Instance-Guided Radar Depth Estimation for 3D Object Detection
作者: Chen-Chou Lo, Patrick Vandewalle
分类: cs.CV, cs.AI
发布日期: 2026-01-27
备注: Accepted to IPMV2026
💡 一句话要点
提出InstaRadar,通过实例分割引导的雷达深度估计,提升单目3D目标检测性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 雷达深度估计 3D目标检测 雷达相机融合 实例分割 自动驾驶
📋 核心要点
- 单目相机3D检测易受深度歧义影响,且在恶劣环境下鲁棒性较差,而雷达数据虽然具有优势,但其稀疏性和低分辨率限制了直接应用。
- 论文提出InstaRadar,利用实例分割信息引导雷达数据增强,提升雷达数据的密度和语义对齐,从而生成高质量的深度特征。
- 实验结果表明,InstaRadar能够有效提升雷达引导的深度估计性能,并最终提高BEVDepth框架下的3D目标检测精度。
📝 摘要(中文)
精确的深度估计是自动驾驶中3D感知的基础,支持检测、跟踪和运动规划等任务。然而,基于单目相机的3D检测存在深度模糊和在恶劣条件下鲁棒性降低的问题。雷达提供了互补的优势,例如对弱光和恶劣天气的抵抗能力,但其稀疏性和低分辨率限制了其在检测框架中的直接使用。这促使人们需要有效的雷达-相机融合,并改进预处理和深度估计策略。我们提出了一个端到端框架,通过两个关键组件来增强单目3D目标检测。首先,我们引入了InstaRadar,一种实例分割引导的扩展方法,它利用预训练的分割掩码来增强雷达密度和语义对齐,产生更结构化的表示。InstaRadar在雷达引导的深度估计中取得了最先进的结果,表明了其在生成高质量深度特征方面的有效性。其次,我们将预训练的RCDPT集成到BEVDepth框架中,作为其深度模块的替代品。通过InstaRadar增强的输入,RCDPT集成始终如一地提高了3D检测性能。总的来说,这些组件比基线BEVDepth模型产生了稳定的增益,证明了InstaRadar的有效性和显式深度监督在3D目标检测中的优势。虽然该框架落后于直接提取BEV特征的雷达-相机融合模型,因为雷达仅作为指导而不是独立的特征流,但这种限制突出了改进的潜力。未来的工作将把InstaRadar扩展到类似点云的表示,并集成一个专用的雷达分支,利用时间线索来增强BEV融合。
🔬 方法详解
问题定义:论文旨在解决单目3D目标检测中深度估计不准确的问题,尤其是在恶劣天气和光照条件下。现有方法依赖相机图像,容易受到环境因素干扰。雷达数据虽然对环境不敏感,但其稀疏性和低分辨率使其难以直接用于深度估计,导致3D目标检测性能受限。
核心思路:论文的核心思路是利用实例分割信息来引导雷达数据的增强,从而提高雷达数据的质量和可用性。通过将图像的语义信息(实例分割结果)与雷达数据融合,可以有效地提升雷达数据的密度和语义对齐,生成更准确的深度特征。
技术框架:整体框架包含两个主要模块:InstaRadar和RCDPT集成。首先,InstaRadar模块利用预训练的实例分割模型生成分割掩码,然后利用这些掩码来扩展雷达数据,提高其密度和语义一致性。其次,将InstaRadar增强后的雷达数据输入到RCDPT模型中进行深度估计,最后将估计的深度信息集成到BEVDepth框架中进行3D目标检测。
关键创新:论文的关键创新在于InstaRadar模块,它提出了一种实例分割引导的雷达数据增强方法。与传统的雷达数据处理方法不同,InstaRadar充分利用了图像的语义信息,从而能够更有效地提升雷达数据的质量。这种方法能够生成更准确、更可靠的深度特征,从而提高3D目标检测的性能。
关键设计:InstaRadar的关键设计在于如何利用实例分割掩码来扩展雷达数据。具体来说,论文可能采用了以下技术细节:1) 将雷达点云投影到图像平面上;2) 利用实例分割掩码确定每个雷达点所属的物体实例;3) 基于实例分割信息,对雷达点进行插值或扩展,以提高雷达数据的密度;4) 设计损失函数,鼓励雷达数据与实例分割结果保持一致。
🖼️ 关键图片


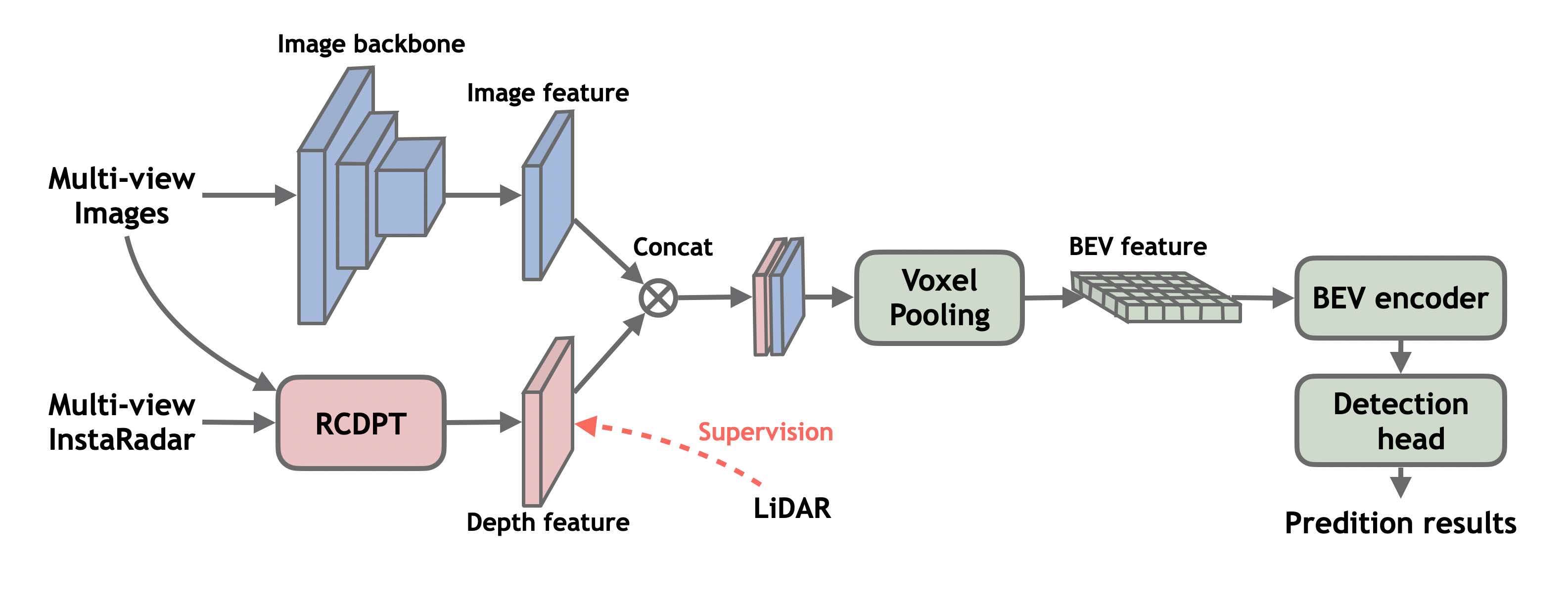
📊 实验亮点
InstaRadar在雷达引导的深度估计中取得了state-of-the-art的结果,证明了其在生成高质量深度特征方面的有效性。通过将InstaRadar与RCDPT集成到BEVDepth框架中,3D目标检测性能得到了持续提升,验证了显式深度监督在3D目标检测中的优势。虽然该框架在性能上略逊于直接提取BEV特征的雷达-相机融合模型,但为未来的改进方向提供了明确的指导。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、智能交通等领域。通过提高在复杂环境下的3D感知能力,可以提升自动驾驶车辆的安全性、可靠性和适应性。此外,该技术还可以应用于机器人导航,帮助机器人在未知环境中进行自主定位和路径规划。在智能交通领域,该技术可以用于交通监控、车辆跟踪和事故预警等应用。
📄 摘要(原文)
Accurate depth estimation is fundamental to 3D perception in autonomous driving, supporting tasks such as detection, tracking, and motion planning. However, monocular camera-based 3D detection suffers from depth ambiguity and reduced robustness under challenging conditions. Radar provides complementary advantages such as resilience to poor lighting and adverse weather, but its sparsity and low resolution limit its direct use in detection frameworks. This motivates the need for effective Radar-camera fusion with improved preprocessing and depth estimation strategies. We propose an end-to-end framework that enhances monocular 3D object detection through two key components. First, we introduce InstaRadar, an instance segmentation-guided expansion method that leverages pre-trained segmentation masks to enhance Radar density and semantic alignment, producing a more structured representation. InstaRadar achieves state-of-the-art results in Radar-guided depth estimation, showing its effectiveness in generating high-quality depth features. Second, we integrate the pre-trained RCDPT into the BEVDepth framework as a replacement for its depth module. With InstaRadar-enhanced inputs, the RCDPT integration consistently improves 3D detection performance. Overall, these components yield steady gains over the baseline BEVDepth model, demonstrating the effectiveness of InstaRadar and the advantage of explicit depth supervision in 3D object detection. Although the framework lags behind Radar-camera fusion models that directly extract BEV features, since Radar serves only as guidance rather than an independent feature stream, this limitation highlights potential for improvement. Future work will extend InstaRadar to point cloud-like representations and integrate a dedicated Radar branch with temporal cues for enhanced BEV fusion.