A Step to Decouple Optimization in 3DGS
作者: Renjie Ding, Yaonan Wang, Min Liu, Jialin Zhu, Jiazheng Wang, Jiahao Zhao, Wenting Shen, Feixiang He, Xiang Che
分类: cs.CV
发布日期: 2026-01-23
💡 一句话要点
解耦3DGS优化:提出AdamW-GS,提升优化效率与表达能力
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D高斯溅射 新视角合成 优化算法 解耦优化 AdamW 三维重建 实时渲染
📋 核心要点
- 现有3DGS优化方法存在更新步骤耦合和梯度耦合问题,导致优化效率降低和属性更新代价高昂。
- 论文通过解耦3DGS优化过程,提出稀疏Adam、重状态正则化和解耦属性正则化等策略。
- 实验表明,重新设计的AdamW-GS优化器能够同时提升优化效率和表达能力。
📝 摘要(中文)
3D高斯溅射(3DGS)已成为实时新视角合成的强大技术。作为一种通过基元之间的梯度传播进行优化的显式表示,深度神经网络(DNNs)中广泛接受的优化方法实际上也被应用于3DGS,例如同步权重更新和具有自适应梯度的Adam。然而,考虑到3DGS中的物理意义和特定设计,3DGS的优化中存在两个被忽视的细节:(i)更新步骤耦合,导致优化器状态重新缩放和视点外部的昂贵属性更新,以及(ii)矩中的梯度耦合,可能导致欠有效或过度有效的正则化。然而,这种复杂的耦合尚未得到充分探索。在重新审视3DGS的优化之后,我们采取措施解耦它,并将该过程重新组合为:稀疏Adam、重新状态正则化和解耦属性正则化。通过在3DGS和3DGS-MCMC框架下进行的大量实验,我们的工作提供了对这些组件的更深入理解。最后,基于经验分析,我们重新设计了优化,并通过重新耦合有益的组件,提出了AdamW-GS,从而同时实现了更好的优化效率和表示有效性。
🔬 方法详解
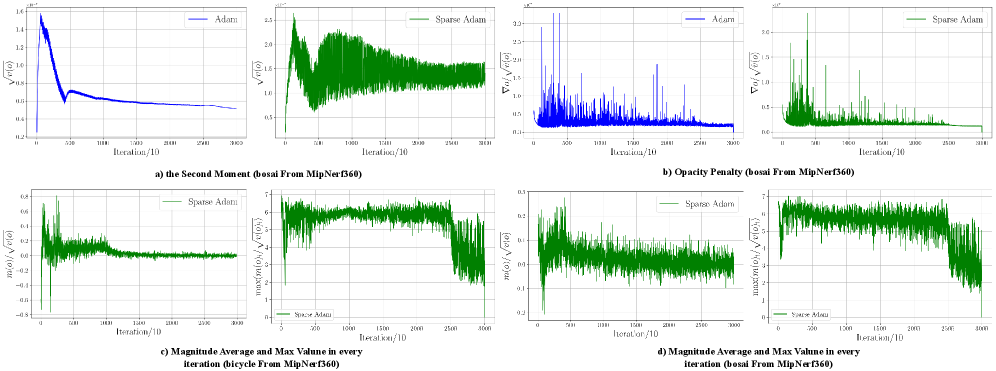
问题定义:现有3DGS优化方法直接采用DNNs中的优化策略,忽略了3DGS的物理意义和特殊设计。具体来说,更新步骤耦合导致优化器状态的重新缩放,使得视点外部的属性更新代价高昂。同时,矩中的梯度耦合可能导致欠有效或过度有效的正则化,影响模型的泛化能力。
核心思路:论文的核心思路是解耦3DGS的优化过程,将复杂的耦合关系分解为更细粒度的组件,并针对每个组件进行优化。通过解耦,可以更精确地控制优化过程,避免不必要的计算和副作用,从而提高优化效率和模型性能。
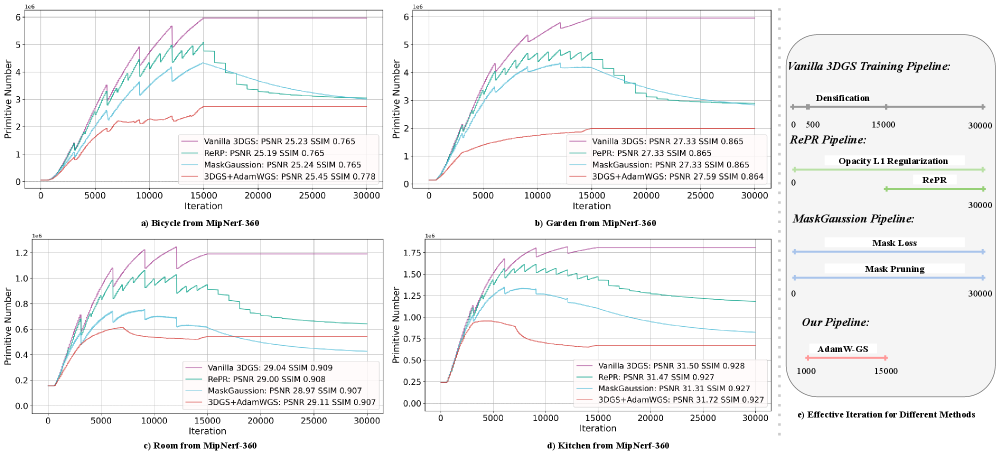
技术框架:论文提出的优化框架主要包含三个部分:Sparse Adam、Re-State Regularization和Decoupled Attribute Regularization。Sparse Adam旨在减少不必要的计算,Re-State Regularization用于调整优化器状态,Decoupled Attribute Regularization用于更有效地正则化模型参数。最终,论文将这些组件重新耦合,提出了AdamW-GS优化器。
关键创新:论文的关键创新在于对3DGS优化过程的解耦和重构。通过分析现有优化方法的不足,论文提出了针对性的解决方案,并将其整合到一个统一的优化框架中。这种解耦的思想可以为其他基于梯度的优化问题提供借鉴。
关键设计:AdamW-GS优化器是论文的关键设计。它结合了Sparse Adam、Re-State Regularization和Decoupled Attribute Regularization的优点,并重新耦合了这些组件。具体的参数设置和损失函数细节在论文中有详细描述,例如如何实现稀疏更新,如何调整正则化强度等。
🖼️ 关键图片
📊 实验亮点
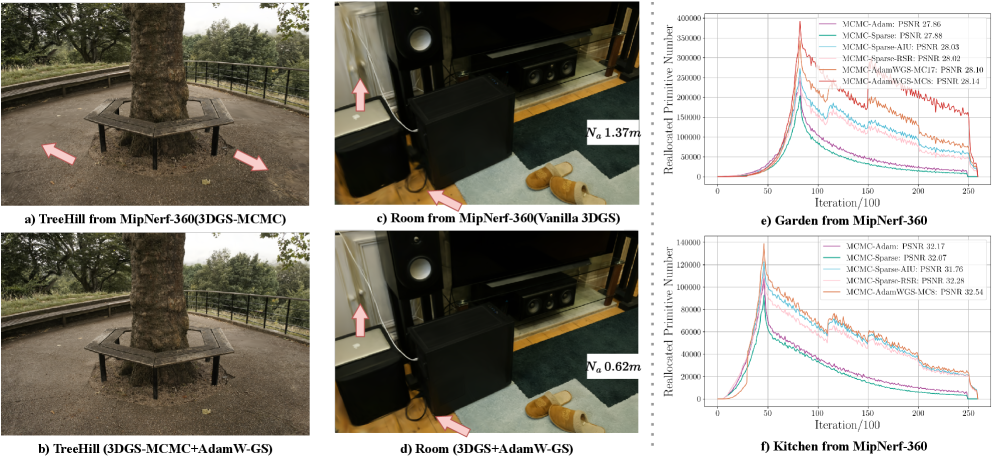
论文在3DGS和3DGS-MCMC框架下进行了大量实验,验证了所提出方法的有效性。实验结果表明,AdamW-GS优化器能够显著提高优化效率和表达能力。具体性能提升数据(例如PSNR、SSIM等指标)以及与现有基线方法的对比结果在论文中有详细展示。
🎯 应用场景
该研究成果可广泛应用于实时新视角合成、三维重建、虚拟现实、增强现实等领域。通过提高3DGS的优化效率和表达能力,可以实现更高质量、更逼真的三维场景渲染,为用户带来更好的沉浸式体验。此外,该研究提出的解耦优化思想也可以应用于其他基于梯度的优化问题。
📄 摘要(原文)
3D Gaussian Splatting (3DGS) has emerged as a powerful technique for real-time novel view synthesis. As an explicit representation optimized through gradient propagation among primitives, optimization widely accepted in deep neural networks (DNNs) is actually adopted in 3DGS, such as synchronous weight updating and Adam with the adaptive gradient. However, considering the physical significance and specific design in 3DGS, there are two overlooked details in the optimization of 3DGS: (i) update step coupling, which induces optimizer state rescaling and costly attribute updates outside the viewpoints, and (ii) gradient coupling in the moment, which may lead to under- or over-effective regularization. Nevertheless, such a complex coupling is under-explored. After revisiting the optimization of 3DGS, we take a step to decouple it and recompose the process into: Sparse Adam, Re-State Regularization and Decoupled Attribute Regularization. Taking a large number of experiments under the 3DGS and 3DGS-MCMC frameworks, our work provides a deeper understanding of these components. Finally, based on the empirical analysis, we re-design the optimization and propose AdamW-GS by re-coupling the beneficial components, under which better optimization efficiency and representation effectiveness are achieved simultaneously.