Agentic Very Long Video Understanding
作者: Aniket Rege, Arka Sadhu, Yuliang Li, Kejie Li, Ramya Korlakai Vinayak, Yuning Chai, Yong Jae Lee, Hyo Jin Kim
分类: cs.CV, cs.LG
发布日期: 2026-01-26
备注: 26 pages, 7 figures, 8 tables
💡 一句话要点
EGAgent:基于实体场景图的Agentic超长视频理解框架
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 超长视频理解 Agentic框架 实体场景图 多模态推理 第一人称视角视频
📋 核心要点
- 现有方法在处理超长视频理解时,面临上下文窗口有限和缺乏多跳推理能力的挑战。
- EGAgent通过构建实体场景图,并赋予agent结构化搜索和推理能力,实现对超长视频的理解。
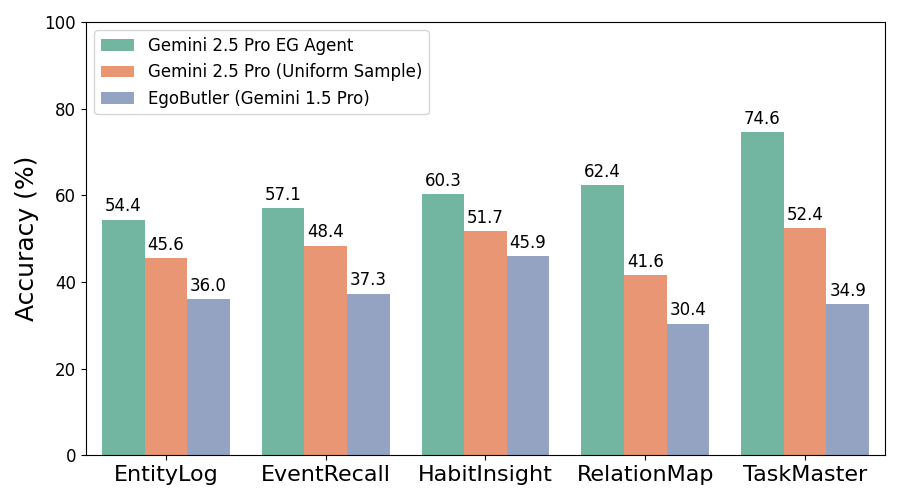
- 在EgoLifeQA数据集上取得了SOTA性能(57.5%),并在Video-MME (Long)数据集上取得了有竞争力的性能(74.1%)。
📝 摘要(中文)
随着智能眼镜等全天候可穿戴设备的出现,对情境理解提出了新的要求,需要超越短时孤立事件,涵盖连续的、纵向的自我中心视频流。为了实现这一目标,需要在长时程视频理解方面取得进展,系统必须能够解释和回忆跨越数天甚至数周的视觉和音频信息。现有方法,包括大型语言模型和检索增强生成,受到有限上下文窗口的约束,并且缺乏对超长视频流进行组合式、多跳推理的能力。本文提出了EGAgent,一个增强的agentic框架,以实体场景图为中心,表示人物、地点、物体及其随时间变化的关系。该系统为规划agent配备了用于结构化搜索和推理这些图的工具,以及混合视觉和音频搜索能力,从而实现详细的、跨模态的和时间上连贯的推理。在EgoLifeQA和Video-MME (Long)数据集上的实验表明,我们的方法在EgoLifeQA上实现了最先进的性能(57.5%),并在Video-MME (Long)上实现了具有竞争力的性能(74.1%),用于复杂的纵向视频理解任务。
🔬 方法详解
问题定义:论文旨在解决超长第一人称视角视频理解的问题。现有方法,如大型语言模型和检索增强生成,在处理此类视频时,由于上下文窗口的限制,无法进行有效的多跳推理和长期依赖建模,导致无法充分理解视频中的复杂事件和关系。
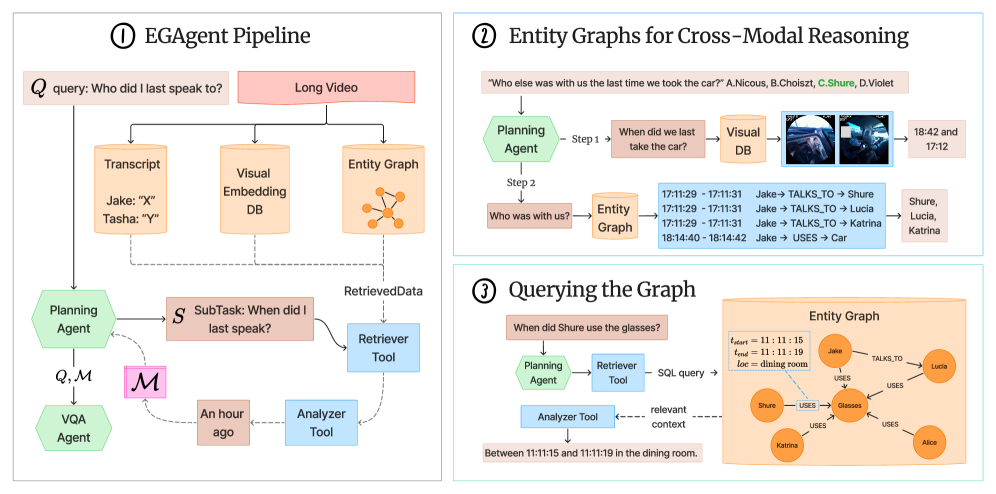
核心思路:论文的核心思路是构建一个基于实体场景图的Agentic框架。通过将视频内容表示为实体(人物、地点、物体)及其关系,并赋予Agent在这些图上进行结构化搜索和推理的能力,从而克服上下文窗口的限制,实现对超长视频的理解。这种方法允许Agent在时间上连贯地跟踪实体和事件,并进行跨模态的推理。
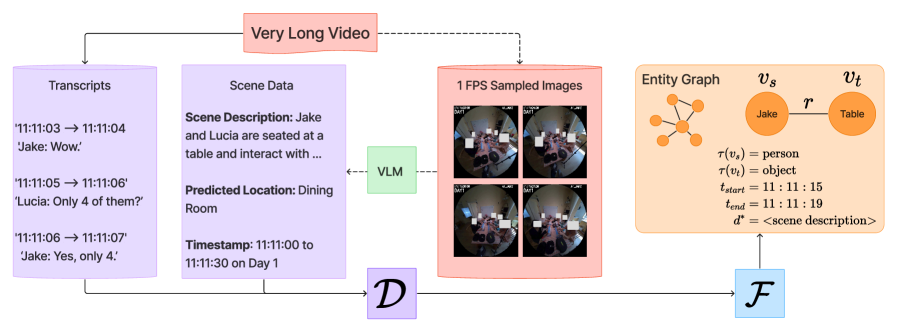
技术框架:EGAgent框架包含以下主要模块:1) 视频编码器:用于提取视频帧的视觉特征和音频特征。2) 实体场景图构建器:利用视觉和音频特征,检测和识别视频中的实体,并构建实体之间的关系图。3) 规划Agent:负责接收用户查询,并制定在实体场景图上进行搜索和推理的计划。4) 搜索和推理工具:包括结构化搜索工具(用于在实体场景图中查找相关实体和关系)和混合视觉和音频搜索工具(用于在原始视频中查找与查询相关的片段)。
关键创新:该论文的关键创新在于将Agentic框架与实体场景图相结合,用于超长视频理解。与传统的基于Transformer的方法相比,EGAgent能够更好地处理长期依赖关系,并进行多跳推理。此外,该框架还引入了混合视觉和音频搜索工具,从而实现跨模态的推理。
关键设计:实体场景图的构建是关键。论文可能采用了预训练的目标检测和关系抽取模型来初始化实体和关系,并使用图神经网络来更新实体和关系的表示。规划Agent可能使用了强化学习或模仿学习来学习如何制定搜索和推理计划。损失函数可能包括实体识别损失、关系抽取损失和推理损失。
🖼️ 关键图片
📊 实验亮点
EGAgent在EgoLifeQA数据集上取得了57.5%的SOTA性能,相比之前的最佳方法有显著提升。在Video-MME (Long)数据集上,EGAgent取得了74.1%的具有竞争力的性能,证明了其在复杂纵向视频理解任务上的有效性。这些结果表明,基于实体场景图的Agentic框架能够有效地处理超长视频理解问题。
🎯 应用场景
该研究成果可应用于智能助手、可穿戴设备、监控系统等领域。例如,智能眼镜可以利用该技术理解用户周围环境,并提供个性化的信息和服务。在监控系统中,该技术可以用于检测异常事件,并进行溯源分析。此外,该技术还可以用于视频摘要、视频检索等任务,提高视频处理的效率和准确性。
📄 摘要(原文)
The advent of always-on personal AI assistants, enabled by all-day wearable devices such as smart glasses, demands a new level of contextual understanding, one that goes beyond short, isolated events to encompass the continuous, longitudinal stream of egocentric video. Achieving this vision requires advances in long-horizon video understanding, where systems must interpret and recall visual and audio information spanning days or even weeks. Existing methods, including large language models and retrieval-augmented generation, are constrained by limited context windows and lack the ability to perform compositional, multi-hop reasoning over very long video streams. In this work, we address these challenges through EGAgent, an enhanced agentic framework centered on entity scene graphs, which represent people, places, objects, and their relationships over time. Our system equips a planning agent with tools for structured search and reasoning over these graphs, as well as hybrid visual and audio search capabilities, enabling detailed, cross-modal, and temporally coherent reasoning. Experiments on the EgoLifeQA and Video-MME (Long) datasets show that our method achieves state-of-the-art performance on EgoLifeQA (57.5%) and competitive performance on Video-MME (Long) (74.1%) for complex longitudinal video understanding tasks.