Innovator-VL: A Multimodal Large Language Model for Scientific Discovery
作者: Zichen Wen, Boxue Yang, Shuang Chen, Yaojie Zhang, Yuhang Han, Junlong Ke, Cong Wang, Yicheng Fu, Jiawang Zhao, Jiangchao Yao, Xi Fang, Zhen Wang, Henxing Cai, Lin Yao, Zhifeng Gao, Yanhui Hong, Nang Yuan, Yixuan Li, Guojiang Zhao, Haoyi Tao, Nan Wang, Han Lyu, Guolin Ke, Ning Liao, Xiaoxing Wang, Kai Chen, Zhiyu Li, Feiyu Xiong, Sihan Hu, Kun Chen, Yanfeng Wang, Weinan E, Linfeng Zhang, Linfeng Zhang
分类: cs.CV, cs.AI
发布日期: 2026-01-27
备注: Innovator-VL tech report
💡 一句话要点
提出 Innovator-VL,一种用于科学发现的多模态大语言模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 科学发现 数据效率 透明训练 科学智能
📋 核心要点
- 现有科学多模态模型依赖大规模领域预训练和复杂流程,透明性和数据效率有待提升。
- Innovator-VL 采用有原则的训练设计和透明方法,在减少数据需求的同时提升科学智能。
- 实验表明,Innovator-VL 在科学任务和通用视觉任务上均表现出竞争力的性能和泛化能力。
📝 摘要(中文)
我们提出了 Innovator-VL,一种科学多模态大语言模型,旨在提升对不同科学领域的理解和推理能力,同时保持在通用视觉任务上的卓越性能。与依赖大规模领域特定预训练和不透明流程的趋势相反,我们的工作表明,有原则的训练设计和透明的方法论可以通过大幅减少数据需求来产生强大的科学智能。(i) 首先,我们提供了一个完全透明、端到端可复现的训练流程,涵盖数据收集、清洗、预处理、监督微调、强化学习和评估,以及详细的优化方案。这有助于社区进行系统扩展。(ii) 其次,Innovator-VL 表现出卓越的数据效率,使用少于五百万个精心策划的样本,在各种科学任务上实现了具有竞争力的性能,而无需大规模预训练。这些结果表明,有效的推理可以通过有原则的数据选择来实现,而不是不加选择地扩展。(iii) 第三,Innovator-VL 表现出强大的泛化能力,在通用视觉、多模态推理和科学基准上实现了具有竞争力的性能。这表明科学对齐可以集成到一个统一的模型中,而不会影响通用能力。我们的实践表明,即使没有大规模数据,也可以构建高效、可复现和高性能的科学多模态模型,为未来的研究提供了一个实践基础。
🔬 方法详解
问题定义:现有科学多模态模型通常需要大规模的领域特定预训练数据,训练流程复杂且不透明,难以复现和扩展。这些模型在数据效率和泛化能力方面也存在局限性,难以在资源有限的情况下进行有效的研究和应用。
核心思路:Innovator-VL 的核心思路是通过有原则的数据选择和透明的训练流程,在不依赖大规模预训练的情况下,实现高效且具有竞争力的科学智能。该方法强调数据质量而非数据量,并通过清晰的流程设计促进模型的复现和扩展。
技术框架:Innovator-VL 的训练流程包括数据收集、清洗、预处理、监督微调、强化学习和评估等阶段。该流程是端到端可复现的,并提供了详细的优化方案。模型架构基于大型语言模型,并集成了视觉编码器以处理多模态输入。
关键创新:Innovator-VL 的关键创新在于其数据效率和透明性。通过精心策划的数据集,模型在少量数据上实现了与大规模预训练模型相当的性能。同时,透明的训练流程和详细的优化方案使得模型易于复现和扩展。
关键设计:Innovator-VL 的关键设计包括:(1) 精心策划的科学数据集,包含各种科学领域的知识和任务;(2) 透明的训练流程,包括详细的数据预处理和模型优化步骤;(3) 基于大型语言模型的架构,具有强大的语言理解和生成能力;(4) 强化学习的应用,用于提升模型的推理能力和泛化能力。
🖼️ 关键图片

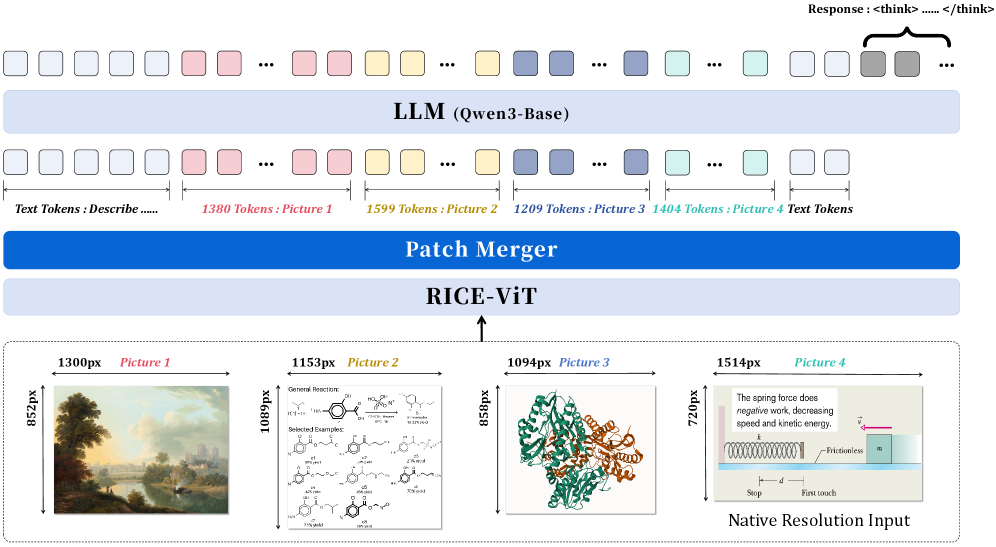

📊 实验亮点
Innovator-VL 在各种科学任务上实现了具有竞争力的性能,使用少于五百万个精心策划的样本,而无需大规模预训练。在通用视觉、多模态推理和科学基准上,Innovator-VL 也表现出强大的泛化能力,证明了科学对齐可以集成到一个统一的模型中,而不会影响通用能力。
🎯 应用场景
Innovator-VL 可应用于各种科学领域,例如材料科学、生物学和化学,辅助科研人员进行数据分析、假设生成和实验设计。该模型还可用于教育领域,帮助学生理解复杂的科学概念。未来,Innovator-VL 有望成为科研人员的重要工具,加速科学发现的进程。
📄 摘要(原文)
We present Innovator-VL, a scientific multimodal large language model designed to advance understanding and reasoning across diverse scientific domains while maintaining excellent performance on general vision tasks. Contrary to the trend of relying on massive domain-specific pretraining and opaque pipelines, our work demonstrates that principled training design and transparent methodology can yield strong scientific intelligence with substantially reduced data requirements. (i) First, we provide a fully transparent, end-to-end reproducible training pipeline, covering data collection, cleaning, preprocessing, supervised fine-tuning, reinforcement learning, and evaluation, along with detailed optimization recipes. This facilitates systematic extension by the community. (ii) Second, Innovator-VL exhibits remarkable data efficiency, achieving competitive performance on various scientific tasks using fewer than five million curated samples without large-scale pretraining. These results highlight that effective reasoning can be achieved through principled data selection rather than indiscriminate scaling. (iii) Third, Innovator-VL demonstrates strong generalization, achieving competitive performance on general vision, multimodal reasoning, and scientific benchmarks. This indicates that scientific alignment can be integrated into a unified model without compromising general-purpose capabilities. Our practices suggest that efficient, reproducible, and high-performing scientific multimodal models can be built even without large-scale data, providing a practical foundation for future research.