Splat-Portrait: Generalizing Talking Heads with Gaussian Splatting
作者: Tong Shi, Melonie de Almeida, Daniela Ivanova, Nicolas Pugeault, Paul Henderson
分类: cs.CV
发布日期: 2026-01-26
🔗 代码/项目: GITHUB
💡 一句话要点
Splat-Portrait:基于高斯溅射的通用说话人头部生成方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱四:生成式动作 (Generative Motion)
关键词: 说话人头部生成 高斯溅射 3D重建 唇部运动合成 无监督学习
📋 核心要点
- 现有3D说话人头部生成方法依赖于特定领域的启发式方法,如基于warping的面部运动表示先验,导致3D头像重建不准确,影响动画真实感。
- Splat-Portrait的核心思想是利用高斯溅射表示3D头部,并学习将单张人像解耦为静态3D重建和动态唇部运动,无需任何运动先验。
- 实验结果表明,Splat-Portrait在说话人头部生成和新视角合成方面优于现有方法,显著提升了生成视频的视觉质量。
📝 摘要(中文)
本文提出了一种基于高斯溅射(Gaussian Splatting)的说话人头部生成方法Splat-Portrait,旨在解决现有方法在3D头部重建和唇动合成方面的挑战。该方法能够自动将单张人像图像分解为静态的3D高斯溅射表示和预测的2D背景。在没有任何运动先验的条件下,Splat-Portrait能够根据输入的音频生成自然的唇部运动。训练过程仅依赖于2D重建和score-distillation损失,无需3D监督或landmark信息。实验结果表明,Splat-Portrait在说话人头部生成和新视角合成方面表现出优越的性能,与现有方法相比,实现了更好的视觉质量。
🔬 方法详解
问题定义:现有说话人头部生成方法依赖于 warping 等先验知识来驱动面部运动,但这些方法通常会导致不准确的 3D 头像重建,进而影响生成动画的真实感。因此,如何摆脱对特定领域先验的依赖,实现更准确、更真实的 3D 说话人头部生成是一个关键问题。
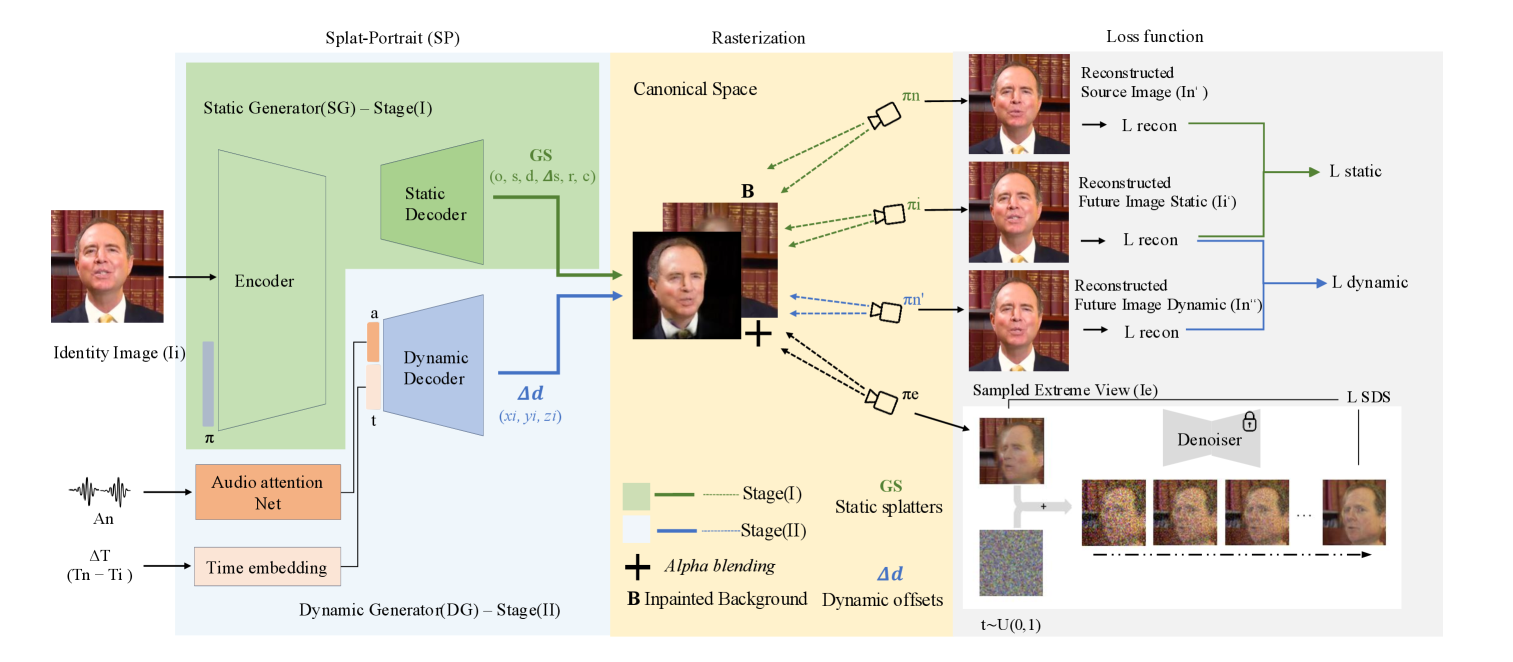
核心思路:Splat-Portrait 的核心思路是利用高斯溅射(Gaussian Splatting)来表示 3D 头部,并学习将单张人像图像解耦为静态的 3D 重建和动态的唇部运动。通过这种方式,模型可以更灵活地学习面部表情和唇部运动,而无需依赖于预定义的运动模型或先验知识。这种解耦表示使得模型能够更好地捕捉面部细节和个性化特征。
技术框架:Splat-Portrait 的整体框架包含以下几个主要模块:1) 图像解耦模块:将单张人像图像分解为静态的 3D 高斯溅射表示和 2D 背景。2) 音频驱动的唇部运动生成模块:根据输入的音频生成自然的唇部运动。3) 渲染模块:将 3D 高斯溅射表示和生成的唇部运动渲染成最终的说话人头部视频。整个训练过程仅依赖于 2D 重建损失和 score-distillation 损失,无需 3D 监督或 landmark 信息。
关键创新:Splat-Portrait 最重要的技术创新点在于其基于高斯溅射的 3D 头部表示和无运动先验的唇部运动生成方法。与现有方法相比,Splat-Portrait 能够更准确地重建 3D 头部,并生成更自然的唇部运动,从而显著提升了生成视频的视觉质量。此外,该方法无需 3D 监督或 landmark 信息,降低了对训练数据的要求。
关键设计:Splat-Portrait 的关键设计包括:1) 使用高斯溅射来表示 3D 头部,能够更灵活地捕捉面部细节和个性化特征。2) 采用 2D 重建损失和 score-distillation 损失来驱动训练,无需 3D 监督或 landmark 信息。3) 设计了一个音频驱动的唇部运动生成模块,能够根据输入的音频生成自然的唇部运动。具体的网络结构和参数设置在论文中有详细描述,但未在此处明确给出。
🖼️ 关键图片


📊 实验亮点
Splat-Portrait 在说话人头部生成和新视角合成任务上取得了显著的性能提升。实验结果表明,与现有方法相比,Splat-Portrait 能够生成更逼真、更自然的说话人头部视频,在视觉质量方面有明显优势。具体的性能指标和对比结果可以在论文中找到,但摘要中未提供量化数据。
🎯 应用场景
Splat-Portrait 在虚拟形象生成、视频会议、娱乐内容创作等领域具有广泛的应用前景。它可以用于创建高度逼真的虚拟化身,提升视频会议的沉浸感,并为电影、游戏等娱乐内容创作提供更灵活、更高效的工具。该研究的成果有助于推动数字人技术的发展,并为人们带来更丰富的数字体验。
📄 摘要(原文)
Talking Head Generation aims at synthesizing natural-looking talking videos from speech and a single portrait image. Previous 3D talking head generation methods have relied on domain-specific heuristics such as warping-based facial motion representation priors to animate talking motions, yet still produce inaccurate 3D avatar reconstructions, thus undermining the realism of generated animations. We introduce Splat-Portrait, a Gaussian-splatting-based method that addresses the challenges of 3D head reconstruction and lip motion synthesis. Our approach automatically learns to disentangle a single portrait image into a static 3D reconstruction represented as static Gaussian Splatting, and a predicted whole-image 2D background. It then generates natural lip motion conditioned on input audio, without any motion driven priors. Training is driven purely by 2D reconstruction and score-distillation losses, without 3D supervision nor landmarks. Experimental results demonstrate that Splat-Portrait exhibits superior performance on talking head generation and novel view synthesis, achieving better visual quality compared to previous works. Our project code and supplementary documents are public available at https://github.com/stonewalking/Splat-portrait.