m2sv: A Scalable Benchmark for Map-to-Street-View Spatial Reasoning
作者: Yosub Shin, Michael Buriek, Igor Molybog
分类: cs.CV, cs.AI
发布日期: 2026-01-27
💡 一句话要点
提出m2sv基准测试,用于评估视觉-语言模型在地图到街景空间推理中的能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 空间推理 视觉-语言模型 基准测试 地图到街景 几何对齐 多模态学习 自动驾驶
📋 核心要点
- 现有视觉-语言模型在空间推理任务中,尤其是在对齐抽象地图和街景图像时,表现出明显的不足。
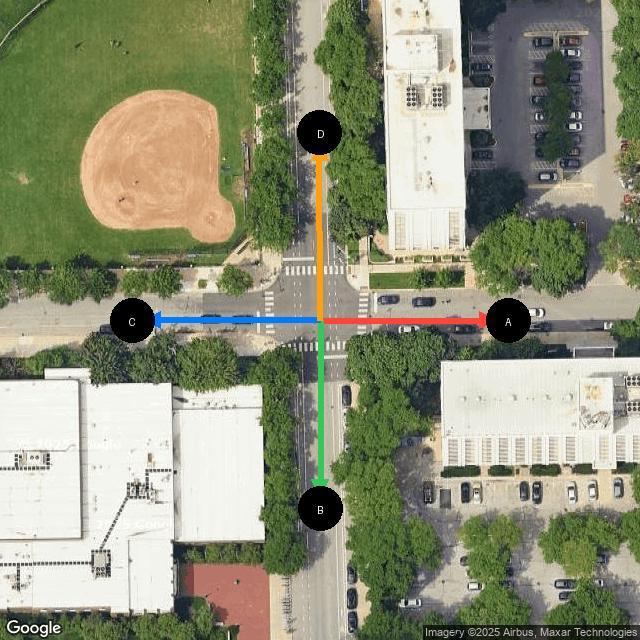
- 论文提出了m2sv基准测试,旨在评估模型通过地图和街景图像推断相机视角方向的空间推理能力。
- 实验结果表明,现有最佳VLM在m2sv上的准确率远低于人类水平,揭示了几何对齐等方面的差距。
📝 摘要(中文)
视觉-语言模型(VLMs)在许多多模态基准测试中表现出色,但在需要将抽象的俯视表示与自我中心视角对齐的空间推理任务中仍然脆弱。我们引入了m2sv,这是一个可扩展的地图到街景空间推理基准,要求模型通过将北向上的俯视地图与在同一真实世界交叉口捕获的街景图像对齐来推断相机视角方向。我们发布了m2sv-20k,一个具有地理多样性和受控歧义的基准,以及m2sv-sft-11k,一个用于监督微调的结构化推理轨迹的精选集合。尽管在现有的多模态基准测试中表现出色,但最佳评估的VLM在m2sv上的准确率仅为65.2%,远低于95%的人类基线。虽然监督微调和强化学习产生了持续的收益,但跨基准评估显示迁移能力有限。除了总体准确性之外,我们还使用结构信号和人类努力系统地分析了地图到街景推理的难度,并对改编的开放模型进行了广泛的失败分析。我们的发现突出了几何对齐、证据聚合和推理一致性方面的持续差距,从而激发了未来在跨视点的基础空间推理方面的工作。
🔬 方法详解
问题定义:论文旨在解决视觉-语言模型在地图到街景空间推理任务中的不足。现有方法难以有效对齐抽象的俯视地图和自我中心的街景图像,导致空间推理性能下降。痛点在于模型缺乏对几何关系的理解、证据聚合能力和推理一致性。
核心思路:论文的核心思路是构建一个具有挑战性的基准测试,迫使模型学习从地图到街景图像的空间对应关系。通过评估模型在推断相机视角方向上的准确性,来衡量其空间推理能力。基准测试的设计考虑了地理多样性和受控歧义,以增加任务的难度。
技术框架:该研究的核心是构建了名为m2sv的基准测试。该基准包含两个部分:m2sv-20k,一个具有地理多样性的基准数据集;m2sv-sft-11k,一个用于监督微调的结构化推理轨迹数据集。研究人员使用现有的视觉-语言模型在m2sv上进行评估,并分析模型的失败案例。
关键创新:该研究的关键创新在于提出了一个专门用于评估地图到街景空间推理能力的基准测试。与现有通用多模态基准测试相比,m2sv更侧重于几何对齐和空间推理,能够更有效地揭示模型在这方面的不足。同时,该研究还提供了结构化的推理轨迹,用于监督微调,以提高模型的性能。
关键设计:m2sv-20k数据集包含20000个样本,覆盖了地理上多样化的位置,并控制了歧义性,以确保任务的难度。m2sv-sft-11k数据集包含11000个结构化的推理轨迹,用于监督微调。研究人员使用了准确率作为评估指标,并分析了模型的失败案例,以了解模型在哪些方面存在不足。
🖼️ 关键图片

📊 实验亮点
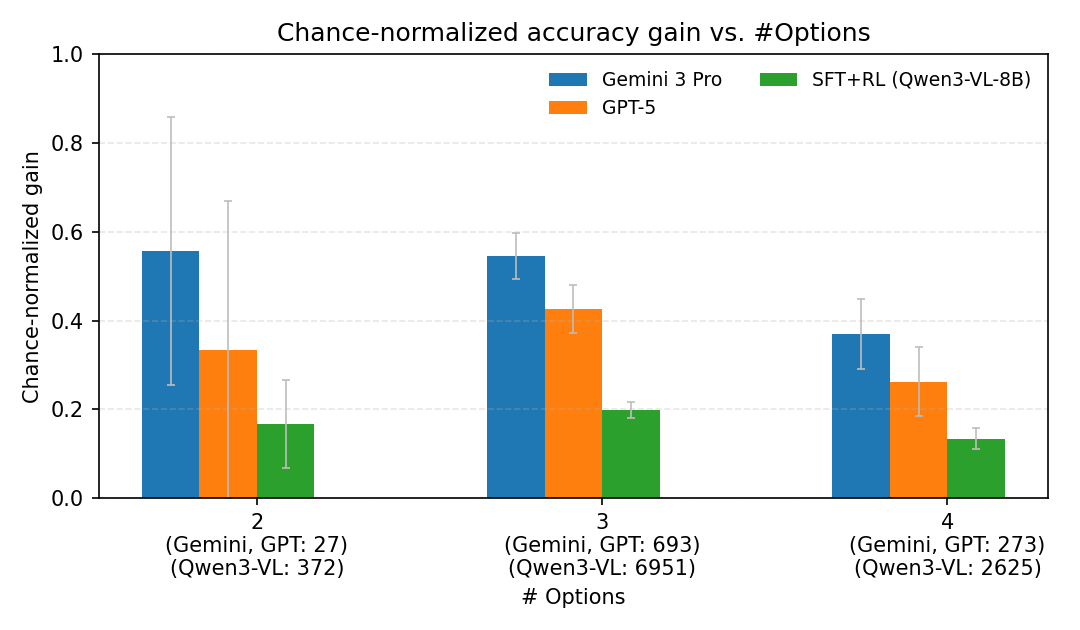
实验结果表明,现有最佳VLM在m2sv上的准确率仅为65.2%,远低于人类的95%水平,表明现有模型在地图到街景空间推理方面存在显著差距。监督微调和强化学习可以带来性能提升,但跨基准评估显示迁移能力有限,说明该任务具有一定的挑战性。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、增强现实等领域。通过提高模型在地图到街景空间推理方面的能力,可以提升自动驾驶车辆的定位精度和导航能力,帮助机器人在复杂环境中进行自主导航,并为增强现实应用提供更准确的场景理解。
📄 摘要(原文)
Vision--language models (VLMs) achieve strong performance on many multimodal benchmarks but remain brittle on spatial reasoning tasks that require aligning abstract overhead representations with egocentric views. We introduce m2sv, a scalable benchmark for map-to-street-view spatial reasoning that asks models to infer camera viewing direction by aligning a north-up overhead map with a Street View image captured at the same real-world intersection. We release m2sv-20k, a geographically diverse benchmark with controlled ambiguity, along with m2sv-sft-11k, a curated set of structured reasoning traces for supervised fine-tuning. Despite strong performance on existing multimodal benchmarks, the best evaluated VLM achieves only 65.2% accuracy on m2sv, far below the human baseline of 95%. While supervised fine-tuning and reinforcement learning yield consistent gains, cross-benchmark evaluations reveal limited transfer. Beyond aggregate accuracy, we systematically analyze difficulty in map-to-street-view reasoning using both structural signals and human effort, and conduct an extensive failure analysis of adapted open models. Our findings highlight persistent gaps in geometric alignment, evidence aggregation, and reasoning consistency, motivating future work on grounded spatial reasoning across viewpoints.