X-Aligner: Composed Visual Retrieval without the Bells and Whistles
作者: Yuqian Zheng, Mariana-Iuliana Georgescu
分类: cs.CV
发布日期: 2026-01-23
备注: 8 pages
💡 一句话要点
提出X-Aligner,用于组合视频检索,无需复杂设计即可达到SOTA
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 组合视频检索 视觉语言模型 交叉注意力 多模态融合 零样本学习
📋 核心要点
- 现有组合视频检索方法通常采用单阶段多模态融合,效果提升有限,未能充分利用视觉和文本信息。
- 提出X-Aligner模块,通过多层交叉注意力逐步融合视觉和文本特征,并与目标视频对齐,增强多模态表示。
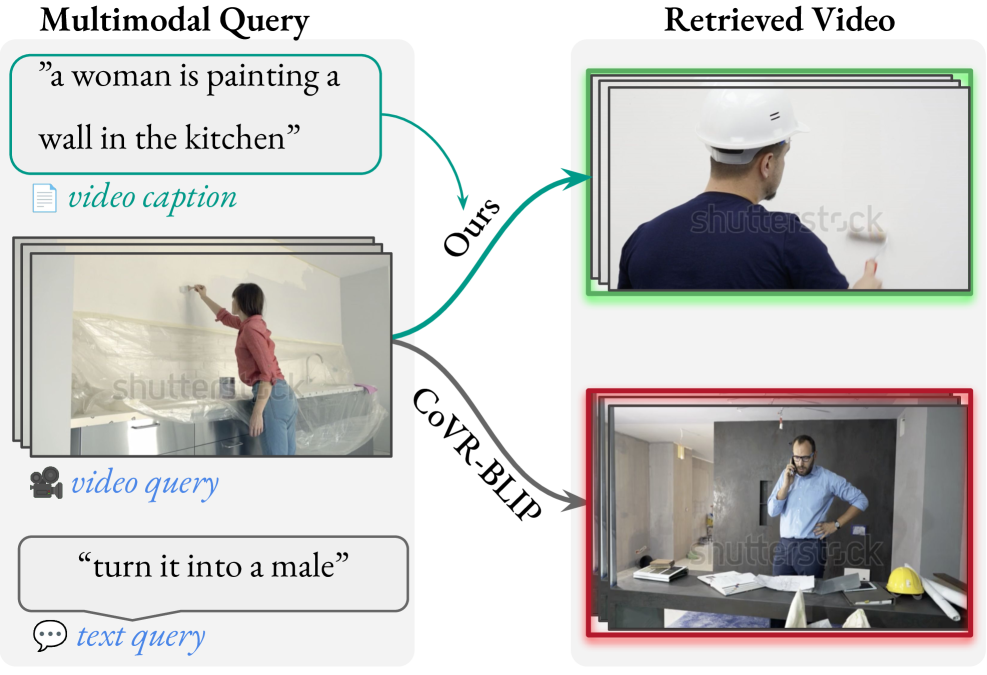
- 在Webvid-CoVR数据集上达到SOTA,Recall@1为63.93%,并在CIR数据集上展现出强大的零样本泛化能力。
📝 摘要(中文)
组合视频检索(CoVR)通过结合视觉和文本查询来实现视频检索。然而,现有的CoVR框架通常在单阶段融合多模态输入,相对于初始基线仅获得边际收益。为了解决这个问题,我们提出了一种新的CoVR框架,该框架利用了视觉语言模型(VLM)的表征能力。我们的框架包含一个新颖的交叉注意力模块X-Aligner,它由交叉注意力层组成,这些层逐步融合视觉和文本输入,并将它们的多模态表示与目标视频的表示对齐。为了进一步增强多模态查询的表示,我们结合了视觉查询的标题作为额外的输入。该框架分两个阶段进行训练,以保留预训练的VLM表示。在第一阶段,仅训练新引入的模块,而在第二阶段,文本查询编码器也进行微调。我们在BLIP系列架构(即BLIP和BLIP-2)之上实现了我们的框架,并在Webvid-CoVR数据集上对其进行训练。除了在Webvid-CoVR-Test上进行领域内评估外,我们还在组合图像检索(CIR)数据集CIRCO和Fashion-IQ上进行了零样本评估。我们的框架在CoVR上实现了最先进的性能,在Webvid-CoVR-Test上获得了63.93%的Recall@1,并展示了在CIR任务上的强大零样本泛化能力。
🔬 方法详解
问题定义:论文旨在解决组合视频检索(CoVR)任务中,现有方法多模态融合不充分,导致检索性能提升有限的问题。现有方法通常采用单阶段融合视觉和文本查询,无法有效利用预训练视觉语言模型(VLM)的强大表征能力,并且缺乏对多模态特征的有效对齐。
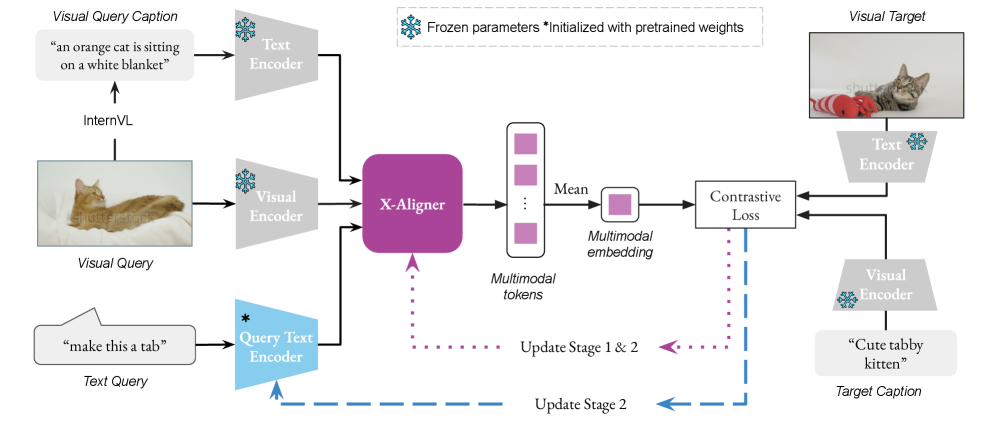
核心思路:论文的核心思路是利用VLM的预训练知识,并设计一个专门的交叉注意力模块X-Aligner,逐步融合视觉和文本查询,并将融合后的多模态表示与目标视频的表示对齐。通过这种方式,可以更有效地利用VLM的表征能力,并提高检索性能。同时,将视觉查询的caption作为额外输入,进一步增强多模态查询的表示。
技术框架:整体框架基于BLIP或BLIP-2等VLM架构。首先,使用VLM对视觉和文本查询进行编码。然后,将编码后的视觉和文本特征输入到X-Aligner模块中进行多层交叉注意力融合。最后,将融合后的多模态表示与目标视频的表示进行匹配,计算相似度得分。框架采用两阶段训练策略:第一阶段固定VLM参数,仅训练X-Aligner模块;第二阶段微调文本查询编码器。
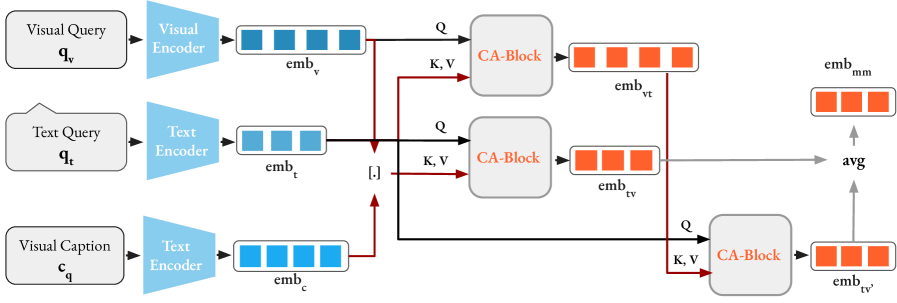
关键创新:论文的关键创新在于提出了X-Aligner模块,该模块通过多层交叉注意力机制,逐步融合视觉和文本特征,并与目标视频对齐。与现有方法的单阶段融合相比,X-Aligner能够更有效地利用VLM的表征能力,并实现更好的多模态特征对齐。此外,将视觉查询的caption作为额外输入也是一个创新点,可以进一步增强多模态查询的表示。
关键设计:X-Aligner模块由多个交叉注意力层组成,每个交叉注意力层计算视觉和文本特征之间的注意力权重,并根据权重对特征进行加权融合。训练过程中,采用两阶段训练策略,以保留预训练VLM的知识。损失函数未知,但推测是基于对比学习或排序学习的损失函数,用于优化多模态表示的对齐。
🖼️ 关键图片
📊 实验亮点
该框架在Webvid-CoVR-Test数据集上取得了63.93%的Recall@1,达到了SOTA水平。此外,该框架在CIRCO和Fashion-IQ数据集上进行了零样本评估,也取得了良好的效果,表明其具有很强的泛化能力。相较于现有方法,该框架在CoVR任务上取得了显著的性能提升。
🎯 应用场景
该研究成果可应用于视频搜索、智能推荐、内容理解等领域。例如,用户可以通过上传一张图片并输入一段文字描述,快速找到相关的视频内容。该技术还可以用于电商平台,帮助用户根据商品图片和描述找到相似的商品视频介绍。未来,该技术有望进一步扩展到更广泛的多模态检索和理解任务中。
📄 摘要(原文)
Composed Video Retrieval (CoVR) facilitates video retrieval by combining visual and textual queries. However, existing CoVR frameworks typically fuse multimodal inputs in a single stage, achieving only marginal gains over initial baseline. To address this, we propose a novel CoVR framework that leverages the representational power of Vision Language Models (VLMs). Our framework incorporates a novel cross-attention module X-Aligner, composed of cross-attention layers that progressively fuse visual and textual inputs and align their multimodal representation with that of the target video. To further enhance the representation of the multimodal query, we incorporate the caption of the visual query as an additional input. The framework is trained in two stages to preserve the pretrained VLM representation. In the first stage, only the newly introduced module is trained, while in the second stage, the textual query encoder is also fine-tuned. We implement our framework on top of BLIP-family architecture, namely BLIP and BLIP-2, and train it on the Webvid-CoVR data set. In addition to in-domain evaluation on Webvid-CoVR-Test, we perform zero-shot evaluations on the Composed Image Retrieval (CIR) data sets CIRCO and Fashion-IQ. Our framework achieves state-of-the-art performance on CoVR obtaining a Recall@1 of 63.93% on Webvid-CoVR-Test, and demonstrates strong zero-shot generalization on CIR tasks.