AnyView: Synthesizing Any Novel View in Dynamic Scenes
作者: Basile Van Hoorick, Dian Chen, Shun Iwase, Pavel Tokmakov, Muhammad Zubair Irshad, Igor Vasiljevic, Swati Gupta, Fangzhou Cheng, Sergey Zakharov, Vitor Campagnolo Guizilini
分类: cs.CV, cs.LG, cs.RO
发布日期: 2026-01-23
备注: Project webpage: https://tri-ml.github.io/AnyView/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
AnyView:提出一种基于扩散模型的动态场景任意视角合成框架
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱八:物理动画 (Physics-based Animation)
关键词: 动态场景 新视角合成 视频生成 扩散模型 时空一致性
📋 核心要点
- 现有视频生成模型难以在动态场景中保持多视角和时空一致性,限制了其在复杂环境中的应用。
- AnyView利用扩散模型和多源数据,学习通用的时空隐式表示,从而实现任意视角的动态场景视频生成。
- AnyView在标准基准上表现出竞争力,并在新提出的AnyViewBench基准上显著优于现有方法。
📝 摘要(中文)
现代生成视频模型在生成令人信服的高质量输出方面表现出色,但难以在高度动态的真实环境中保持多视角和时空一致性。本文提出了AnyView,一个基于扩散的视频生成框架,用于动态视角合成,具有最小的归纳偏置或几何假设。我们利用具有不同监督级别的多个数据源,包括单目(2D)、多视角静态(3D)和多视角动态(4D)数据集,来训练一个通用的时空隐式表示,该表示能够从任意相机位置和轨迹生成零样本的新视角视频。我们在标准基准上评估AnyView,展示了与当前最先进技术相比具有竞争力的结果,并提出了AnyViewBench,这是一个具有挑战性的新基准,专门针对各种真实场景中的极端动态视角合成。在这种更极端的设置中,我们发现大多数基线的性能急剧下降,因为它们需要视角之间的大量重叠,而AnyView保持了从任何视角生成逼真、合理且时空一致的视频的能力。
🔬 方法详解
问题定义:现有方法在动态场景下进行新视角合成时,往往需要视角之间存在显著的重叠,并且难以保证生成视频的时空一致性。这限制了它们在真实世界复杂环境中的应用,尤其是在视角变化剧烈的情况下。
核心思路:AnyView的核心思路是利用扩散模型强大的生成能力,结合多视角、多类型的数据进行训练,学习一个通用的时空隐式表示。该表示能够捕捉场景的动态变化和视角关系,从而实现从任意视角生成逼真且时空一致的视频。
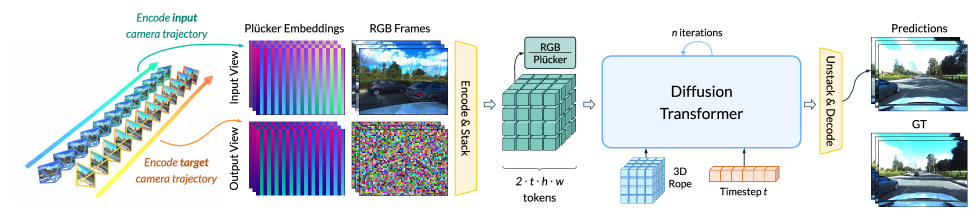
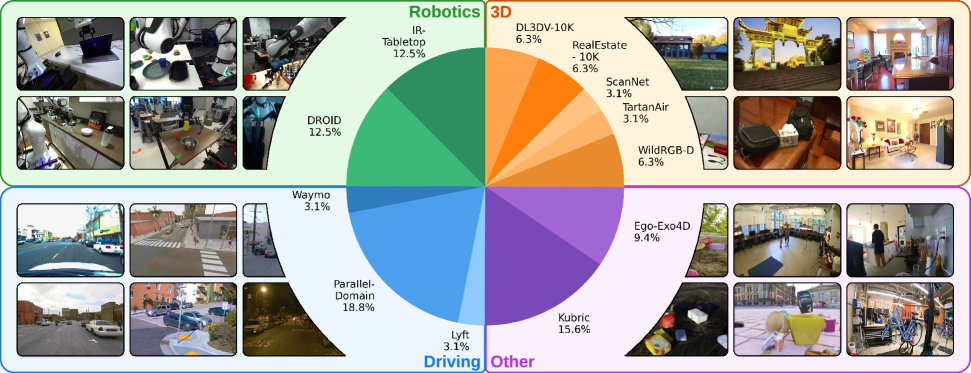
技术框架:AnyView采用基于扩散模型的视频生成框架。整体流程包括:1) 使用多视角数据训练一个时空隐式表示;2) 给定目标视角和时间,从隐式表示中采样生成视频帧;3) 使用扩散模型逐步去噪,生成最终的视频。框架利用了单目、多视角静态和多视角动态数据集,以增强模型的泛化能力。
关键创新:AnyView的关键创新在于其通用的时空隐式表示学习方法,该方法能够有效地融合不同类型的数据,并捕捉场景的动态变化和视角关系。与现有方法相比,AnyView对视角重叠的要求更低,能够生成更逼真、更时空一致的视频。
关键设计:AnyView使用了基于Transformer的网络结构来建模时空关系。损失函数包括重构损失、对抗损失和感知损失,以提高生成视频的质量和逼真度。此外,AnyView还采用了数据增强技术,例如随机视角变换和时间扭曲,以增强模型的鲁棒性。
🖼️ 关键图片
📊 实验亮点
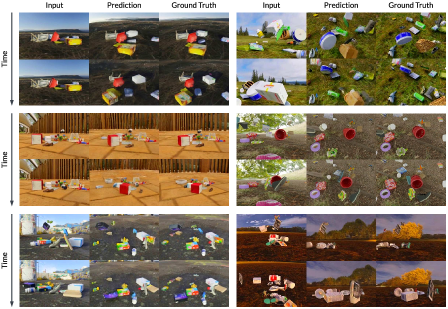
AnyView在标准基准上取得了与现有技术相当的结果。更重要的是,在作者提出的AnyViewBench基准上,AnyView显著优于其他方法,尤其是在视角变化剧烈的情况下。实验结果表明,AnyView能够生成逼真、合理且时空一致的视频,即使在视角之间没有显著重叠的情况下。
🎯 应用场景
AnyView具有广泛的应用前景,包括虚拟现实、增强现实、自动驾驶、机器人导航等领域。它可以用于生成任意视角的动态场景视频,从而为用户提供更沉浸式的体验。此外,AnyView还可以用于训练自动驾驶系统和机器人,使其能够在复杂环境中更好地感知和理解周围环境。
📄 摘要(原文)
Modern generative video models excel at producing convincing, high-quality outputs, but struggle to maintain multi-view and spatiotemporal consistency in highly dynamic real-world environments. In this work, we introduce \textbf{AnyView}, a diffusion-based video generation framework for \emph{dynamic view synthesis} with minimal inductive biases or geometric assumptions. We leverage multiple data sources with various levels of supervision, including monocular (2D), multi-view static (3D) and multi-view dynamic (4D) datasets, to train a generalist spatiotemporal implicit representation capable of producing zero-shot novel videos from arbitrary camera locations and trajectories. We evaluate AnyView on standard benchmarks, showing competitive results with the current state of the art, and propose \textbf{AnyViewBench}, a challenging new benchmark tailored towards \emph{extreme} dynamic view synthesis in diverse real-world scenarios. In this more dramatic setting, we find that most baselines drastically degrade in performance, as they require significant overlap between viewpoints, while AnyView maintains the ability to produce realistic, plausible, and spatiotemporally consistent videos when prompted from \emph{any} viewpoint. Results, data, code, and models can be viewed at: https://tri-ml.github.io/AnyView/