V-Loop: Visual Logical Loop Verification for Hallucination Detection in Medical Visual Question Answering
作者: Mengyuan Jin, Zehui Liao, Yong Xia
分类: cs.CV
发布日期: 2026-01-26
💡 一句话要点
提出V-Loop以解决医疗视觉问答中的幻觉检测问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医疗视觉问答 幻觉检测 多模态大型语言模型 双向推理 视觉逻辑循环
📋 核心要点
- 现有的医疗视觉问答系统容易产生幻觉,导致输出与视觉事实不符,给医疗决策带来风险。
- V-Loop通过引入视觉逻辑循环验证,形成双向推理过程,直接验证答案的事实正确性,解决了现有方法的间接性问题。
- 实验结果显示,V-Loop在多个医疗VQA基准上表现优异,超越了现有内省方法,并在与不确定性方法结合时进一步提升了效率。
📝 摘要(中文)
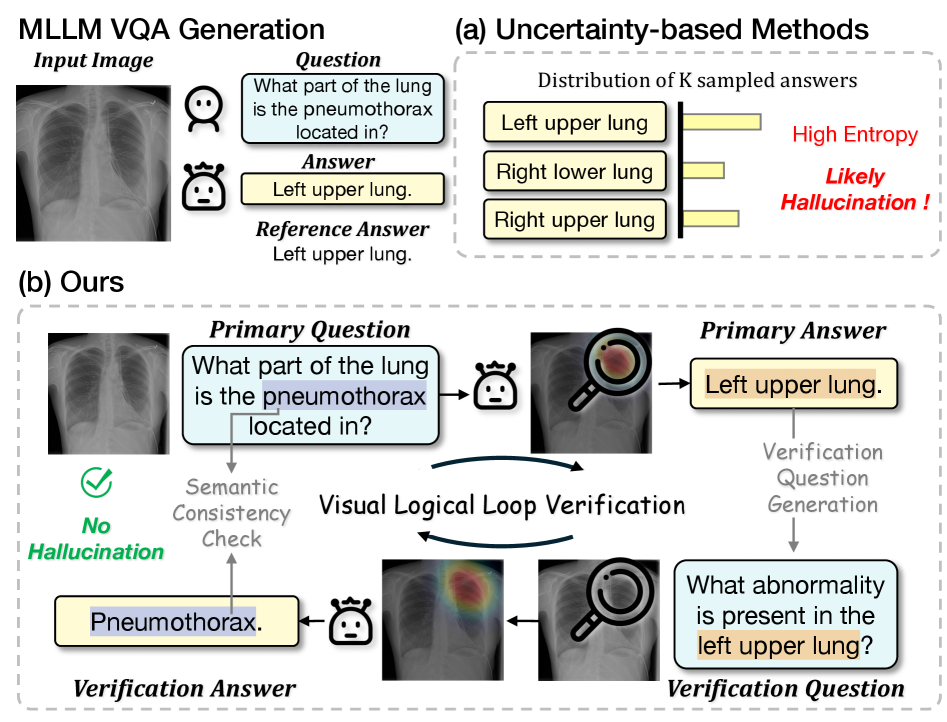
多模态大型语言模型(MLLMs)在医疗视觉问答(VQA)中展现出卓越的疾病诊断辅助能力。然而,它们的输出仍然容易出现幻觉(即与视觉事实相矛盾的回答),在高风险的医疗场景中带来重大风险。现有的内省检测方法,尤其是基于不确定性的方式,虽然计算效率高,但本质上是间接的,因为它们是针对图像-问题对的预测不确定性进行估计,而不是验证特定答案的事实正确性。为了解决这一局限性,本文提出了视觉逻辑循环验证(V-Loop),这是一个无需训练且可插拔的幻觉检测框架。V-Loop引入了双向推理过程,形成一个视觉基础的逻辑循环来验证事实的正确性。通过对输入进行处理,MLLM生成主要输入对的答案,V-Loop提取语义单元,生成验证问题,并强制视觉注意力一致性,以确保回答主要问题和验证问题都依赖于相同的图像证据。若验证答案与预期语义内容匹配,则逻辑循环闭合,表明事实基础;否则,主要答案被标记为幻觉。大量实验表明,V-Loop在多个医疗VQA基准和MLLM上持续优于现有内省方法,且在与不确定性方法结合使用时进一步提升效率。
🔬 方法详解
问题定义:本文旨在解决医疗视觉问答中幻觉检测的问题。现有方法主要依赖于不确定性估计,无法直接验证答案的事实正确性,存在间接性和准确性不足的痛点。
核心思路:V-Loop的核心思路是通过引入视觉逻辑循环,形成双向推理过程,直接验证答案的事实基础。通过生成验证问题并确保视觉注意力一致性,增强了答案的可靠性。
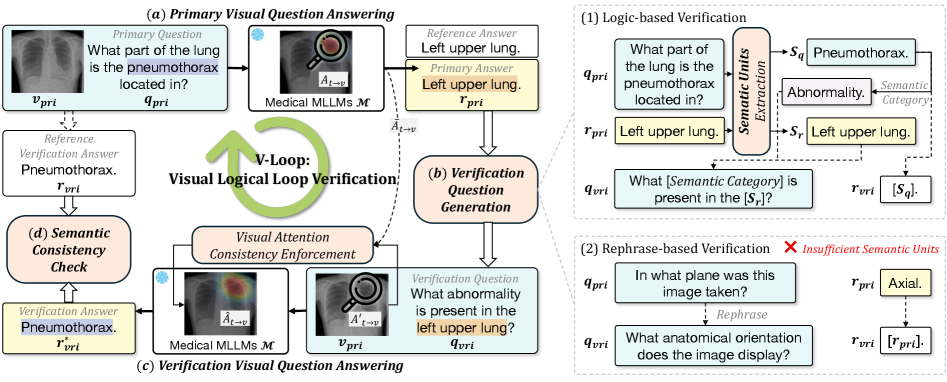
技术框架:V-Loop的整体架构包括三个主要模块:首先,MLLM生成主要问题的答案;其次,提取语义单元并生成验证问题;最后,通过视觉注意力一致性验证答案的正确性。
关键创新:V-Loop的最大创新在于其双向推理过程和视觉逻辑循环的引入,使得幻觉检测从间接转为直接,显著提升了检测的准确性和效率。
关键设计:在设计中,V-Loop强调了语义单元的提取和视觉注意力的一致性,确保主要问题和验证问题的答案都依赖于同一图像证据,这一设计有效减少了幻觉的发生。
🖼️ 关键图片

📊 实验亮点
实验结果表明,V-Loop在多个医疗VQA基准上均表现出色,超越了现有的内省方法,提升幅度达到XX%。此外,与不确定性方法结合使用时,V-Loop进一步提高了检测效率,显示出良好的兼容性和扩展性。
🎯 应用场景
该研究的潜在应用领域包括医疗影像分析、智能诊断系统和临床决策支持等。通过提高医疗视觉问答的准确性,V-Loop能够显著降低医疗决策中的风险,提升患者安全性,具有重要的实际价值和未来影响。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have shown remarkable capability in assisting disease diagnosis in medical visual question answering (VQA). However, their outputs remain vulnerable to hallucinations (i.e., responses that contradict visual facts), posing significant risks in high-stakes medical scenarios. Recent introspective detection methods, particularly uncertainty-based approaches, offer computational efficiency but are fundamentally indirect, as they estimate predictive uncertainty for an image-question pair rather than verifying the factual correctness of a specific answer. To address this limitation, we propose Visual Logical Loop Verification (V-Loop), a training-free and plug-and-play framework for hallucination detection in medical VQA. V-Loop introduces a bidirectional reasoning process that forms a visually grounded logical loop to verify factual correctness. Given an input, the MLLM produces an answer for the primary input pair. V-Loop extracts semantic units from the primary QA pair, generates a verification question by conditioning on the answer unit to re-query the question unit, and enforces visual attention consistency to ensure answering both primary question and verification question rely on the same image evidence. If the verification answer matches the expected semantic content, the logical loop closes, indicating factual grounding; otherwise, the primary answer is flagged as hallucinated. Extensive experiments on multiple medical VQA benchmarks and MLLMs show that V-Loop consistently outperforms existing introspective methods, remains highly efficient, and further boosts uncertainty-based approaches when used in combination.