Towards Governance-Oriented Low-Altitude Intelligence: A Management-Centric Multi-Modal Benchmark With Implicitly Coordinated Vision-Language Reasoning Framework
作者: Hao Chang, Zhihui Wang, Lingxiang Wu, Peijin Wang, Wenhui Diao, Jinqiao Wang
分类: cs.CV
发布日期: 2026-01-27
💡 一句话要点
提出GovLA-10K和GovLA-Reasoner,用于城市治理的低空智能多模态基准与推理框架。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低空视觉 多模态学习 视觉-语言推理 智慧城市 城市治理
📋 核心要点
- 现有方法难以支持城市治理中管理导向的异常理解,缺乏功能性显著目标的针对性设计。
- GovLA-Reasoner通过高效的特征适配器,隐式协调视觉检测器和大型语言模型之间的表示共享,实现视觉定位与语言推理的有效结合。
- 实验表明,该方法在提升性能的同时,避免了对特定任务组件的微调,具有良好的泛化能力。
📝 摘要(中文)
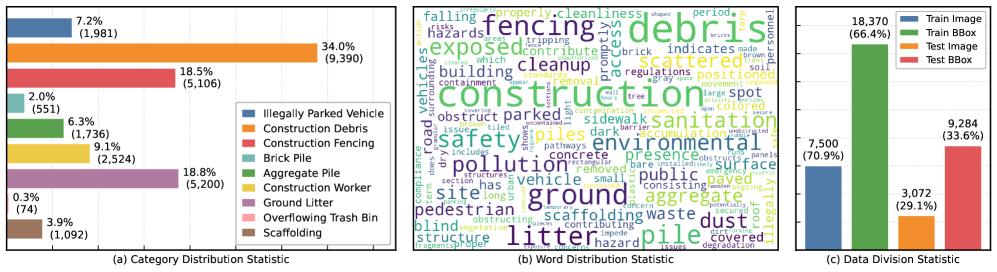
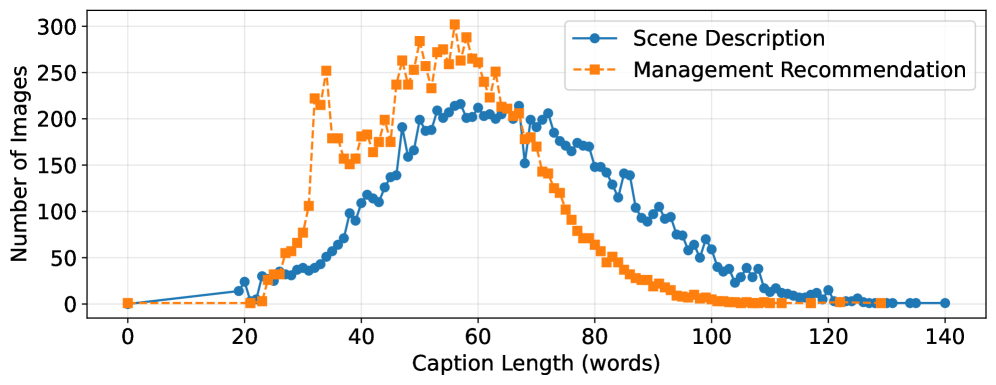
本文提出GovLA-10K,这是一个面向城市治理的低空智能多模态基准数据集,以及GovLA-Reasoner,一个为治理感知的空中感知定制的统一视觉-语言推理框架。与旨在详尽标注所有可见对象的现有研究不同,GovLA-10K围绕与实际管理需求直接对应的功能性显著目标进行设计,并进一步提供基于这些观察结果的可操作的管理建议。为了有效地协调细粒度的视觉定位与高层次的上下文语言推理,GovLA-Reasoner引入了一个高效的特征适配器,该适配器隐式地协调视觉检测器和大型语言模型(LLM)之间具有区分性的表示共享。大量实验表明,该方法显著提高了性能,同时避免了对任何特定于任务的单个组件进行微调的需要。这项工作为未来管理感知的低空视觉-语言系统的研究提供了一个新的视角和基础。
🔬 方法详解
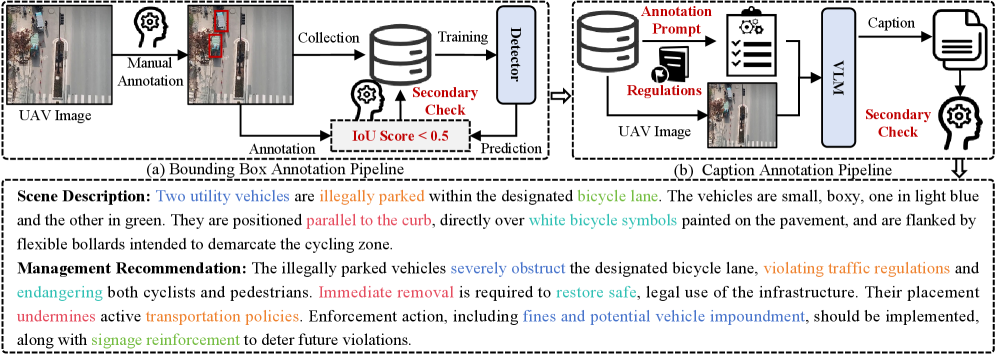
问题定义:现有低空视觉系统和视觉-语言管道难以支持城市治理中管理导向的异常理解。现有方法侧重于详尽地标注所有可见对象,而忽略了与实际管理需求直接相关的关键目标,并且缺乏有效的视觉和语言信息融合机制。
核心思路:论文的核心思路是构建一个面向治理的低空视觉-语言推理框架,该框架能够关注功能性显著目标,并结合视觉信息和上下文语言信息进行推理,从而为城市管理提供可操作的建议。通过隐式地协调视觉和语言特征,避免了对特定任务组件的微调,提高了模型的泛化能力。
技术框架:GovLA-Reasoner框架包含两个主要组成部分:视觉检测器和大型语言模型(LLM)。视觉检测器负责从低空图像中检测功能性显著目标,LLM负责根据检测到的目标和上下文信息进行推理,并生成管理建议。框架的关键在于一个特征适配器,它连接了视觉检测器和LLM,并隐式地协调了它们之间的特征表示。
关键创新:该论文的关键创新在于提出了GovLA-10K数据集和GovLA-Reasoner框架。GovLA-10K数据集是第一个面向城市治理的低空智能多模态基准数据集,它关注与实际管理需求直接相关的目标。GovLA-Reasoner框架通过特征适配器实现了视觉和语言信息的有效融合,避免了对特定任务组件的微调。
关键设计:特征适配器的具体设计未知,但其目标是实现视觉检测器和LLM之间具有区分性的表示共享,从而提高视觉-语言推理的准确性和效率。论文强调避免对任何特定于任务的单个组件进行微调,这表明特征适配器可能采用了一种通用的、可迁移的设计。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GovLA-Reasoner框架在GovLA-10K数据集上取得了显著的性能提升。该方法在避免对任何特定于任务的单个组件进行微调的情况下,仍然能够有效地协调视觉和语言信息,并生成准确的管理建议。具体的性能数据和对比基线未知,但论文强调了该方法在提高性能和泛化能力方面的优势。
🎯 应用场景
该研究成果可应用于智慧城市治理,例如交通违规检测、环境污染监控、非法建筑识别等。通过低空视觉系统自动识别城市中的异常事件,并结合语言推理生成管理建议,可以提高城市管理的效率和智能化水平,为城市居民提供更安全、更便捷的生活环境。未来,该技术还可以扩展到其他领域,如农业、林业等。
📄 摘要(原文)
Low-altitude vision systems are becoming a critical infrastructure for smart city governance. However, existing object-centric perception paradigms and loosely coupled vision-language pipelines are still difficult to support management-oriented anomaly understanding required in real-world urban governance. To bridge this gap, we introduce GovLA-10K, the first management-oriented multi-modal benchmark for low-altitude intelligence, along with GovLA-Reasoner, a unified vision-language reasoning framework tailored for governance-aware aerial perception. Unlike existing studies that aim to exhaustively annotate all visible objects, GovLA-10K is deliberately designed around functionally salient targets that directly correspond to practical management needs, and further provides actionable management suggestions grounded in these observations. To effectively coordinate the fine-grained visual grounding with high-level contextual language reasoning, GovLA-Reasoner introduces an efficient feature adapter that implicitly coordinates discriminative representation sharing between the visual detector and the large language model (LLM). Extensive experiments show that our method significantly improves performance while avoiding the need of fine-tuning for any task-specific individual components. We believe our work offers a new perspective and foundation for future studies on management-aware low-altitude vision-language systems.