OnlineSI: Taming Large Language Model for Online 3D Understanding and Grounding
作者: Zixian Liu, Zhaoxi Chen, Liang Pan, Ziwei Liu
分类: cs.CV
发布日期: 2026-01-23
备注: Project Page: https://onlinesi.github.io/
💡 一句话要点
提出OnlineSI框架,利用大语言模型实现持续在线的3D场景理解与定位
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 3D场景理解 在线学习 具身智能 空间记忆 点云处理 语义分割
📋 核心要点
- 现有方法难以使MLLM在动态环境中持续工作,限制了其在具身系统中的应用。
- OnlineSI通过维护有限的空间记忆,结合3D点云和语义信息,实现对环境的持续理解。
- 实验表明,OnlineSI在空间理解和定位任务上表现出色,为具身智能提供了新思路。
📝 摘要(中文)
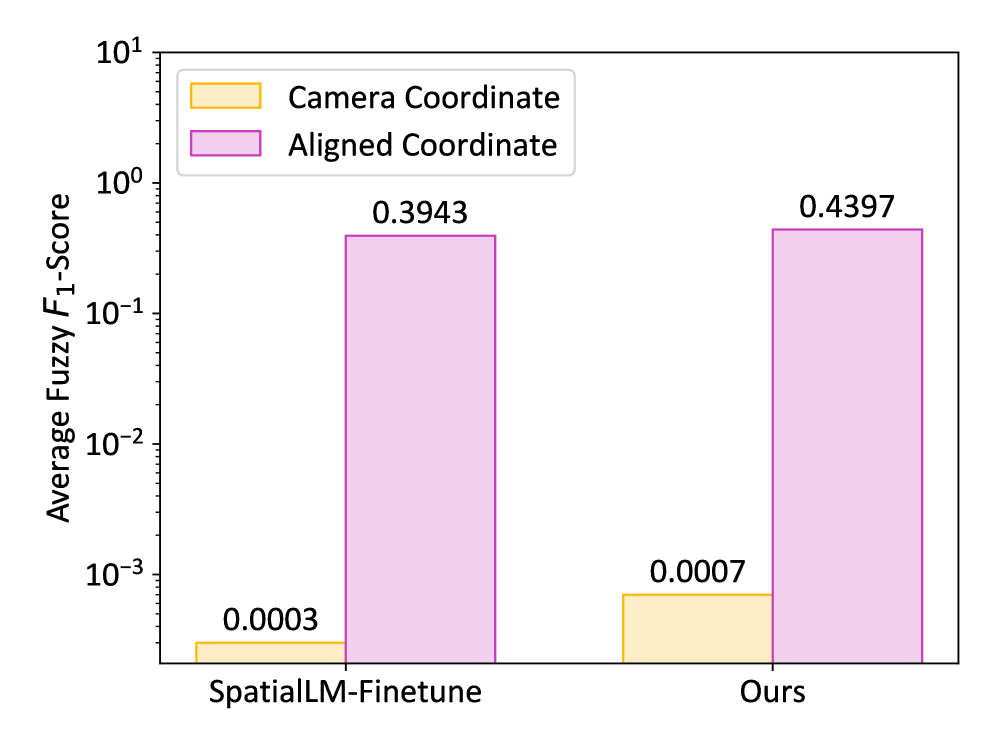
本文提出OnlineSI框架,旨在使多模态大语言模型(MLLM)具备空间理解和推理能力,并能持续适应不断变化的环境。现有方法忽略了在动态环境中持续工作的能力,并且难以部署到真实世界的具身系统中。OnlineSI通过维护有限的空间记忆来保留过去的观测信息,确保每次推理所需的计算量不会随着输入的累积而增加。此外,该方法还集成了3D点云信息和语义信息,帮助MLLM更好地定位和识别场景中的物体。为了评估该方法,本文引入了模糊$F_1$-Score来缓解歧义,并在两个代表性数据集上进行了测试。实验结果表明了该方法的有效性,为真实世界的具身系统铺平了道路。
🔬 方法详解
问题定义:现有方法在利用多模态大语言模型进行3D场景理解时,通常忽略了环境的动态变化,无法持续地处理视频流输入。此外,计算复杂度会随着输入数据的增加而线性增长,限制了其在资源受限的具身系统上的部署。因此,需要一种能够在线处理、保持计算效率并有效融合3D信息的框架。
核心思路:OnlineSI的核心在于维护一个有限大小的空间记忆,用于存储过去的关键观测信息。通过这种方式,模型可以在不增加计算负担的前提下,利用历史信息进行推理。同时,将3D点云信息与语义信息融合,增强模型对场景的理解和定位能力。
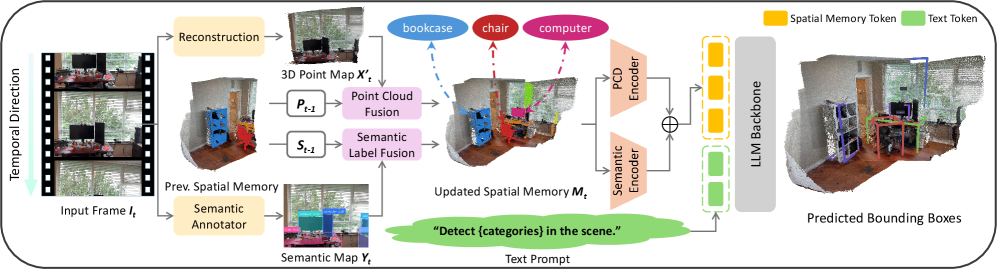
技术框架:OnlineSI框架主要包含以下几个阶段:1) 视频流输入:接收来自传感器的视频流数据。2) 3D重建与语义分割:利用视频流重建3D点云,并进行语义分割,提取场景中的物体信息。3) 空间记忆维护:维护一个固定大小的空间记忆,存储关键帧的3D点云和语义信息。4) MLLM推理:将当前帧的3D点云、语义信息以及空间记忆中的信息输入到MLLM中,进行空间理解和定位。
关键创新:OnlineSI的关键创新在于:1) 提出了一种在线处理3D场景理解任务的框架,能够处理连续的视频流输入。2) 通过维护有限大小的空间记忆,解决了计算复杂度随输入数据增加而增长的问题。3) 融合了3D点云和语义信息,增强了MLLM对场景的理解能力。
关键设计:空间记忆的大小是一个关键参数,需要根据具体的应用场景进行调整。损失函数的设计需要考虑3D重建的精度、语义分割的准确性以及MLLM的推理效果。此外,如何选择关键帧并更新空间记忆也是一个重要的设计考虑。
🖼️ 关键图片
📊 实验亮点
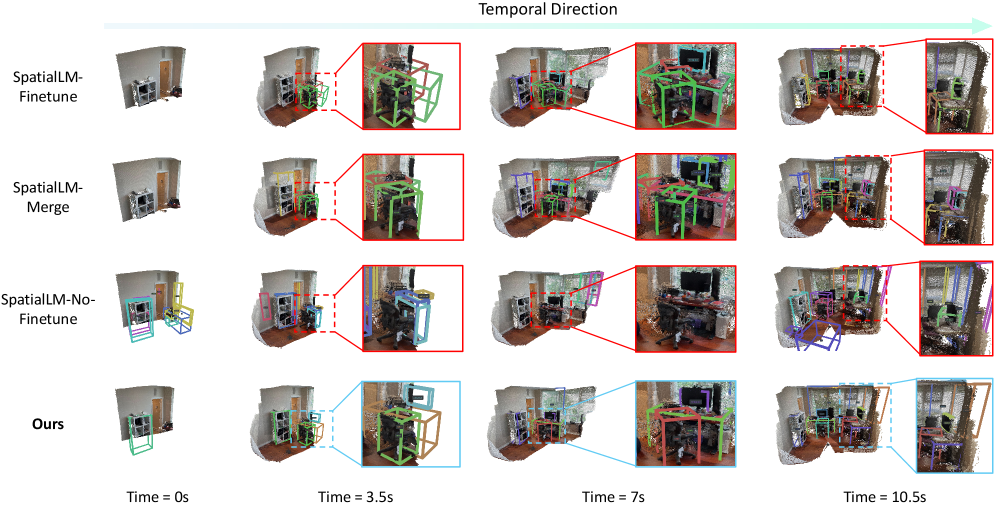
实验结果表明,OnlineSI在两个代表性数据集上取得了显著的性能提升。为了更准确地评估模型的性能,论文引入了模糊$F_1$-Score来缓解歧义。具体的数据提升幅度未知,但实验结果验证了OnlineSI框架的有效性,证明了其在在线3D场景理解和定位方面的优势。
🎯 应用场景
OnlineSI框架具有广泛的应用前景,例如:机器人导航、增强现实、智能家居、自动驾驶等。它可以帮助机器人更好地理解周围环境,从而实现更智能的交互和决策。在增强现实领域,可以提供更精确的场景理解和物体定位,提升用户体验。在智能家居中,可以实现更智能的设备控制和场景管理。
📄 摘要(原文)
In recent years, researchers have increasingly been interested in how to enable Multimodal Large Language Models (MLLM) to possess spatial understanding and reasoning capabilities. However, most existing methods overlook the importance of the ability to continuously work in an ever-changing world, and lack the possibility of deployment on embodied systems in real-world environments. In this work, we introduce OnlineSI, a framework that can continuously improve its spatial understanding of its surroundings given a video stream. Our core idea is to maintain a finite spatial memory to retain past observations, ensuring the computation required for each inference does not increase as the input accumulates. We further integrate 3D point cloud information with semantic information, helping MLLM to better locate and identify objects in the scene. To evaluate our method, we introduce the Fuzzy $F_1$-Score to mitigate ambiguity, and test our method on two representative datasets. Experiments demonstrate the effectiveness of our method, paving the way towards real-world embodied systems.