Q-Bench-Portrait: Benchmarking Multimodal Large Language Models on Portrait Image Quality Perception
作者: Sijing Wu, Yunhao Li, Zicheng Zhang, Qi Jia, Xinyue Li, Huiyu Duan, Xiongkuo Min, Guangtao Zhai
分类: cs.CV
发布日期: 2026-01-26
💡 一句话要点
提出Q-Bench-Portrait,用于评估多模态大语言模型在人像图像质量感知方面的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 人像图像质量评估 基准数据集 AIGC 图像感知
📋 核心要点
- 现有MLLM在通用图像质量评估上表现良好,但在人像图像质量感知方面缺乏专门的评估基准。
- Q-Bench-Portrait基准包含多样的人像图像来源和全面的质量维度,并设计了多种问题形式。
- 实验结果表明,现有MLLM在人像图像感知方面仍有提升空间,与人类判断存在差距。
📝 摘要(中文)
多模态大语言模型(MLLMs)在现有低级视觉基准测试中表现出令人印象深刻的性能,但这些基准主要关注通用图像。它们感知和评估人像图像的能力,特别是人像图像具有独特的结构和感知属性,在很大程度上仍未被探索。为此,我们推出了Q-Bench-Portrait,这是第一个专门为人像图像质量感知而设计的整体基准,包含2765个图像-问题-答案三元组,具有以下特点:(1)多样化的人像图像来源,包括自然图像、合成失真图像、AI生成图像、艺术图像和计算机图形图像;(2)全面的质量维度,涵盖技术失真、AIGC特定失真和美学;(3)一系列问题形式,包括单选题、多选题、判断题和开放式问题,涵盖全局和局部层面。基于Q-Bench-Portrait,我们评估了20个开源和5个闭源的MLLM,结果表明,虽然当前的模型在人像图像感知方面表现出一定的能力,但它们的性能仍然有限且不精确,与人类判断存在明显的差距。我们希望所提出的基准能够促进对通用和特定领域MLLM的人像图像感知能力进行进一步研究。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLMs)在人像图像质量感知方面缺乏有效评估的问题。现有方法主要集中在通用图像的质量评估,忽略了人像图像独特的结构和感知特性,导致MLLMs在人像图像质量评估上的性能未知。
核心思路:论文的核心思路是构建一个专门针对人像图像质量感知的基准数据集Q-Bench-Portrait。该数据集包含多样化的人像图像,涵盖了自然图像、合成失真图像、AI生成图像、艺术图像和计算机图形图像等多种来源,并从技术失真、AIGC特定失真和美学等多个维度进行质量评估。通过设计不同类型的问题,全面评估MLLMs在人像图像质量感知方面的能力。
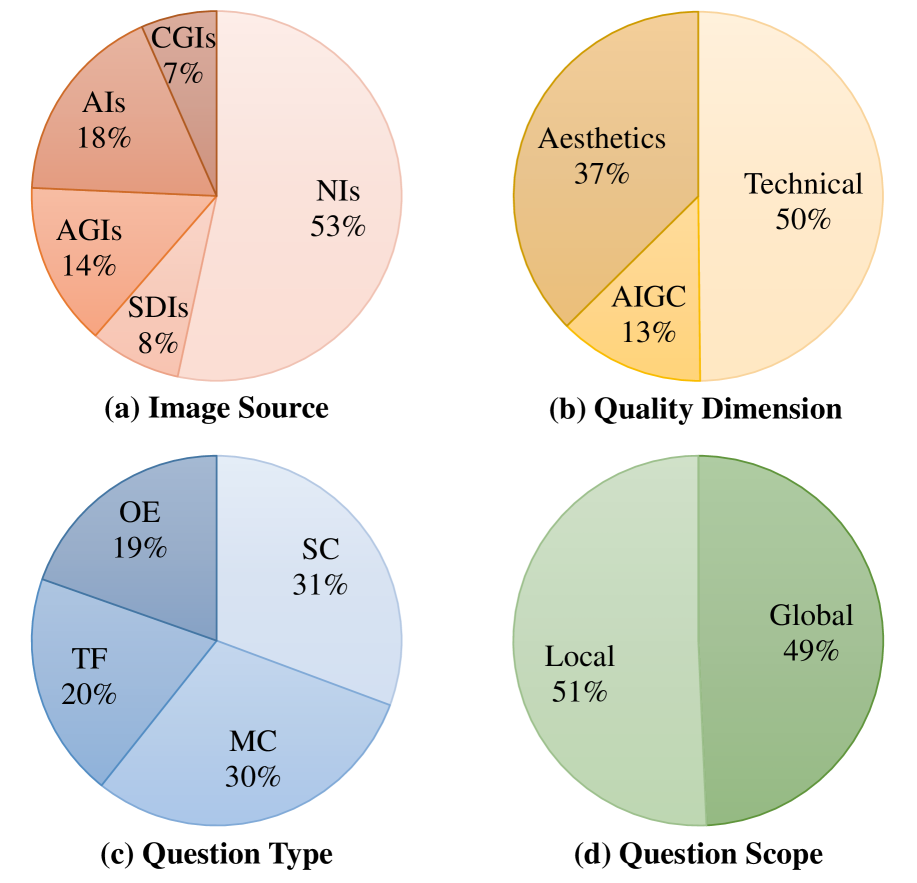
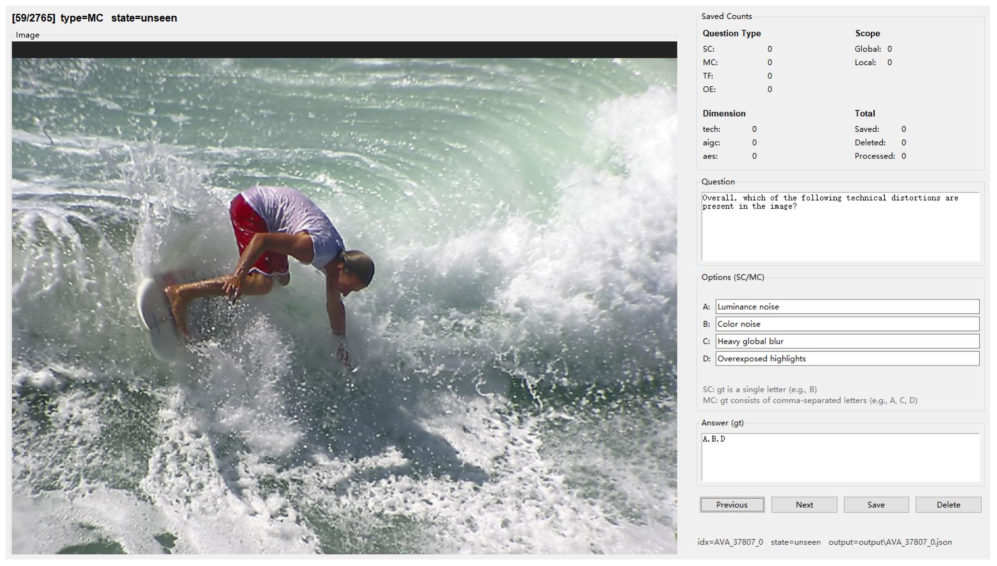
技术框架:Q-Bench-Portrait基准数据集的构建流程主要包括以下几个阶段:1. 图像收集:收集来自不同来源的人像图像,确保图像的多样性。2. 质量标注:从技术失真、AIGC特定失真和美学等多个维度对图像质量进行标注。3. 问题设计:设计单选题、多选题、判断题和开放式问题等多种问题形式,涵盖全局和局部层面。4. 数据集构建:将图像、问题和答案组成三元组,构建最终的Q-Bench-Portrait数据集。
关键创新:该论文的关键创新在于构建了第一个专门针对人像图像质量感知的基准数据集Q-Bench-Portrait。与现有通用图像质量评估基准相比,Q-Bench-Portrait更加关注人像图像的独特性,并从多个维度对人像图像质量进行评估。此外,该数据集还包含了AIGC生成的图像,可以用于评估MLLMs在处理新型图像生成技术方面的能力。
关键设计:Q-Bench-Portrait数据集包含2765个图像-问题-答案三元组。图像来源包括自然图像、合成失真图像、AI生成图像、艺术图像和计算机图形图像。质量维度涵盖技术失真(如模糊、噪声、压缩伪影)、AIGC特定失真(如人脸变形、细节缺失)和美学(如构图、光线)。问题形式包括单选题、多选题、判断题和开放式问题,涵盖全局和局部层面。数据集的标注由多位专家进行,以确保标注的准确性和一致性。
🖼️ 关键图片

📊 实验亮点
通过在Q-Bench-Portrait上评估20个开源和5个闭源的MLLM,发现现有模型在人像图像感知方面表现出一定的能力,但性能仍然有限且不精确,与人类判断存在明显的差距。例如,在AIGC特定失真方面,模型的识别能力明显低于人类。这表明,未来需要进一步研究如何提升MLLM在人像图像质量感知方面的能力。
🎯 应用场景
该研究成果可应用于提升多模态大语言模型在人像图像处理领域的性能,例如在人像美化、人像修复、AI写真等应用中,可以利用该基准评估和优化模型,从而提高用户体验和图像质量。此外,该基准还可以促进对AIGC生成人像图像质量评估的研究。
📄 摘要(原文)
Recent advances in multimodal large language models (MLLMs) have demonstrated impressive performance on existing low-level vision benchmarks, which primarily focus on generic images. However, their capabilities to perceive and assess portrait images, a domain characterized by distinct structural and perceptual properties, remain largely underexplored. To this end, we introduce Q-Bench-Portrait, the first holistic benchmark specifically designed for portrait image quality perception, comprising 2,765 image-question-answer triplets and featuring (1) diverse portrait image sources, including natural, synthetic distortion, AI-generated, artistic, and computer graphics images; (2) comprehensive quality dimensions, covering technical distortions, AIGC-specific distortions, and aesthetics; and (3) a range of question formats, including single-choice, multiple-choice, true/false, and open-ended questions, at both global and local levels. Based on Q-Bench-Portrait, we evaluate 20 open-source and 5 closed-source MLLMs, revealing that although current models demonstrate some competence in portrait image perception, their performance remains limited and imprecise, with a clear gap relative to human judgments. We hope that the proposed benchmark will foster further research into enhancing the portrait image perception capabilities of both general-purpose and domain-specific MLLMs.