QualiRAG: Retrieval-Augmented Generation for Visual Quality Understanding
作者: Linhan Cao, Wei Sun, Weixia Zhang, Xiangyang Zhu, Kaiwei Zhang, Jun Jia, Dandan Zhu, Guangtao Zhai, Xiongkuo Min
分类: cs.CV
发布日期: 2026-01-26
🔗 代码/项目: GITHUB
💡 一句话要点
提出QualiRAG,一种免训练的检索增强生成框架,用于视觉质量理解。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉质量评估 检索增强生成 多模态模型 零样本学习 知识图谱
📋 核心要点
- 现有视觉质量评估方法依赖于大量标注数据进行模型训练,易受数据集偏差影响,泛化能力受限。
- QualiRAG通过检索增强生成,动态构建视觉元数据、主体定位等知识源,无需训练即可进行视觉质量理解。
- 实验表明,QualiRAG在视觉质量理解和比较任务上均取得了显著提升,展现了强大的零样本质量评估能力。
📝 摘要(中文)
视觉质量评估(VQA)正日益从标量分数预测转向可解释的质量理解,这种范式需要精细的时空感知和辅助上下文信息。目前的方法依赖于在精心策划的指令数据集上进行监督微调或强化学习,这涉及劳动密集型标注,并且容易产生数据集特定的偏差。为了解决这些挑战,我们提出QualiRAG,一个免训练的检索增强生成(RAG)框架,该框架系统地利用大型多模态模型(LMM)的潜在感知知识进行视觉质量感知。与从静态语料库检索的传统RAG不同,QualiRAG通过将问题分解为结构化请求并构建四个互补的知识来源来动态生成辅助知识:视觉元数据、主体定位、全局质量摘要和局部质量描述,然后进行相关性感知检索以进行基于证据的推理。大量实验表明,QualiRAG在视觉质量理解任务上实现了优于开源通用LMM和VQA微调LMM的显著改进,并在视觉质量比较任务上提供了具有竞争力的性能,证明了无需任何特定于任务的训练的强大质量评估能力。
🔬 方法详解
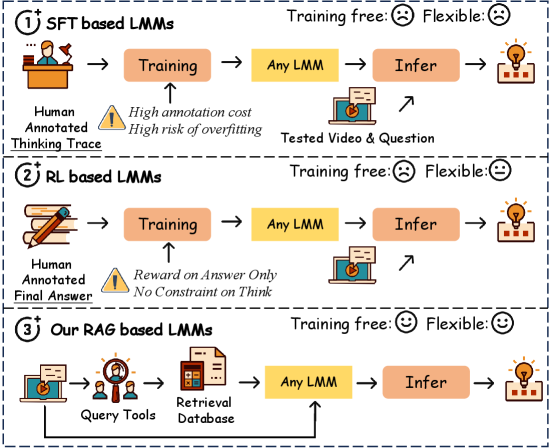
问题定义:论文旨在解决视觉质量理解任务中,现有方法依赖大量标注数据和易受数据集偏差影响的问题。现有方法通常需要针对特定数据集进行微调或强化学习,泛化能力较差,难以适应真实场景中的多样化视觉质量评估需求。
核心思路:论文的核心思路是利用大型多模态模型(LMM)的预训练知识,通过检索增强生成(RAG)的方式,动态构建与视觉质量相关的上下文信息,从而实现免训练的视觉质量理解。这种方法避免了对大量标注数据的依赖,提高了模型的泛化能力。
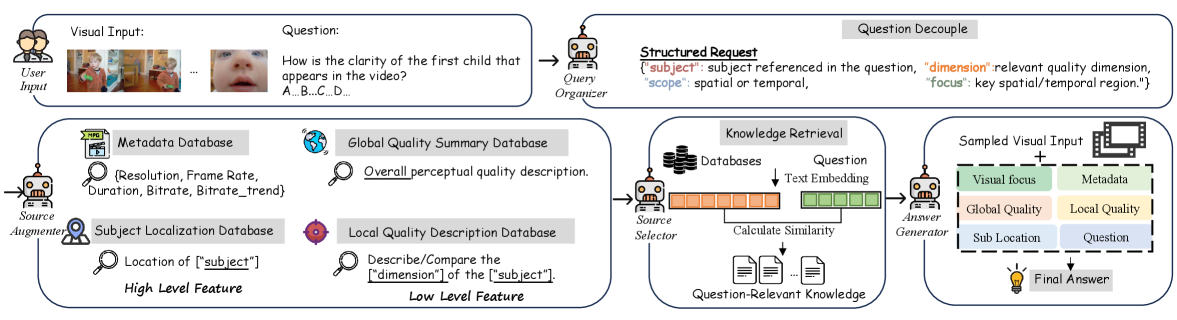
技术框架:QualiRAG框架主要包含以下几个阶段:1) 问题分解:将用户提出的视觉质量问题分解为结构化的请求。2) 知识构建:根据分解后的请求,动态生成四个互补的知识来源,包括视觉元数据、主体定位、全局质量摘要和局部质量描述。3) 相关性感知检索:从构建的知识源中检索与问题相关的证据。4) 基于证据的推理:利用检索到的证据,结合LMM的预训练知识,进行视觉质量理解和评估。
关键创新:QualiRAG的关键创新在于其动态知识构建和检索机制。与传统的RAG方法不同,QualiRAG不是从静态语料库中检索信息,而是根据用户提出的问题,动态生成相关的知识源。这种方法能够更有效地利用LMM的预训练知识,提高视觉质量理解的准确性和可靠性。
关键设计:QualiRAG的关键设计包括:1) 四种互补知识源的构建方法,例如,使用目标检测模型进行主体定位,使用图像描述模型生成全局质量摘要。2) 相关性感知检索算法,用于从构建的知识源中选择与问题最相关的证据。3) 如何将检索到的证据有效地融入到LMM的输入中,以进行基于证据的推理。具体的参数设置、损失函数和网络结构等细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
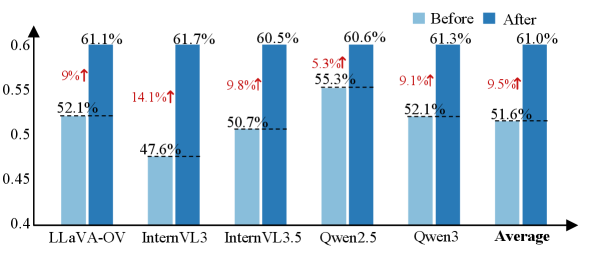
QualiRAG在视觉质量理解任务上显著优于开源通用LMM和VQA微调LMM,无需任何特定于任务的训练。在视觉质量比较任务上,QualiRAG也取得了具有竞争力的性能,证明了其强大的零样本质量评估能力。具体性能数据和对比基线在摘要中未提供,需查阅原文。
🎯 应用场景
QualiRAG可应用于图像/视频质量监控、内容审核、图像增强算法评估等领域。例如,在视频监控中,QualiRAG可以自动评估视频质量,及时发现模糊、噪声等问题。在图像增强算法评估中,QualiRAG可以客观地评估不同算法的增强效果,为算法选择提供依据。该研究有助于提升视觉质量评估的自动化水平和智能化程度。
📄 摘要(原文)
Visual quality assessment (VQA) is increasingly shifting from scalar score prediction toward interpretable quality understanding -- a paradigm that demands \textit{fine-grained spatiotemporal perception} and \textit{auxiliary contextual information}. Current approaches rely on supervised fine-tuning or reinforcement learning on curated instruction datasets, which involve labor-intensive annotation and are prone to dataset-specific biases. To address these challenges, we propose \textbf{QualiRAG}, a \textit{training-free} \textbf{R}etrieval-\textbf{A}ugmented \textbf{G}eneration \textbf{(RAG)} framework that systematically leverages the latent perceptual knowledge of large multimodal models (LMMs) for visual quality perception. Unlike conventional RAG that retrieves from static corpora, QualiRAG dynamically generates auxiliary knowledge by decomposing questions into structured requests and constructing four complementary knowledge sources: \textit{visual metadata}, \textit{subject localization}, \textit{global quality summaries}, and \textit{local quality descriptions}, followed by relevance-aware retrieval for evidence-grounded reasoning. Extensive experiments show that QualiRAG achieves substantial improvements over open-source general-purpose LMMs and VQA-finetuned LMMs on visual quality understanding tasks, and delivers competitive performance on visual quality comparison tasks, demonstrating robust quality assessment capabilities without any task-specific training. The code will be publicly available at https://github.com/clh124/QualiRAG.