GenAgent: Scaling Text-to-Image Generation via Agentic Multimodal Reasoning
作者: Kaixun Jiang, Yuzheng Wang, Junjie Zhou, Pandeng Li, Zhihang Liu, Chen-Wei Xie, Zhaoyu Chen, Yun Zheng, Wenqiang Zhang
分类: cs.CV
发布日期: 2026-01-26
🔗 代码/项目: GITHUB
💡 一句话要点
提出GenAgent以解决多模态生成与理解的高成本问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态生成 代理框架 强化学习 图像生成 自主交互
📋 核心要点
- 现有的多模态生成模型在训练成本和理解-生成能力之间存在权衡,限制了其应用。
- GenAgent通过代理框架将理解与生成解耦,使得生成过程可以调用不同的图像生成工具,支持多轮交互。
- 实验结果表明,GenAgent在多个基准测试中显著提升了生成性能,尤其是在GenEval++和WISE上分别提高了23.6%和14%。
📝 摘要(中文)
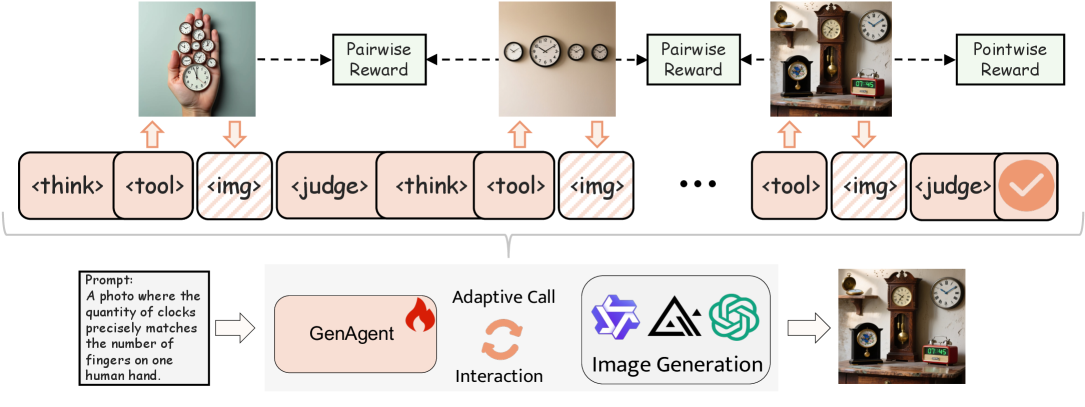
我们介绍了GenAgent,通过一个代理多模态模型统一视觉理解与生成。与面临高昂训练成本和理解-生成权衡的统一模型不同,GenAgent通过代理框架解耦这些能力:理解由多模态模型自身处理,而生成则通过将图像生成模型视为可调用工具来实现。该设计使得代理能够进行自主的多轮交互,生成包含推理、工具调用、判断和反思的多模态思维链,以迭代地优化输出。我们采用两阶段训练策略:首先,通过高质量工具调用和反思数据进行监督微调以启动代理行为;其次,结合点奖励(最终图像质量)和对比奖励(反思准确性)的端到端代理强化学习,进行轨迹重采样以增强多轮探索。GenAgent显著提升了基础生成器(FLUX.1-dev)在GenEval++(+23.6%)和WISE(+14%)上的表现。
🔬 方法详解
问题定义:论文旨在解决现有多模态生成模型在训练成本高和理解-生成能力权衡方面的不足,导致模型应用受限。
核心思路:GenAgent通过代理框架将理解与生成解耦,理解由多模态模型处理,而生成则通过调用图像生成模型作为工具来实现,从而支持自主的多轮交互。
技术框架:整体架构包括两个主要阶段:第一阶段是冷启动,通过高质量的工具调用和反思数据进行监督微调;第二阶段是端到端的代理强化学习,结合点奖励和对比奖励进行训练。
关键创新:GenAgent的最大创新在于其代理框架,允许模型在多轮交互中生成多模态思维链,迭代优化输出,与现有静态管道的模块化系统形成鲜明对比。
关键设计:在训练过程中,采用了轨迹重采样技术以增强多轮探索,损失函数结合了最终图像质量和反思准确性,确保生成结果的高质量和一致性。
🖼️ 关键图片


📊 实验亮点
实验结果显示,GenAgent在GenEval++基准测试中提升了23.6%,在WISE基准测试中提升了14%。这些显著的性能提升表明,GenAgent在多模态生成任务中具有强大的能力,尤其是在处理复杂交互时的表现优于传统模型。
🎯 应用场景
GenAgent的研究成果在多个领域具有潜在应用价值,包括智能助手、内容创作、教育工具等。通过支持多轮交互和自动化推理,GenAgent能够提升用户体验,推动人机交互的智能化进程。未来,该框架还可能在更复杂的多模态任务中展现出更大的应用潜力。
📄 摘要(原文)
We introduce GenAgent, unifying visual understanding and generation through an agentic multimodal model. Unlike unified models that face expensive training costs and understanding-generation trade-offs, GenAgent decouples these capabilities through an agentic framework: understanding is handled by the multimodal model itself, while generation is achieved by treating image generation models as invokable tools. Crucially, unlike existing modular systems constrained by static pipelines, this design enables autonomous multi-turn interactions where the agent generates multimodal chains-of-thought encompassing reasoning, tool invocation, judgment, and reflection to iteratively refine outputs. We employ a two-stage training strategy: first, cold-start with supervised fine-tuning on high-quality tool invocation and reflection data to bootstrap agent behaviors; second, end-to-end agentic reinforcement learning combining pointwise rewards (final image quality) and pairwise rewards (reflection accuracy), with trajectory resampling for enhanced multi-turn exploration. GenAgent significantly boosts base generator(FLUX.1-dev) performance on GenEval++ (+23.6\%) and WISE (+14\%). Beyond performance gains, our framework demonstrates three key properties: 1) cross-tool generalization to generators with varying capabilities, 2) test-time scaling with consistent improvements across interaction rounds, and 3) task-adaptive reasoning that automatically adjusts to different tasks. Our code will be available at \href{https://github.com/deep-kaixun/GenAgent}{this url}.