Spatial-Conditioned Reasoning in Long-Egocentric Videos
作者: James Tribble, Hao Wang, Si-En Hong, Chaoyi Zhou, Ashish Bastola, Siyu Huang, Abolfazl Razi
分类: cs.CV
发布日期: 2026-01-26
💡 一句话要点
通过空间条件推理提升长时第一视角视频的视觉导航能力
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 长时视频理解 第一视角视频 空间推理 视觉-语言模型 深度信息 视觉导航 数据集标注
📋 核心要点
- 长时第一视角视频的视觉导航面临视角漂移和缺乏几何上下文的挑战,现有方法难以有效利用空间信息。
- 论文核心在于探索显式空间信号(如深度信息)对视觉-语言模型在长时视频理解中的影响,无需修改模型结构。
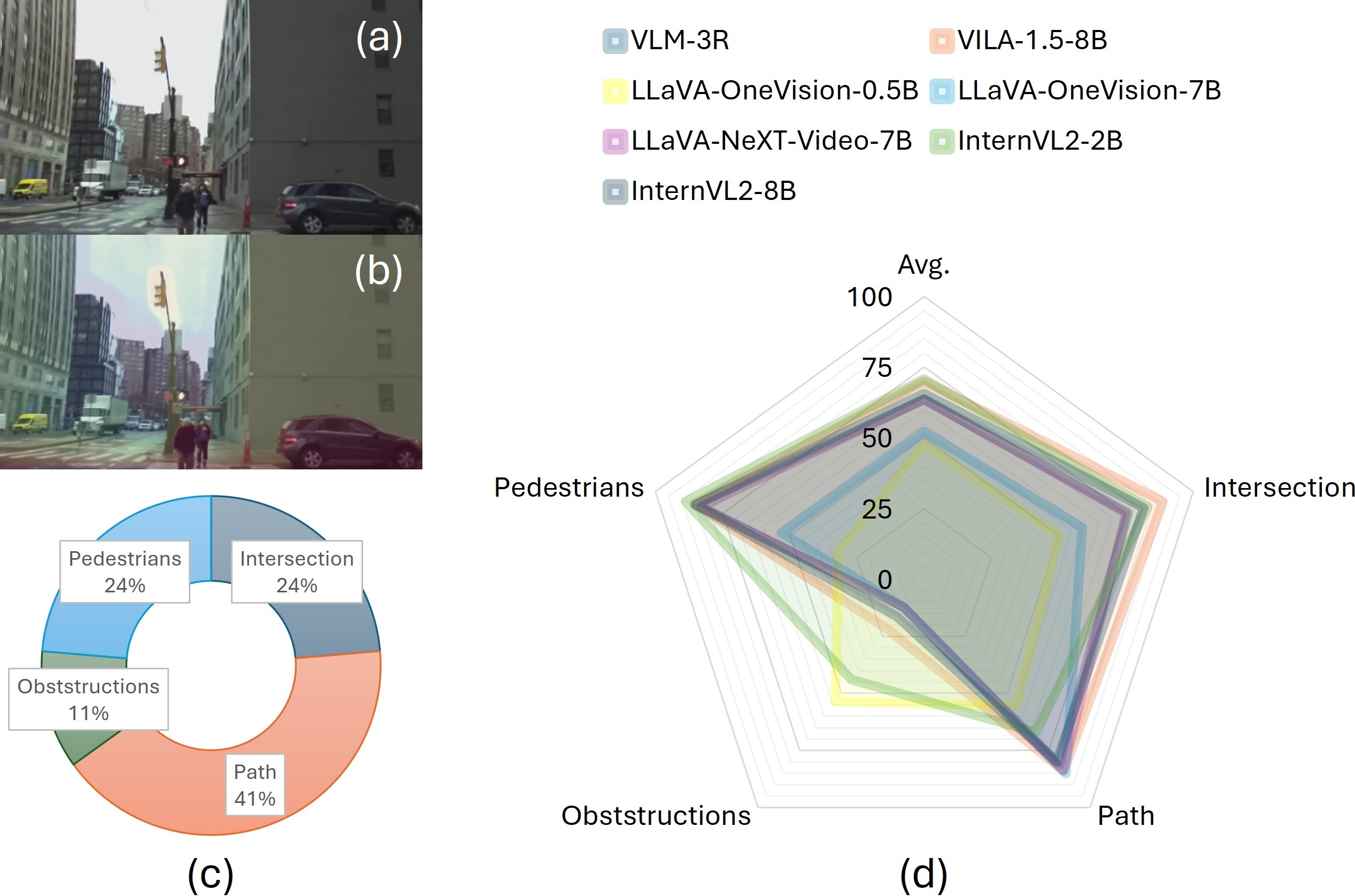
- 通过在重新标注的Sanpo-D数据集上进行实验,发现深度感知表示能提升行人/障碍物检测等安全关键任务的性能。
📝 摘要(中文)
长时第一视角视频由于视角漂移和缺乏持久的几何上下文,给视觉导航带来了重大挑战。尽管最近的视觉-语言模型在图像和短视频推理方面表现良好,但它们在长时第一视角序列中的空间推理能力仍然有限。本文研究了显式空间信号如何在不修改模型架构或推理过程的情况下影响基于VLM的视频理解。我们引入了Sanpo-D,这是对Google Sanpo数据集的细粒度重新标注,并对多个VLM在面向导航的空间查询上进行了基准测试。为了检查输入级别的归纳偏置,我们进一步将深度图与RGB帧融合,并评估它们对空间推理的影响。我们的结果揭示了通用精度和空间专业化之间的权衡,表明深度感知和空间接地的表示可以提高行人检测和障碍物检测等安全关键任务的性能。
🔬 方法详解
问题定义:现有视觉-语言模型(VLM)在处理长时第一视角视频时,由于视角变化和缺乏几何信息,空间推理能力不足,难以有效进行视觉导航。现有方法难以充分利用视频中的空间信息,导致在安全关键任务(如行人检测、障碍物检测)中表现欠佳。
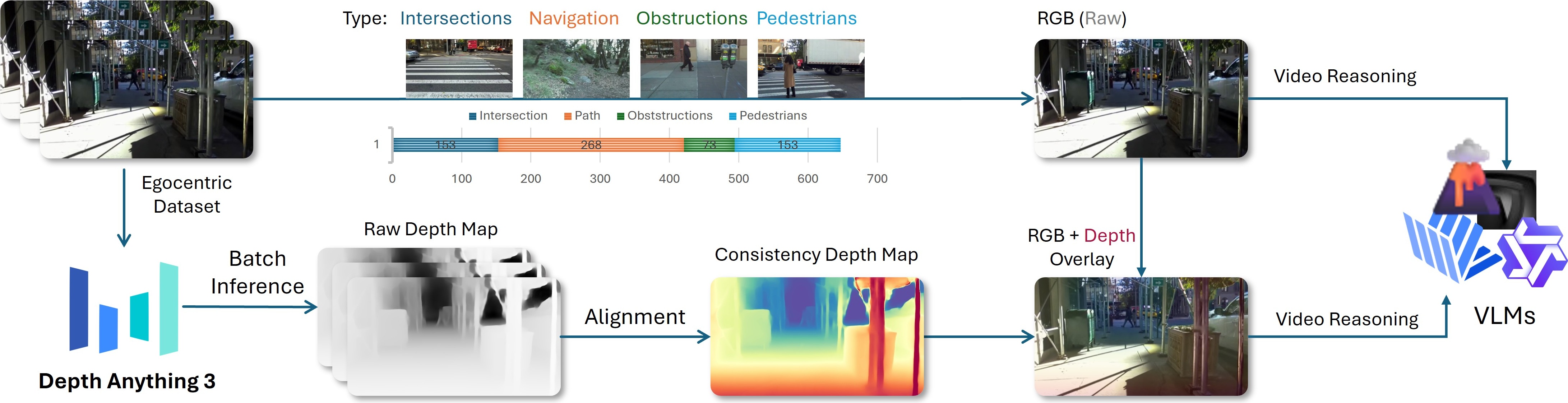
核心思路:论文的核心思路是通过显式地引入空间信号(例如深度图),增强VLM对视频场景空间结构的理解,从而提升其在长时第一视角视频中的空间推理能力。该方法旨在探索输入级别的归纳偏置,即通过改变输入数据的表示方式来改善模型性能,而无需修改模型架构或推理过程。
技术框架:论文的技术框架主要包括以下几个部分:1) 数据集:使用Google Sanpo数据集,并对其进行细粒度的重新标注,得到Sanpo-D数据集,用于评估VLM在导航导向的空间查询上的性能。2) 模型:选择多个VLM作为基准模型,并在Sanpo-D数据集上进行评估。3) 输入:将RGB帧与深度图融合作为VLM的输入,以提供显式的空间信息。4) 评估:设计了一系列面向导航的空间查询,用于评估VLM的空间推理能力,并分析深度信息对模型性能的影响。
关键创新:论文的关键创新在于:1) 提出了Sanpo-D数据集,这是一个专门用于评估长时第一视角视频空间推理能力的数据集。2) 通过实验证明,显式空间信号(如深度图)可以显著提升VLM在安全关键任务中的性能。3) 揭示了通用精度和空间专业化之间的权衡,表明针对特定任务进行空间信息增强可以提高模型性能。
关键设计:论文的关键设计包括:1) Sanpo-D数据集的细粒度标注,使其能够支持更精确的空间查询。2) RGB帧与深度图的融合方式,如何有效地将深度信息融入到VLM的输入中(具体融合方式未知)。3) 面向导航的空间查询的设计,如何有效地评估VLM的空间推理能力(具体查询类型未知)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,通过融合深度信息,VLM在行人检测和障碍物检测等安全关键任务上的性能得到了显著提升。具体提升幅度未知,但结果强调了深度感知和空间接地的表示对于提高长时第一视角视频理解的重要性。论文揭示了通用精度和空间专业化之间的权衡。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、智能监控等领域。通过提升机器对长时第一视角视频的空间理解能力,可以提高机器人在复杂环境中的自主导航能力和安全性,例如在拥挤的街道上安全行驶,或在室内环境中避开障碍物。
📄 摘要(原文)
Long-horizon egocentric video presents significant challenges for visual navigation due to viewpoint drift and the absence of persistent geometric context. Although recent vision-language models perform well on image and short-video reasoning, their spatial reasoning capability in long egocentric sequences remains limited. In this work, we study how explicit spatial signals influence VLM-based video understanding without modifying model architectures or inference procedures. We introduce Sanpo-D, a fine-grained re-annotation of the Google Sanpo dataset, and benchmark multiple VLMs on navigation-oriented spatial queries. To examine input-level inductive bias, we further fuse depth maps with RGB frames and evaluate their impact on spatial reasoning. Our results reveal a trade-off between general-purpose accuracy and spatial specialization, showing that depth-aware and spatially grounded representations can improve performance on safety-critical tasks such as pedestrian and obstruction detection.