
🎯 应用场景
Youtu-VL具有广泛的应用前景,包括但不限于:视觉问答、图像描述、视觉推理、机器人导航、自动驾驶等。通过提升模型对细粒度视觉信息的理解能力,Youtu-VL可以应用于需要精确视觉感知的场景,例如医疗影像分析、工业质检等。此外,该研究为开发更强大的通用视觉智能体奠定了基础,有望推动人工智能在各个领域的应用。
📄 摘要(原文)
Despite the significant advancements represented by Vision-Language Models (VLMs), current architectures often exhibit limitations in retaining fine-grained visual information, leading to coarse-grained multimodal comprehension. We attribute this deficiency to a suboptimal training paradigm inherent in prevailing VLMs, which exhibits a text-dominant optimization bias by conceptualizing visual signals merely as passive conditional inputs rather than supervisory targets. To mitigate this, we introduce Youtu-VL, a framework leveraging the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally shifts the optimization objective from
vision-as-input'' tovision-as-target.'' By integrating visual tokens directly into the prediction stream, Youtu-VL applies unified autoregressive supervision to both visual details and linguistic content. Furthermore, we extend this paradigm to encompass vision-centric tasks, enabling a standard VLM to perform vision-centric tasks without task-specific additions. Extensive empirical evaluations demonstrate that Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks, establishing a robust foundation for the development of comprehensive generalist visual agents.