\textsc{NaVIDA}: Vision-Language Navigation with Inverse Dynamics Augmentation
作者: Weiye Zhu, Zekai Zhang, Xiangchen Wang, Hewei Pan, Teng Wang, Tiantian Geng, Rongtao Xu, Feng Zheng
分类: cs.CV, cs.AI
发布日期: 2026-01-26
备注: 18 pages, 14 figures
💡 一句话要点
NaVIDA:通过逆动力学增强的视觉-语言导航框架,提升导航稳定性和泛化性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 逆动力学 因果关系建模 分层动作分块 机器人导航
📋 核心要点
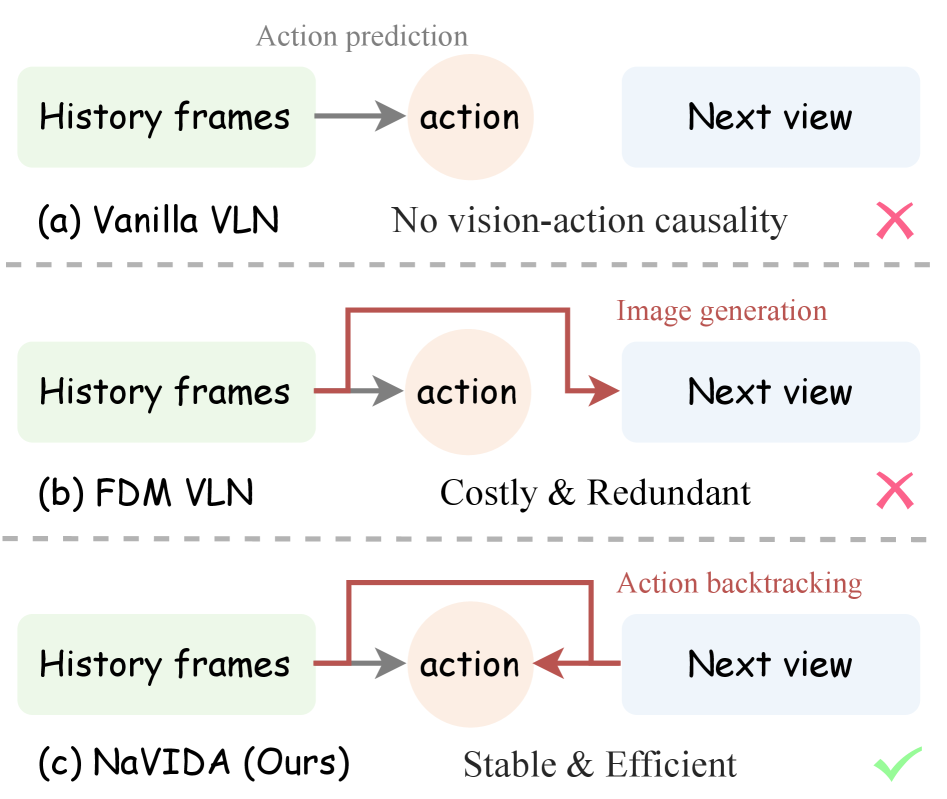
- 现有VLN方法缺乏对视觉-动作因果关系的建模,导致智能体无法预测自身动作带来的视觉变化,从而产生不稳定的行为。
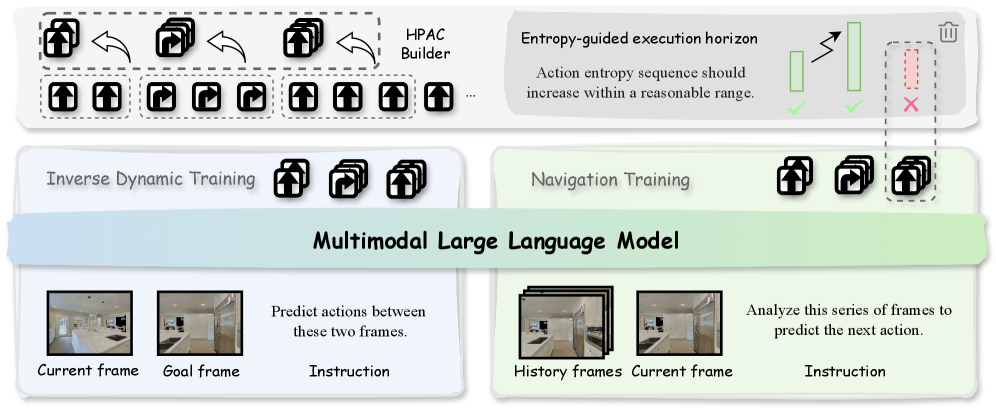
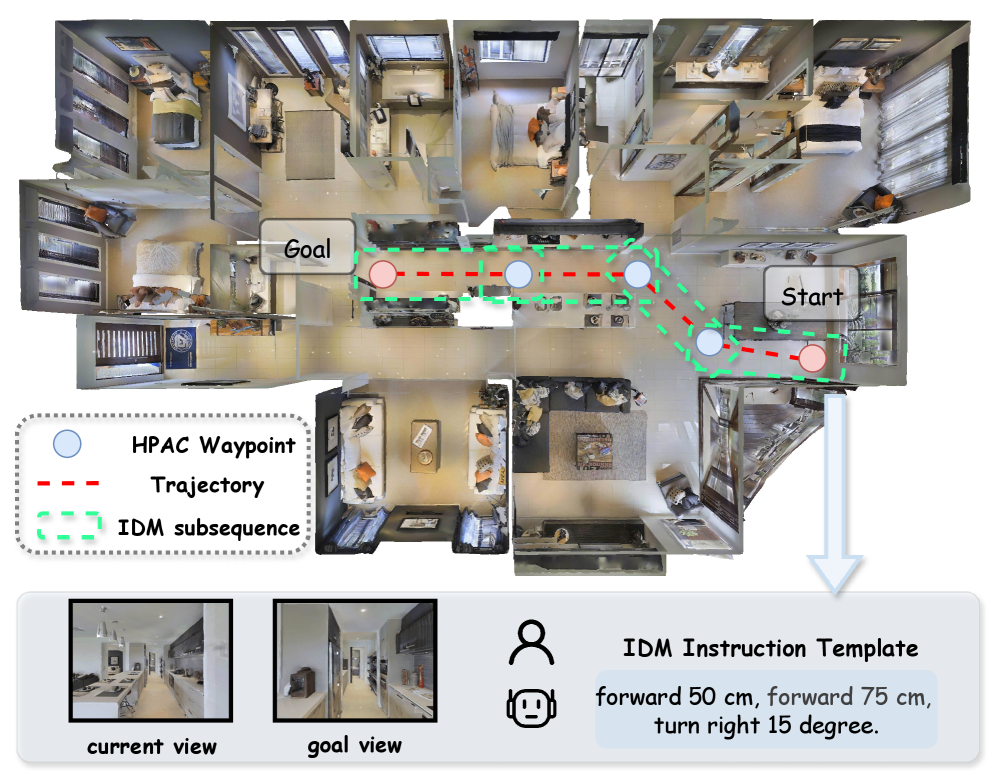
- NaVIDA通过逆动力学增强训练,学习视觉变化和动作之间的因果关系,并采用分层概率动作分块来扩展规划范围。
- 实验结果表明,NaVIDA在导航性能上优于现有方法,且参数量更少,并在真实机器人环境中验证了其可行性。
📝 摘要(中文)
视觉-语言导航(VLN)要求智能体理解自然语言指令并在视觉丰富的环境中连贯地行动。然而,现有方法大多依赖于反应式的状态-动作映射,而没有明确地建模动作如何因果地转换后续的视觉观察。由于缺乏这种视觉-动作因果关系,智能体无法预测其自身动作引起的视觉变化,导致不稳定的行为、较弱的泛化能力以及沿轨迹的累积误差。为了解决这些问题,我们提出了NaVIDA(NavigAtion with Inverse Dynamics Augmentation),一个统一的VLN框架,它将策略学习与动作相关的视觉动力学和自适应执行相结合。NaVIDA通过基于块的逆动力学监督来增强训练,以学习视觉变化和相应动作之间的因果关系。为了构建这种监督并扩展有效的规划范围,NaVIDA采用分层概率动作分块(HPAC),它将轨迹组织成多步块,并提供区分性的、更长距离的视觉变化线索。为了进一步抑制误差累积并稳定推理时的行为,一种熵引导机制自适应地设置动作块的执行范围。大量实验表明,与最先进的方法相比,NaVIDA以更少的参数(3B vs. 8B)实现了卓越的导航性能。真实世界机器人评估进一步验证了我们方法的实际可行性和有效性。代码和数据将在接收后提供。
🔬 方法详解
问题定义:视觉-语言导航(VLN)任务要求智能体根据自然语言指令在视觉环境中导航。现有方法主要依赖于状态-动作的直接映射,忽略了动作对环境视觉状态的因果影响。这种忽略导致智能体难以预测自身行为带来的视觉变化,从而产生导航过程中的不稳定性、泛化能力差以及累积误差等问题。
核心思路:NaVIDA的核心思路是通过学习视觉变化和动作之间的因果关系来解决上述问题。具体来说,它利用逆动力学建模,即预测导致特定视觉变化的动作序列。通过学习这种因果关系,智能体可以更好地理解自身行为对环境的影响,从而做出更明智的导航决策。
技术框架:NaVIDA框架包含三个主要组成部分:策略学习模块、动作相关的视觉动力学模块和自适应执行模块。策略学习模块负责学习导航策略,将视觉输入和语言指令映射到动作。动作相关的视觉动力学模块通过逆动力学建模学习视觉变化和动作之间的因果关系。自适应执行模块则根据当前状态的熵值,动态调整动作块的执行范围,以减少误差累积。
关键创新:NaVIDA的关键创新在于引入了逆动力学增强训练,显式地建模了视觉-动作因果关系。此外,分层概率动作分块(HPAC)技术将轨迹分解为多步动作块,并提供更长距离的视觉变化线索,有助于学习更有效的因果关系。自适应执行机制则通过熵引导动态调整动作块的执行范围,进一步提升了导航的稳定性。
关键设计:NaVIDA使用基于块的逆动力学监督,损失函数包括策略学习损失和逆动力学学习损失。HPAC通过概率模型对动作序列进行分层聚类,生成不同粒度的动作块。自适应执行机制使用熵值作为指标,动态调整动作块的执行步数。具体参数设置和网络结构细节在论文中有详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
NaVIDA在VLN任务上取得了显著的性能提升,与现有最先进的方法相比,在性能提升的同时,参数量减少至3B(现有方法为8B)。真实机器人实验验证了NaVIDA的实际可行性和有效性,表明其具有较强的泛化能力和鲁棒性。具体性能数据和提升幅度在论文中有详细描述(未知)。
🎯 应用场景
NaVIDA技术可应用于机器人导航、自动驾驶、虚拟现实等领域。例如,在机器人导航中,可以使机器人更好地理解人类指令,并在复杂环境中自主导航。在自动驾驶中,可以提高车辆对环境变化的感知能力,从而提升驾驶安全性。在虚拟现实中,可以增强用户与虚拟环境的交互体验。
📄 摘要(原文)
Vision-and-Language Navigation (VLN) requires agents to interpret natural language instructions and act coherently in visually rich environments. However, most existing methods rely on reactive state-action mappings without explicitly modeling how actions causally transform subsequent visual observations. Lacking such vision-action causality, agents cannot anticipate the visual changes induced by its own actions, leading to unstable behaviors, weak generalization, and cumulative error along trajectory. To address these issues, we introduce \textsc{NaVIDA} (\textbf{Nav}igation with \textbf{I}nverse \textbf{D}ynamics \textbf{A}ugmentation), a unified VLN framework that couples policy learning with action-grounded visual dynamics and adaptive execution. \textsc{NaVIDA} augments training with chunk-based inverse-dynamics supervision to learn causal relationship between visual changes and corresponding actions. To structure this supervision and extend the effective planning range, \textsc{NaVIDA} employs hierarchical probabilistic action chunking (HPAC), which organizes trajectories into multi-step chunks and provides discriminative, longer-range visual-change cues. To further curb error accumulation and stabilize behavior at inference, an entropy-guided mechanism adaptively sets the execution horizon of action chunks. Extensive experiments show that \textsc{NaVIDA} achieves superior navigation performance compared to state-of-the-art methods with fewer parameters (3B vs. 8B). Real-world robot evaluations further validate the practical feasibility and effectiveness of our approach. Code and data will be available upon acceptance.