DSVM-UNet : Enhancing VM-UNet with Dual Self-distillation for Medical Image Segmentation
作者: Renrong Shao, Dongyang Li, Dong Xia, Lin Shao, Jiangdong Lu, Fen Zheng, Lulu Zhang
分类: cs.CV
发布日期: 2026-01-27
备注: 5 pages, 1 figures
期刊: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2026)
🔗 代码/项目: GITHUB
💡 一句话要点
DSVM-UNet:通过双重自蒸馏增强VM-UNet,用于医学图像分割
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 医学图像分割 Vision Mamba VM-UNet 双重自蒸馏 自蒸馏 深度学习 特征对齐
📋 核心要点
- 现有医学图像分割模型,特别是基于Vision Mamba的VM-UNet,主要依赖复杂架构设计来提升性能,忽略了训练策略的优化。
- DSVM-UNet通过引入双重自蒸馏方法,在全局和局部层面对齐特征,无需复杂架构即可提升VM-UNet的分割性能。
- 在ISIC2017、ISIC2018和Synapse数据集上的实验表明,DSVM-UNet在保持计算效率的同时,达到了state-of-the-art的分割精度。
📝 摘要(中文)
Vision Mamba模型在各个领域都得到了广泛的研究,它通过以线性时间开销有效管理长程依赖关系,解决了先前模型的局限性。一些前瞻性研究进一步设计了基于UNet的Vision Mamba(VM-UNet)用于医学图像分割。这些方法主要侧重于通过创建更复杂的结构来优化架构设计,以增强模型感知语义特征的能力。在本文中,我们提出了一种简单而有效的方法,通过用于VM-UNet的双重自蒸馏(DSVM-UNet)来改进模型,而无需任何复杂的架构设计。为了实现这一目标,我们开发了双重自蒸馏方法,以对齐全局和局部层面的特征。在ISIC2017、ISIC2018和Synapse基准上进行的大量实验表明,我们的方法在保持计算效率的同时实现了最先进的性能。代码可在https://github.com/RoryShao/DSVM-UNet.git获取。
🔬 方法详解
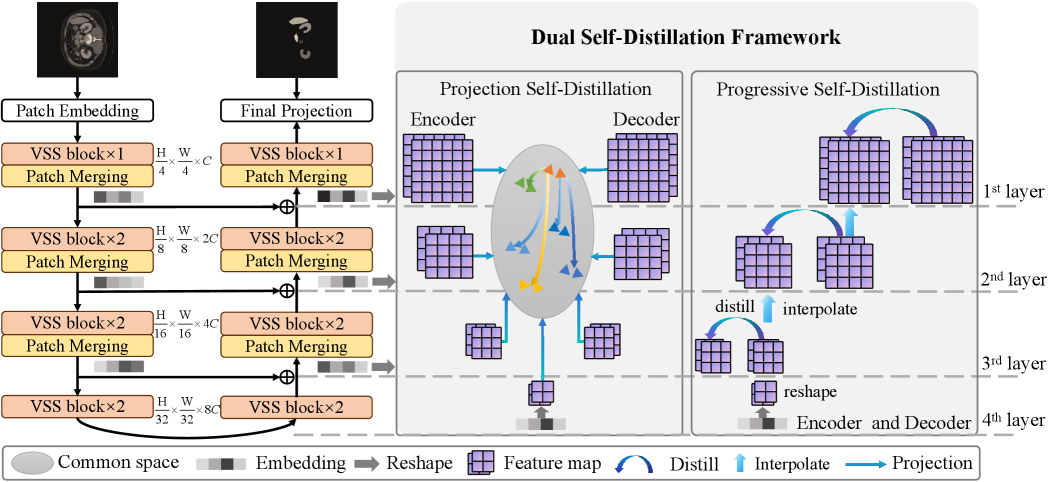
问题定义:医学图像分割任务旨在准确地将图像中的目标区域(如病灶)分割出来。现有的基于Vision Mamba的VM-UNet模型主要通过设计复杂的网络结构来提升性能,但忽略了训练策略的优化,导致模型可能无法充分利用已有的特征信息,泛化能力受限。
核心思路:DSVM-UNet的核心思路是通过双重自蒸馏,让模型自身学习到更鲁棒、更具判别性的特征表示。通过在全局和局部层面进行特征对齐,使得模型能够更好地理解图像的语义信息,从而提升分割精度。这种方法无需修改网络结构,易于实现且计算效率高。
技术框架:DSVM-UNet的整体框架是在VM-UNet的基础上,增加了双重自蒸馏模块。该模块包含两个分支:全局自蒸馏和局部自蒸馏。全局自蒸馏旨在对齐编码器和解码器在全局层面的特征表示,而局部自蒸馏则关注局部区域的特征一致性。这两个分支共同作用,使得模型能够学习到更全面、更精细的特征。
关键创新:DSVM-UNet的关键创新在于提出了双重自蒸馏策略,将自蒸馏的思想扩展到全局和局部两个层面。与传统的自蒸馏方法相比,DSVM-UNet能够更有效地利用模型自身的知识,提升特征表示的质量。此外,该方法无需复杂的架构设计,易于集成到现有的VM-UNet模型中。
关键设计:在全局自蒸馏中,作者使用了均方误差(MSE)损失函数来对齐编码器和解码器的全局特征。在局部自蒸馏中,作者采用了Dice损失函数来衡量局部区域的分割结果。此外,作者还对两个自蒸馏分支的损失权重进行了调整,以平衡全局和局部特征的重要性。具体的网络结构和参数设置与原始的VM-UNet保持一致,只增加了自蒸馏模块。
🖼️ 关键图片
📊 实验亮点
DSVM-UNet在ISIC2017、ISIC2018和Synapse数据集上取得了state-of-the-art的性能。例如,在ISIC2017数据集上,DSVM-UNet的Dice系数达到了显著提升,超过了现有的其他方法。同时,DSVM-UNet保持了较高的计算效率,证明了该方法的有效性和实用性。
🎯 应用场景
DSVM-UNet在医学图像分割领域具有广泛的应用前景,例如皮肤癌病灶分割、器官分割等。该方法能够辅助医生进行诊断,提高诊断效率和准确性。未来,DSVM-UNet可以进一步扩展到其他医学图像分析任务,如疾病诊断、预后预测等,具有重要的临床价值。
📄 摘要(原文)
Vision Mamba models have been extensively researched in various fields, which address the limitations of previous models by effectively managing long-range dependencies with a linear-time overhead. Several prospective studies have further designed Vision Mamba based on UNet(VM-UNet) for medical image segmentation. These approaches primarily focus on optimizing architectural designs by creating more complex structures to enhance the model's ability to perceive semantic features. In this paper, we propose a simple yet effective approach to improve the model by Dual Self-distillation for VM-UNet (DSVM-UNet) without any complex architectural designs. To achieve this goal, we develop double self-distillation methods to align the features at both the global and local levels. Extensive experiments conducted on the ISIC2017, ISIC2018, and Synapse benchmarks demonstrate that our approach achieves state-of-the-art performance while maintaining computational efficiency. Code is available at https://github.com/RoryShao/DSVM-UNet.git.