Multimodal Privacy-Preserving Entity Resolution with Fully Homomorphic Encryption
作者: Susim Roy, Nalini Ratha
分类: cs.CR, cs.CV
发布日期: 2026-01-26
备注: 5 pages, 3 figures, IEEE ICASSP'26
💡 一句话要点
提出基于全同态加密的多模态隐私保护实体识别框架,解决高合规性行业数据异构难题。
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 实体识别 隐私保护 全同态加密 多模态融合 数据安全
📋 核心要点
- 高合规性行业中,由于数据异构性,安全地进行实体识别面临挑战,现有方法难以兼顾数据量、匹配精度和隐私保护。
- 论文提出一种多模态框架,利用全同态加密技术,在不暴露原始数据的情况下进行实体匹配,从而保护个人身份信息的隐私。
- 该方法在保证计算可行性的前提下,实现了较低的等错误率,为机构在满足严格监管要求的同时进行实体识别提供了有效方案。
📝 摘要(中文)
本文提出了一种新颖的多模态框架,用于解决高合规性行业中实体识别的经典挑战。在这些行业中,安全身份协调经常因个人标识符中的句法变异等显著数据异构性而变得复杂。该框架适用于政府和金融机构典型的大量数据集,旨在应对数据量、匹配保真度和隐私这三重挑战。该方法确保个人身份信息的底层明文在整个匹配生命周期中保持计算不可访问,使机构能够通过密码学方式保证客户机密性,从而严格满足监管要求,同时实现可证明的低等错误率,并在大规模下保持计算上的可行性。
🔬 方法详解
问题定义:论文旨在解决高合规性行业中,由于数据量大、数据异构性强(例如个人标识符的句法变异)等因素导致的实体识别难题。现有方法通常难以在保证匹配精度的同时,满足严格的隐私保护要求,尤其是在处理包含大量个人身份信息的数据时。直接进行明文匹配会暴露敏感信息,而传统的隐私保护技术可能无法有效应对复杂的数据异构性,或者在大规模数据集上计算效率低下。
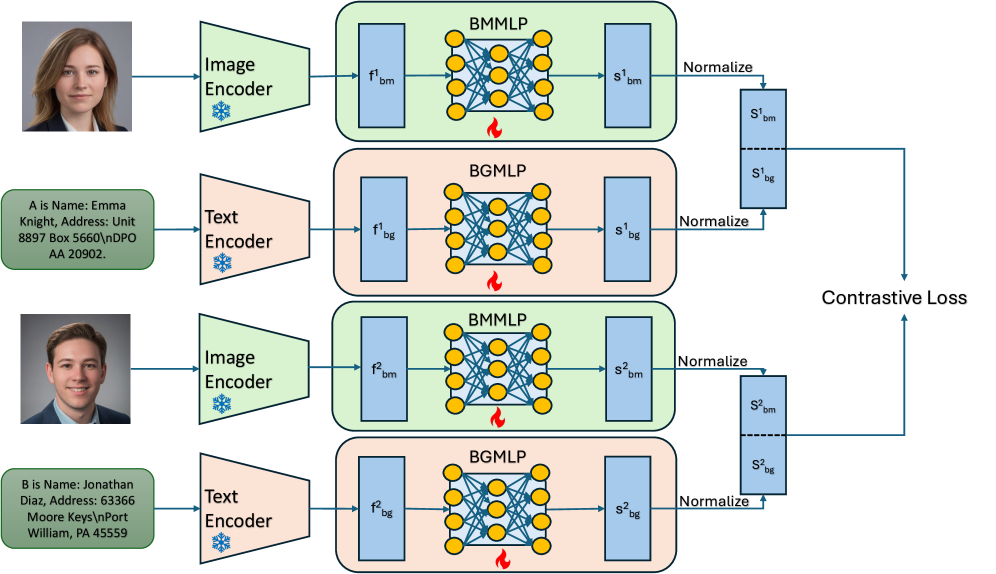
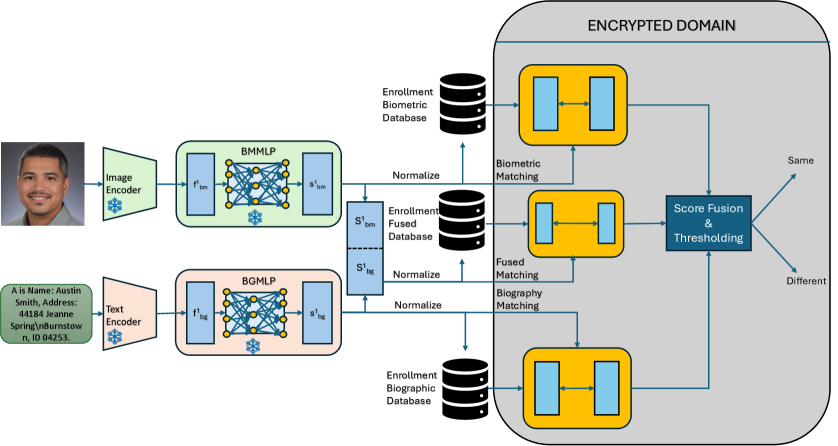
核心思路:论文的核心思路是利用全同态加密(Fully Homomorphic Encryption, FHE)技术,在加密状态下进行实体匹配。这意味着所有计算都在密文上进行,无需解密原始数据,从而保证了个人身份信息的隐私安全。同时,该方法结合多模态数据,利用不同数据源的信息来提高匹配的准确性。
技术框架:该框架包含以下主要阶段:1) 数据预处理:对多模态数据进行清洗和标准化,提取特征。2) 数据加密:使用全同态加密算法对个人身份信息进行加密。3) 密文匹配:在加密数据上进行实体匹配计算,例如计算相似度得分。4) 结果解密:只有授权方才能解密匹配结果,获取匹配成功的实体对。整个流程确保了数据在处理过程中始终处于加密状态。
关键创新:该论文的关键创新在于将全同态加密技术应用于多模态实体识别,从而在保证隐私的前提下,实现了高精度的实体匹配。与传统的隐私保护方法相比,全同态加密允许在密文上进行任意计算,避免了数据解密的风险。此外,该方法结合多模态数据,可以有效应对数据异构性带来的挑战。
关键设计:论文中可能涉及的关键设计包括:1) 全同态加密方案的选择:选择合适的FHE方案(例如BFV、CKKS等),以满足计算复杂度和安全性的要求。2) 相似度度量函数的选择:设计适用于密文计算的相似度度量函数,例如基于编辑距离或Jaccard系数的变体。3) 多模态融合策略:设计有效的多模态融合策略,将不同数据源的信息进行整合,提高匹配的准确性。4) 参数优化:针对特定的数据集和应用场景,对FHE参数和匹配阈值进行优化,以达到最佳的性能。
🖼️ 关键图片

📊 实验亮点
论文重点在于提出了一种基于全同态加密的多模态实体识别框架,旨在解决高合规性行业中的隐私保护问题。摘要中提到,该方法实现了可证明的低等错误率,并在大规模下保持计算上的可行性。具体的性能数据和对比基线需要在论文正文中查找。
🎯 应用场景
该研究成果可广泛应用于政府、金融、医疗等高合规性行业,解决跨部门、跨机构的数据整合与共享难题。例如,在金融领域,可以用于反洗钱、欺诈检测等场景;在医疗领域,可以用于患者身份识别、疾病追踪等场景。该技术有助于在保护个人隐私的前提下,提升数据利用效率,促进社会治理和经济发展。
📄 摘要(原文)
The canonical challenge of entity resolution within high-compliance sectors, where secure identity reconciliation is frequently confounded by significant data heterogeneity, including syntactic variations in personal identifiers, is a longstanding and complex problem. To this end, we introduce a novel multimodal framework operating with the voluminous data sets typical of government and financial institutions. Specifically, our methodology is designed to address the tripartite challenge of data volume, matching fidelity, and privacy. Consequently, the underlying plaintext of personally identifiable information remains computationally inaccessible throughout the matching lifecycle, empowering institutions to rigorously satisfy stringent regulatory mandates with cryptographic assurances of client confidentiality while achieving a demonstrably low equal error rate and maintaining computational tractability at scale.