TIGaussian: Disentangle Gaussians for Spatial-Awared Text-Image-3D Alignment
作者: Jiarun Liu, Qifeng Chen, Yiru Zhao, Minghua Liu, Baorui Ma, Sheng Yang
分类: cs.CV
发布日期: 2026-01-27
💡 一句话要点
TIGaussian:解耦高斯分布以实现空间感知的文本-图像-3D对齐
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D高斯溅射 跨模态对齐 视觉语言模型 多模态融合 特征解耦
📋 核心要点
- 现有方法在提取有效的3D模态特征以及弥合文本、图像和3D数据之间的模态差距方面存在挑战。
- TIGaussian通过解耦3D高斯溅射的内在属性,并设计双向跨模态对齐策略,来增强跨模态对齐。
- 实验结果表明,TIGaussian在跨模态检索、零样本分类和场景识别等多个任务中取得了最先进的性能。
📝 摘要(中文)
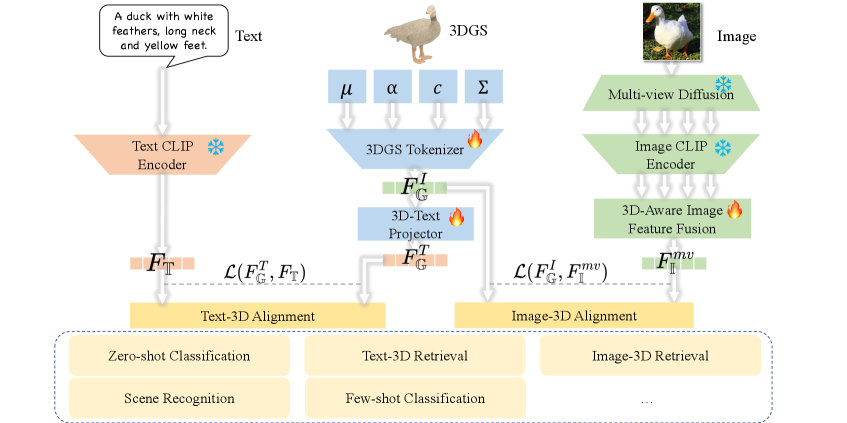
视觉语言模型已经深刻地连接了文本和图像之间的特征。而3D模态数据(如点云和3D高斯分布)的加入,进一步实现了3D相关任务的预训练,例如跨模态检索、零样本分类和场景识别。由于提取3D模态特征和弥合不同模态之间的差距仍然存在挑战,我们提出了TIGaussian,一个利用3D高斯溅射(3DGS)特性的框架,通过多分支3DGS tokenizer和模态特定的3D特征对齐策略来加强跨模态对齐。具体来说,我们的多分支3DGS tokenizer将3DGS结构的内在属性解耦为紧凑的潜在表示,从而实现更具泛化性的特征提取。为了进一步弥合模态差距,我们开发了一种双向跨模态对齐策略:一种利用扩散先验的多视角特征融合机制,以解决图像-3D对齐中的透视歧义;以及一个文本-3D投影模块,自适应地将3D特征映射到文本嵌入空间,以实现更好的文本-3D对齐。在各种数据集上的大量实验表明,TIGaussian在多个任务中都达到了最先进的性能。
🔬 方法详解
问题定义:论文旨在解决视觉语言模型在处理3D模态数据时,特征提取困难以及跨模态对齐效果不佳的问题。现有方法难以有效提取3D特征,并且无法很好地弥合文本、图像和3D数据之间的模态差距,导致在跨模态检索、零样本分类等任务中表现不佳。
核心思路:论文的核心思路是利用3D高斯溅射(3DGS)的特性,通过解耦3DGS结构的内在属性,并设计双向跨模态对齐策略,来增强跨模态对齐。通过多分支3DGS tokenizer提取更具泛化性的3D特征,并利用多视角特征融合和文本-3D投影模块来弥合模态差距。
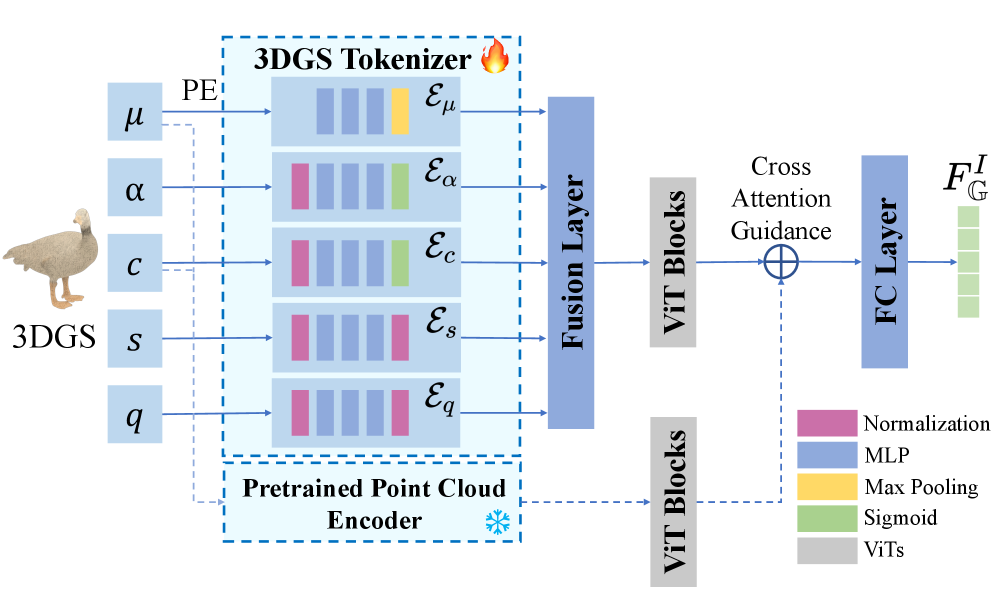
技术框架:TIGaussian框架主要包含以下几个模块:1) 多分支3DGS tokenizer:用于解耦3DGS结构的内在属性,提取紧凑的潜在表示。2) 多视角特征融合机制:利用扩散先验解决图像-3D对齐中的透视歧义。3) 文本-3D投影模块:自适应地将3D特征映射到文本嵌入空间。整体流程是,首先使用多分支3DGS tokenizer提取3D特征,然后通过多视角特征融合和文本-3D投影模块进行跨模态对齐。
关键创新:论文的关键创新点在于:1) 提出了多分支3DGS tokenizer,能够解耦3DGS结构的内在属性,提取更具泛化性的3D特征。2) 设计了双向跨模态对齐策略,包括多视角特征融合和文本-3D投影模块,能够有效弥合模态差距。与现有方法相比,TIGaussian能够更好地提取3D特征,并实现更准确的跨模态对齐。
关键设计:多分支3DGS tokenizer的具体实现细节未知,但其核心思想是将3DGS结构的内在属性(例如位置、颜色、不透明度等)解耦为独立的潜在表示。多视角特征融合机制利用扩散先验来指导特征融合,具体实现细节未知。文本-3D投影模块通过自适应的方式将3D特征映射到文本嵌入空间,具体实现细节未知。
🖼️ 关键图片
📊 实验亮点
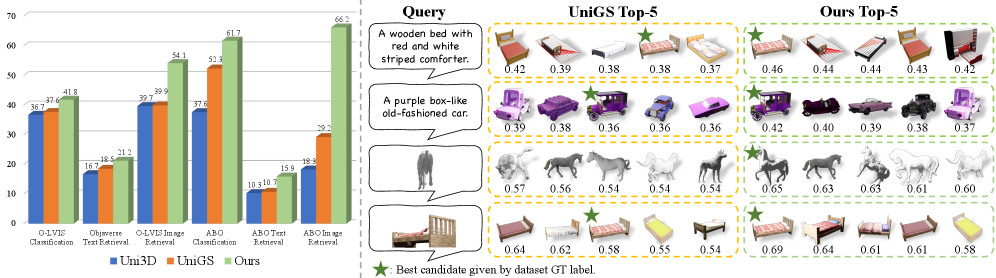
TIGaussian在多个数据集上进行了实验,并在跨模态检索、零样本分类和场景识别等任务中取得了最先进的性能。具体的性能数据和提升幅度在论文中给出,表明TIGaussian能够有效提取3D特征,并实现更准确的跨模态对齐,显著优于现有方法。
🎯 应用场景
TIGaussian具有广泛的应用前景,包括跨模态检索、零样本分类、场景识别、3D内容生成和编辑等。该研究可以促进视觉语言模型在3D领域的应用,并为开发更智能的3D感知系统提供技术支持。未来,该方法可以应用于机器人导航、自动驾驶、虚拟现实等领域。
📄 摘要(原文)
While visual-language models have profoundly linked features between texts and images, the incorporation of 3D modality data, such as point clouds and 3D Gaussians, further enables pretraining for 3D-related tasks, e.g., cross-modal retrieval, zero-shot classification, and scene recognition. As challenges remain in extracting 3D modal features and bridging the gap between different modalities, we propose TIGaussian, a framework that harnesses 3D Gaussian Splatting (3DGS) characteristics to strengthen cross-modality alignment through multi-branch 3DGS tokenizer and modality-specific 3D feature alignment strategies. Specifically, our multi-branch 3DGS tokenizer decouples the intrinsic properties of 3DGS structures into compact latent representations, enabling more generalizable feature extraction. To further bridge the modality gap, we develop a bidirectional cross-modal alignment strategies: a multi-view feature fusion mechanism that leverages diffusion priors to resolve perspective ambiguity in image-3D alignment, while a text-3D projection module adaptively maps 3D features to text embedding space for better text-3D alignment. Extensive experiments on various datasets demonstrate the state-of-the-art performance of TIGaussian in multiple tasks.