DisasterInsight: A Multimodal Benchmark for Function-Aware and Grounded Disaster Assessment
作者: Sara Tehrani, Yonghao Xu, Leif Haglund, Amanda Berg, Michael Felsberg
分类: cs.CV
发布日期: 2026-01-26
备注: Under review at ICPR 2026
💡 一句话要点
DisasterInsight:提出一个多模态基准,用于功能感知和有依据的灾害评估。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 灾害评估 遥感图像 视觉-语言模型 基准数据集
📋 核心要点
- 现有遥感视觉-语言基准缺乏对灾害场景中建筑物功能理解和指令鲁棒性的评估。
- DisasterInsight通过重构xBD数据集,构建以建筑物为中心的实例,并支持指令多样性评估,从而解决上述问题。
- 实验表明,DI-Chat在灾害程度和类型分类以及报告生成方面有显著提升,但建筑物功能分类仍具挑战。
📝 摘要(中文)
本文提出了DisasterInsight,一个多模态基准,旨在评估视觉-语言模型(VLMs)在真实灾害分析任务中的表现。现有遥感视觉-语言基准主要关注粗粒度标签和图像级识别,忽略了人道主义工作流程中所需的功能理解和指令鲁棒性。DisasterInsight将xBD数据集重构为约112K个以建筑物为中心的实例,并支持跨多个任务的指令多样性评估,包括建筑物功能分类、破坏程度和灾害类型分类、计数以及符合人道主义评估指南的结构化报告生成。为了建立领域自适应基线,本文提出了DI-Chat,通过使用参数高效的低秩适应(LoRA)在灾害特定指令数据上微调现有的VLM骨干网络获得。对最先进的通用和遥感VLM的广泛实验表明,跨任务存在显著的性能差距,尤其是在破坏理解和结构化报告生成方面。DI-Chat在破坏程度和灾害类型分类以及报告生成质量方面取得了显著改进,而建筑物功能分类对所有评估模型仍然具有挑战性。DisasterInsight为研究灾害图像中有依据的多模态推理提供了一个统一的基准。
🔬 方法详解
问题定义:现有遥感图像的视觉-语言模型基准测试主要集中在图像级别的识别和粗粒度的标签上,缺乏对灾害场景下建筑物功能理解和指令鲁棒性的细粒度评估。这使得模型难以应用于实际的人道主义救援工作流程,例如生成符合标准的灾害评估报告。
核心思路:本文的核心思路是构建一个更贴近实际灾害评估场景的多模态基准数据集DisasterInsight,并在此基础上训练和评估视觉-语言模型。通过提供更细粒度的标注(例如建筑物功能)和更真实的指令,促使模型学习更深层次的灾害理解能力。
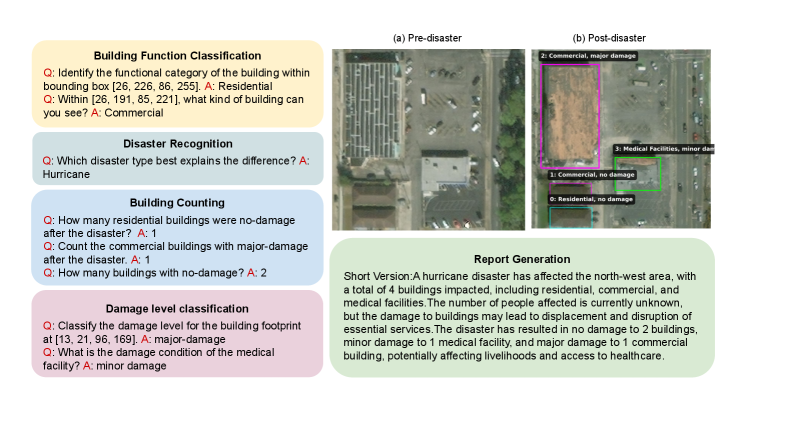
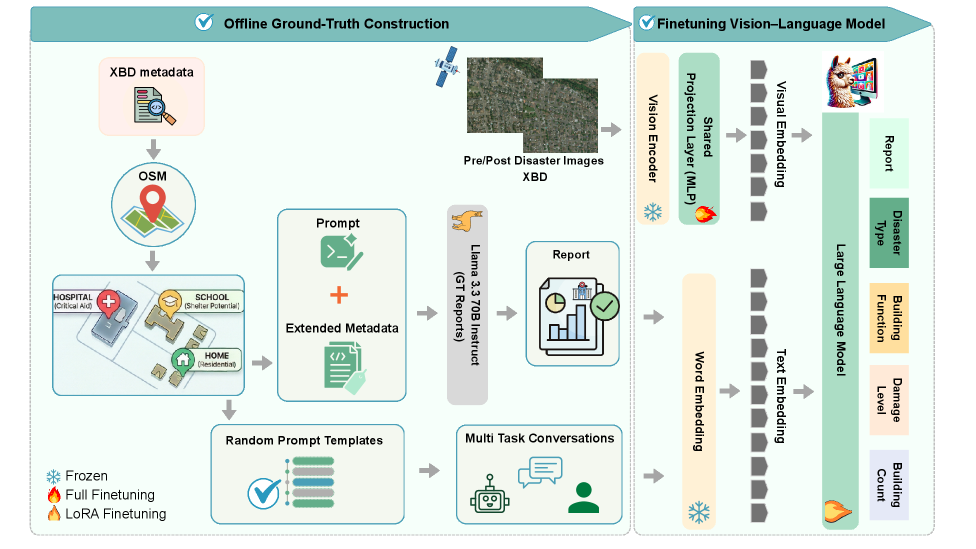
技术框架:DisasterInsight基准数据集基于xBD数据集构建,将其重构为以建筑物为中心的实例。该基准支持多种任务,包括:1) 建筑物功能分类;2) 破坏程度分类;3) 灾害类型分类;4) 建筑物计数;5) 结构化报告生成。为了建立领域自适应的基线,作者提出了DI-Chat模型,该模型通过在灾害特定指令数据上微调现有的VLM骨干网络得到。微调采用参数高效的LoRA方法。
关键创新:DisasterInsight基准数据集的创新之处在于其更细粒度的标注和更贴近实际应用场景的任务设置。与现有基准相比,DisasterInsight更注重模型的功能理解能力和指令鲁棒性。DI-Chat模型的创新之处在于其利用LoRA方法在灾害特定数据上进行高效的微调,从而提升模型在灾害评估任务上的性能。
关键设计:DI-Chat模型采用LoRA进行微调,LoRA通过引入低秩矩阵来近似权重更新,从而减少了需要训练的参数数量。具体来说,作者在预训练的VLM骨干网络中插入LoRA模块,并在灾害特定指令数据上进行训练。损失函数的设计取决于具体的任务类型,例如,分类任务使用交叉熵损失,报告生成任务使用序列到序列的损失函数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DI-Chat模型在破坏程度和灾害类型分类以及报告生成质量方面取得了显著改进。例如,在报告生成任务上,DI-Chat的性能优于其他基线模型。然而,建筑物功能分类任务对所有评估模型仍然具有挑战性,表明该领域仍有很大的提升空间。
🎯 应用场景
DisasterInsight的研究成果可应用于灾害响应和人道主义援助领域。通过提升视觉-语言模型对灾害图像的理解能力,可以辅助救援人员快速评估灾情、识别受损建筑物的功能、生成灾害评估报告,从而更有效地分配资源和制定救援计划。未来,该研究可扩展到其他类型的遥感图像分析任务。
📄 摘要(原文)
Timely interpretation of satellite imagery is critical for disaster response, yet existing vision-language benchmarks for remote sensing largely focus on coarse labels and image-level recognition, overlooking the functional understanding and instruction robustness required in real humanitarian workflows. We introduce DisasterInsight, a multimodal benchmark designed to evaluate vision-language models (VLMs) on realistic disaster analysis tasks. DisasterInsight restructures the xBD dataset into approximately 112K building-centered instances and supports instruction-diverse evaluation across multiple tasks, including building-function classification, damage-level and disaster-type classification, counting, and structured report generation aligned with humanitarian assessment guidelines. To establish domain-adapted baselines, we propose DI-Chat, obtained by fine-tuning existing VLM backbones on disaster-specific instruction data using parameter-efficient Low-Rank Adaptation (LoRA). Extensive experiments on state-of-the-art generic and remote-sensing VLMs reveal substantial performance gaps across tasks, particularly in damage understanding and structured report generation. DI-Chat achieves significant improvements on damage-level and disaster-type classification as well as report generation quality, while building-function classification remains challenging for all evaluated models. DisasterInsight provides a unified benchmark for studying grounded multimodal reasoning in disaster imagery.