HomoFM: Deep Homography Estimation with Flow Matching
作者: Mengfan He, Liangzheng Sun, Chunyu Li, Ziyang Meng
分类: cs.CV
发布日期: 2026-01-26
🔗 代码/项目: GITHUB
💡 一句话要点
HomoFM:利用流匹配的深度单应性估计,提升精度与鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 单应性估计 流匹配 深度学习 领域自适应 计算机视觉
📋 核心要点
- 现有单应性估计方法难以捕捉复杂几何变换,且泛化能力不足,尤其是在领域偏移的情况下。
- HomoFM将单应性估计问题转化为速度场学习,通过流匹配技术建模连续的速度场,实现高精度变换。
- 通过集成梯度反转层,HomoFM能够学习领域不变的特征表示,显著提升了在不同场景下的鲁棒性。
📝 摘要(中文)
深度单应性估计在计算机视觉和机器人领域有着广泛的应用。现有的方法通常将其视为直接回归或迭代细化问题,难以捕捉复杂的几何变换或泛化到不同的领域。本文提出了HomoFM,首次将生成建模中的流匹配技术引入单应性估计任务。与现有方法不同,我们将单应性估计问题转化为速度场学习问题。通过建模一个连续的、点对点的速度场,将噪声分布转换为配准坐标,所提出的网络通过条件流轨迹恢复高精度变换。此外,为了解决领域偏移问题,例如多模态匹配或不同光照场景,我们将梯度反转层(GRL)集成到特征提取骨干网络中。这种领域自适应策略显式地约束编码器学习领域不变的表示,从而显著增强网络的鲁棒性。大量实验表明了该方法的有效性,表明HomoFM在标准基准测试中优于最先进的方法,在估计精度和鲁棒性方面均有提升。
🔬 方法详解
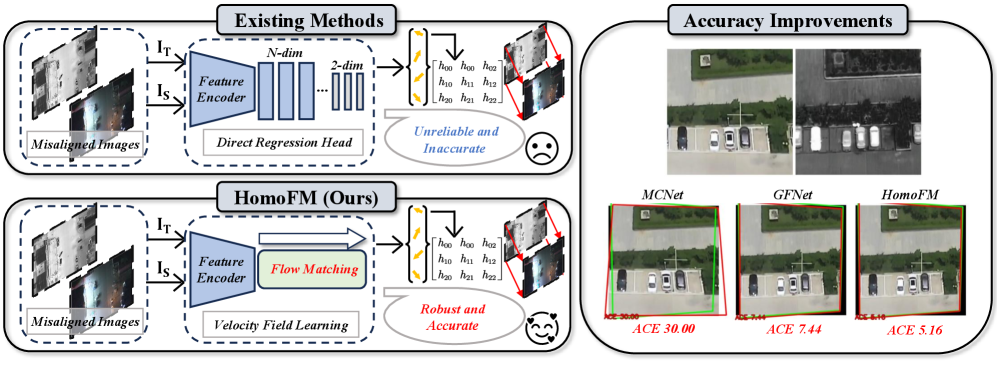
问题定义:现有的深度单应性估计方法通常采用直接回归或迭代细化的方式,难以有效处理复杂的几何变换,并且在面对领域偏移(如光照变化、多模态图像等)时,泛化能力较差。这些方法没有充分利用图像像素间的关系,容易陷入局部最优,导致估计精度不高。
核心思路:HomoFM的核心思路是将单应性估计问题转化为学习一个连续的速度场。该速度场描述了如何将一个图像中的像素点“流动”到另一个图像中的对应位置。通过学习这个速度场,可以避免直接回归单应性矩阵带来的困难,并且能够更好地处理复杂的几何变换。流匹配技术能够有效地学习这种连续的变换关系。
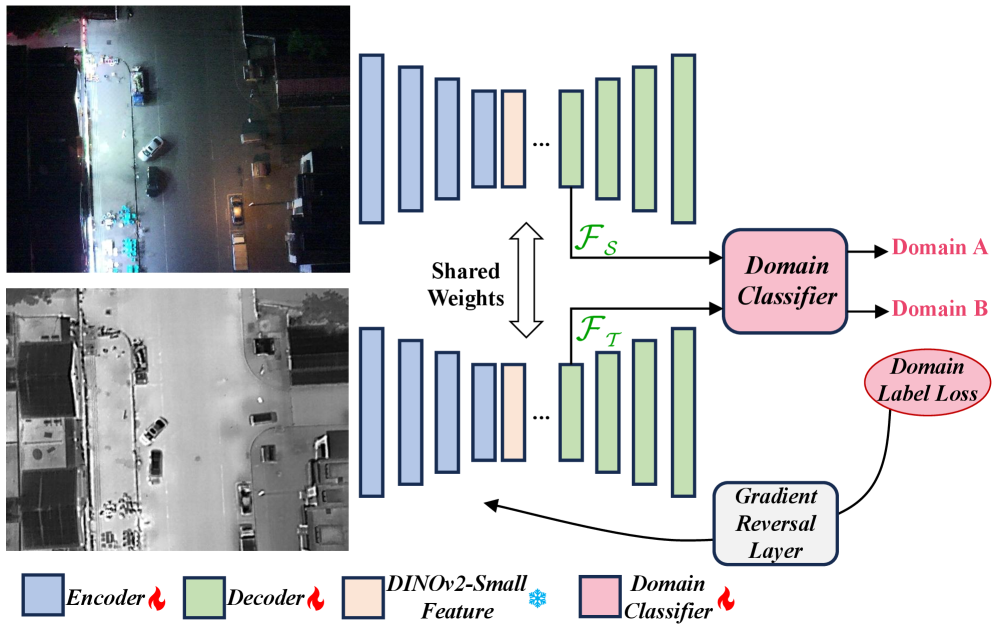
技术框架:HomoFM的整体框架包括特征提取、速度场估计和单应性矩阵恢复三个主要阶段。首先,使用一个带有梯度反转层(GRL)的特征提取网络,从两幅图像中提取领域不变的特征。然后,利用这些特征估计一个条件速度场,该速度场描述了如何将一个图像中的像素点变换到另一个图像中的对应位置。最后,通过对速度场进行积分,或者使用其他方法,恢复出单应性矩阵。
关键创新:HomoFM的关键创新在于首次将流匹配技术引入到单应性估计任务中。通过学习连续的速度场,避免了直接回归单应性矩阵的困难,并且能够更好地处理复杂的几何变换和领域偏移。梯度反转层(GRL)的引入,使得网络能够学习领域不变的特征表示,进一步提升了鲁棒性。
关键设计:特征提取网络使用了ResNet或其他常用的卷积神经网络作为骨干网络,并集成了梯度反转层(GRL)以实现领域自适应。速度场估计模块可以使用卷积神经网络或其他适合学习连续函数的模型。损失函数包括流匹配损失和单应性损失,用于约束速度场的学习和单应性矩阵的恢复。具体的参数设置和网络结构需要根据具体的应用场景进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,HomoFM在标准基准测试中优于目前最先进的方法。在估计精度方面,HomoFM的平均误差显著低于其他方法。在鲁棒性方面,HomoFM在光照变化、视角变化等复杂场景下的表现也明显优于其他方法。具体的数据指标可以在论文中找到。
🎯 应用场景
HomoFM在计算机视觉和机器人领域具有广泛的应用前景,例如图像配准、图像拼接、视觉SLAM、增强现实等。该方法能够提高这些应用在复杂场景下的精度和鲁棒性,尤其是在光照变化、视角变化等情况下。此外,该方法还可以应用于医学图像配准、遥感图像配准等领域,具有重要的实际价值。
📄 摘要(原文)
Deep homography estimation has broad applications in computer vision and robotics. Remarkable progresses have been achieved while the existing methods typically treat it as a direct regression or iterative refinement problem and often struggling to capture complex geometric transformations or generalize across different domains. In this work, we propose HomoFM, a new framework that introduces the flow matching technique from generative modeling into the homography estimation task for the first time. Unlike the existing methods, we formulate homography estimation problem as a velocity field learning problem. By modeling a continuous and point-wise velocity field that transforms noisy distributions into registered coordinates, the proposed network recovers high-precision transformations through a conditional flow trajectory. Furthermore, to address the challenge of domain shifts issue, e.g., the cases of multimodal matching or varying illumination scenarios, we integrate a gradient reversal layer (GRL) into the feature extraction backbone. This domain adaptation strategy explicitly constrains the encoder to learn domain-invariant representations, significantly enhancing the network's robustness. Extensive experiments demonstrate the effectiveness of the proposed method, showing that HomoFM outperforms state-of-the-art methods in both estimation accuracy and robustness on standard benchmarks. Code and data resource are available at https://github.com/hmf21/HomoFM.