GPA-VGGT:Adapting VGGT to Large scale Localization by self-Supervised learning with Geometry and Physics Aware loss
作者: Yangfan Xu, Lilian Zhang, Xiaofeng He, Pengdong Wu, Wenqi Wu, Jun Mao
分类: cs.CV, cs.RO
发布日期: 2026-01-23
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于几何与物理感知损失自监督学习的GPA-VGGT,提升大规模定位能力。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 自监督学习 视觉几何 Transformer 相机姿态估计 三维重建
📋 核心要点
- 现有VGGT模型依赖真实标签训练,难以适应无标签和未见场景,限制了其在大规模环境中的应用。
- 提出GPA-VGGT,利用序列式几何约束进行自监督学习,无需真实标签即可训练VGGT模型。
- 实验表明,该模型仅需少量迭代即可收敛,并在大规模定位任务上取得显著的性能提升。
📝 摘要(中文)
基于Transformer的通用视觉几何框架在相机姿态估计和3D场景理解方面表现出良好的性能。最近,视觉几何基础Transformer(VGGT)模型的进步在相机姿态估计和3D重建方面显示出巨大的潜力。然而,这些模型通常依赖于真实标签进行训练,这给适应未标记和未见过的场景带来了挑战。在本文中,我们提出了一个自监督框架来训练带有未标记数据的VGGT,从而增强其在大规模环境中的定位能力。为了实现这一目标,我们将传统的成对关系扩展到序列式的几何约束,用于自监督学习。具体来说,在每个序列中,我们采样多个源帧,并将它们几何投影到不同的目标帧上,从而提高时间特征的一致性。我们将物理光度一致性和几何约束公式化为联合优化损失,以规避对硬标签的需求。通过使用该方法训练模型,局部和全局跨视图注意力层以及相机和深度头都可以有效地捕获潜在的多视图几何。实验表明,该模型在数百次迭代中收敛,并在大规模定位方面取得了显著的改进。我们的代码将在https://github.com/X-yangfan/GPA-VGGT上发布。
🔬 方法详解
问题定义:现有基于Transformer的视觉几何框架,如VGGT,在相机姿态估计和3D重建任务中表现出色,但依赖于大量的带有标签的数据进行训练。这限制了它们在实际应用中的部署,尤其是在缺乏标签的大规模场景中。如何利用无标签数据提升VGGT模型的定位能力是一个关键问题。
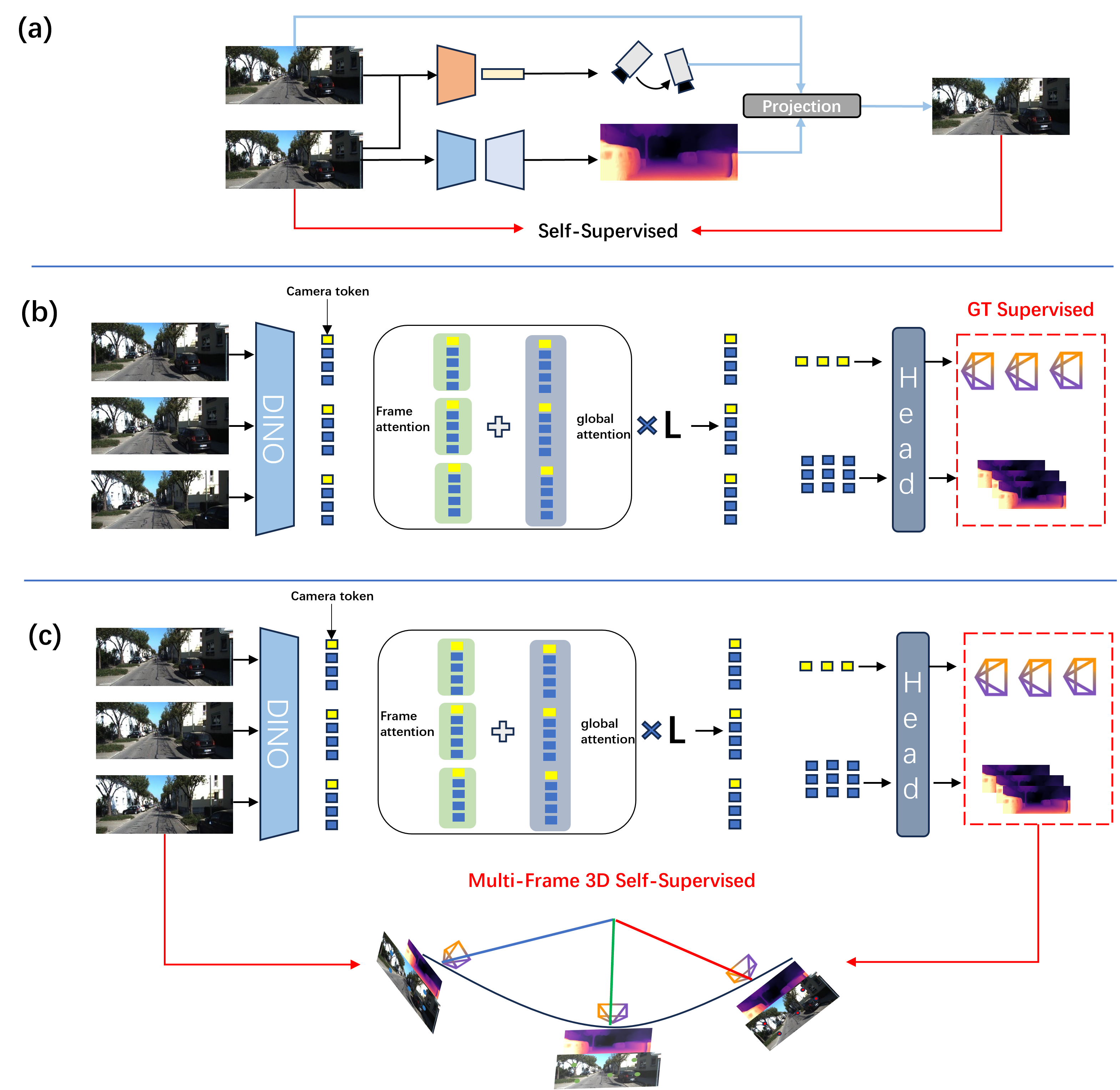
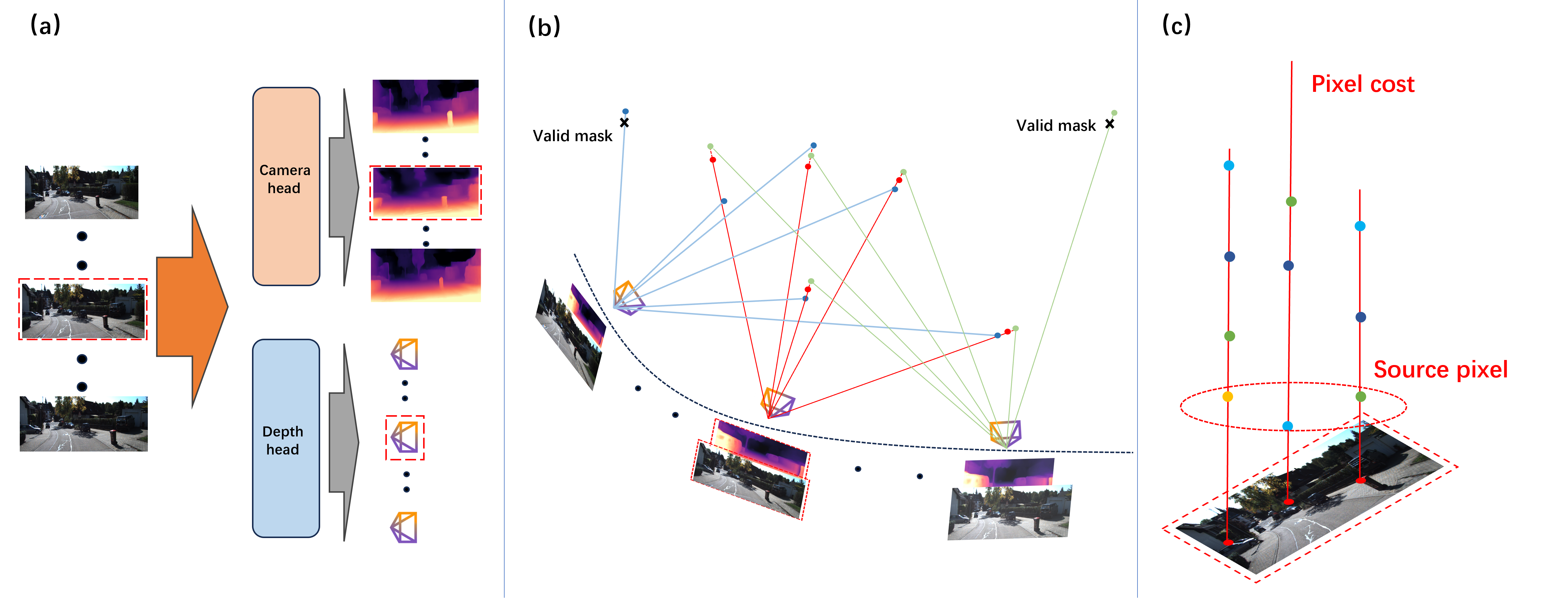
核心思路:GPA-VGGT的核心思路是利用自监督学习的方式,通过构建几何和物理约束来训练VGGT模型,从而避免对真实标签的依赖。具体来说,该方法将传统的成对关系扩展到序列式的几何约束,并利用多帧之间的几何一致性和光度一致性作为监督信号。
技术框架:GPA-VGGT的整体框架包括以下几个主要模块:1) 特征提取模块:使用VGGT模型提取图像特征。2) 几何投影模块:将多个源帧几何投影到不同的目标帧上,建立帧之间的对应关系。3) 损失函数模块:设计联合优化损失函数,包括物理光度一致性损失和几何约束损失。4) 优化模块:使用梯度下降等优化算法训练模型。
关键创新:GPA-VGGT的关键创新在于提出了基于序列式几何约束的自监督学习方法。与传统的成对关系相比,序列式约束能够更好地利用时间信息,提高特征一致性。此外,联合优化物理光度一致性损失和几何约束损失,能够更有效地训练模型,使其更好地理解多视图几何。
关键设计:在序列采样方面,需要选择合适的源帧和目标帧数量,以保证足够的几何约束。损失函数的设计需要平衡物理光度一致性损失和几何约束损失的权重。网络结构方面,可以调整VGGT模型的层数和参数,以适应不同的场景和任务。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GPA-VGGT模型在仅使用少量迭代的情况下即可收敛,并在大规模定位任务上取得了显著的性能提升。相较于依赖标签训练的VGGT模型,GPA-VGGT在无标签数据上训练后,定位精度得到了显著提高。具体性能数据未知,但摘要强调了“significant improvements”。
🎯 应用场景
GPA-VGGT具有广泛的应用前景,包括:增强现实(AR)、自动驾驶、机器人导航、三维重建、城市建模等。该方法能够利用无标签数据提升定位精度,降低对人工标注的依赖,从而加速相关技术的落地和应用。未来,可以将GPA-VGGT与其他自监督学习方法相结合,进一步提升模型的性能和泛化能力。
📄 摘要(原文)
Transformer-based general visual geometry frameworks have shown promising performance in camera pose estimation and 3D scene understanding. Recent advancements in Visual Geometry Grounded Transformer (VGGT) models have shown great promise in camera pose estimation and 3D reconstruction. However, these models typically rely on ground truth labels for training, posing challenges when adapting to unlabeled and unseen scenes. In this paper, we propose a self-supervised framework to train VGGT with unlabeled data, thereby enhancing its localization capability in large-scale environments. To achieve this, we extend conventional pair-wise relations to sequence-wise geometric constraints for self-supervised learning. Specifically, in each sequence, we sample multiple source frames and geometrically project them onto different target frames, which improves temporal feature consistency. We formulate physical photometric consistency and geometric constraints as a joint optimization loss to circumvent the requirement for hard labels. By training the model with this proposed method, not only the local and global cross-view attention layers but also the camera and depth heads can effectively capture the underlying multi-view geometry. Experiments demonstrate that the model converges within hundreds of iterations and achieves significant improvements in large-scale localization. Our code will be released at https://github.com/X-yangfan/GPA-VGGT.