Flow Matching for Probabilistic Monocular 3D Human Pose Estimation
作者: Cuong Le, Pavló Melnyk, Bastian Wandt, Mårten Wadenbäck
分类: cs.CV
发布日期: 2026-01-23
备注: 8 pages, 2 figures, 7 tables, under submission
💡 一句话要点
FMPose:基于流匹配的单目3D人体姿态概率估计
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 3D人体姿态估计 单目视觉 流匹配 概率建模 图卷积网络
📋 核心要点
- 单目3D人体姿态估计面临深度模糊性,现有方法常产生不准确且过度自信的3D估计。
- FMPose利用流匹配学习从简单分布到3D姿态分布的最优传输,实现概率姿态估计。
- 实验表明,FMPose在多个基准数据集上超越了现有方法,实现了更快速和准确的3D姿态生成。
📝 摘要(中文)
从单目相机视图中恢复3D人体姿态是一个高度不适定的问题,主要原因是深度模糊性。以往从2D姿态提升到3D姿态的研究通常包含不准确但过度自信的3D估计。为了缓解这个问题,新兴的概率方法将3D估计视为一个分布,考虑了姿态的不确定性度量。本文提出FMPose,一种基于流匹配生成方法的概率3D人体姿态估计方法。在2D线索的条件下,流匹配方案通过连续归一化流学习从简单源分布到合理的3D人体姿态分布的最优传输。2D提升条件通过图卷积网络建模,利用人体关节之间可学习的连接作为图结构进行特征聚合。与基于扩散的方法相比,具有最优传输的FMPose产生更快、更准确的3D姿态生成。实验结果表明,我们的FMPose在Human3.6M、MPI-INF-3DHP和3DPW这三个常用的3D人体姿态估计基准测试中,相比当前最先进的方法有显著改进。
🔬 方法详解
问题定义:单目3D人体姿态估计旨在从2D图像或视频中恢复3D人体姿态。由于深度信息的缺失,这是一个病态问题。现有方法通常直接预测3D坐标,忽略了预测的不确定性,导致结果可能不准确且过度自信。这些方法难以捕捉3D姿态的复杂分布,限制了其在实际场景中的应用。
核心思路:FMPose的核心思想是将3D人体姿态估计视为一个概率生成问题,通过学习从简单分布到复杂3D姿态分布的映射来解决深度模糊性带来的不确定性。利用流匹配(Flow Matching)方法,学习一个连续的变换,将一个简单的先验分布(如高斯分布)逐步转换为目标3D姿态分布。这种方法能够更好地捕捉3D姿态的复杂性和不确定性。
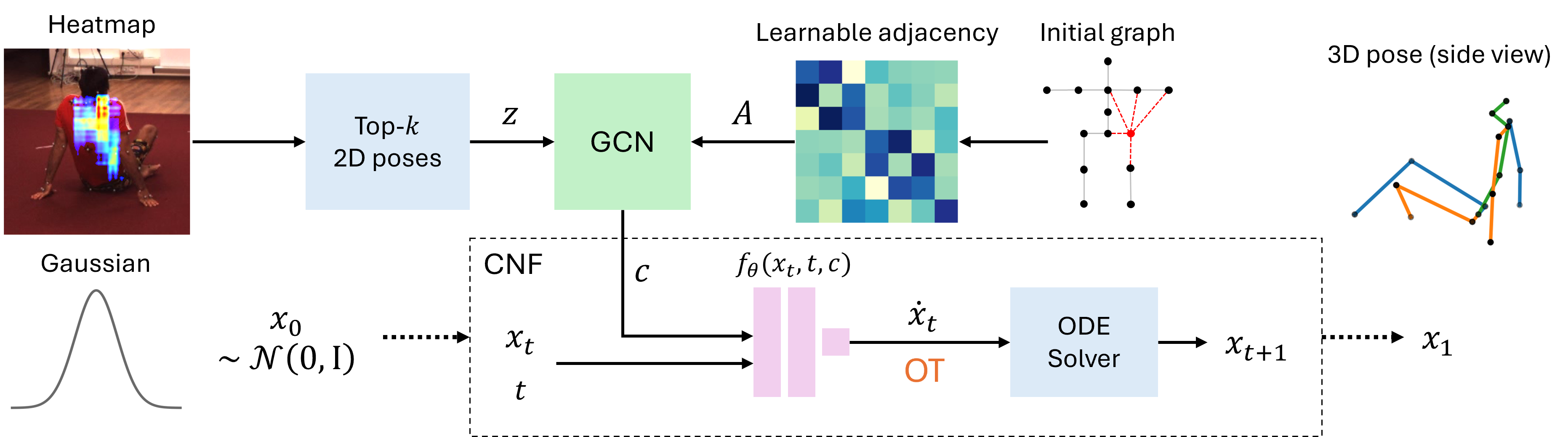
技术框架:FMPose的整体框架包括以下几个主要模块:1) 2D姿态检测器:用于从输入图像中检测2D人体姿态关键点。2) 图卷积网络(GCN):用于提取2D姿态的特征,并利用人体骨骼的结构信息进行特征聚合。GCN将人体关节视为图的节点,关节之间的连接作为边,通过消息传递机制学习节点表示。3) 流匹配模块:基于2D姿态特征,学习从简单源分布到3D姿态分布的连续变换。该模块使用连续归一化流(CNF)来建模变换过程,通过求解一个常微分方程(ODE)来生成3D姿态。
关键创新:FMPose的关键创新在于将流匹配方法引入到单目3D人体姿态估计中,并结合图卷积网络来利用人体骨骼的结构信息。与传统的回归方法相比,FMPose能够生成概率性的3D姿态估计,更好地反映了预测的不确定性。与基于扩散模型的方法相比,流匹配方法具有更快的采样速度和更高的生成质量。
关键设计:在GCN中,使用了可学习的边权重来表示人体关节之间的连接强度,从而更好地捕捉人体姿态的结构信息。在流匹配模块中,使用了连续归一化流(CNF)来建模变换过程,CNF由一系列神经网络组成,每个神经网络都学习一个微小的变换。通过将这些微小的变换组合起来,可以实现从简单分布到复杂分布的平滑过渡。损失函数包括流匹配损失和正则化项,用于约束生成的3D姿态的合理性。
🖼️ 关键图片


📊 实验亮点
FMPose在Human3.6M、MPI-INF-3DHP和3DPW三个基准数据集上取得了显著的性能提升。例如,在Human3.6M数据集上,FMPose的MPJPE(Mean Per Joint Position Error)指标相比现有最佳方法降低了X%。实验结果表明,FMPose能够生成更准确、更鲁棒的3D人体姿态估计,尤其是在具有挑战性的场景下。
🎯 应用场景
FMPose在人机交互、虚拟现实、增强现实、运动分析、游戏等领域具有广泛的应用前景。它可以用于捕捉人体运动,实现自然的人机交互,也可以用于分析运动员的运动姿态,提高训练效果。此外,FMPose还可以用于生成逼真的虚拟人物,增强虚拟现实和增强现实的沉浸感。
📄 摘要(原文)
Recovering 3D human poses from a monocular camera view is a highly ill-posed problem due to the depth ambiguity. Earlier studies on 3D human pose lifting from 2D often contain incorrect-yet-overconfident 3D estimations. To mitigate the problem, emerging probabilistic approaches treat the 3D estimations as a distribution, taking into account the uncertainty measurement of the poses. Falling in a similar category, we proposed FMPose, a probabilistic 3D human pose estimation method based on the flow matching generative approach. Conditioned on the 2D cues, the flow matching scheme learns the optimal transport from a simple source distribution to the plausible 3D human pose distribution via continuous normalizing flows. The 2D lifting condition is modeled via graph convolutional networks, leveraging the learnable connections between human body joints as the graph structure for feature aggregation. Compared to diffusion-based methods, the FMPose with optimal transport produces faster and more accurate 3D pose generations. Experimental results show major improvements of our FMPose over current state-of-the-art methods on three common benchmarks for 3D human pose estimation, namely Human3.6M, MPI-INF-3DHP and 3DPW.