SALAD: Achieve High-Sparsity Attention via Efficient Linear Attention Tuning for Video Diffusion Transformer
作者: Tongcheng Fang, Hanling Zhang, Ruiqi Xie, Zhuo Han, Xin Tao, Tianchen Zhao, Pengfei Wan, Wenbo Ding, Wanli Ouyang, Xuefei Ning, Yu Wang
分类: cs.CV
发布日期: 2026-01-23
💡 一句话要点
提出SALAD以解决视频生成中的高计算复杂度问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视频生成 扩散变换器 稀疏注意力 线性注意力 高效推理 计算机视觉 深度学习
📋 核心要点
- 现有的稀疏注意力机制在稀疏性和计算效率上存在局限,导致视频生成的计算延迟较高。
- SALAD通过并行引入轻量级线性注意力分支,并结合输入依赖的门控机制,优化了注意力计算。
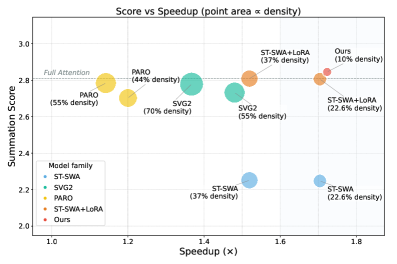
- 实验结果表明,SALAD实现了90%的稀疏性和1.72倍的推理速度提升,同时生成质量与完全注意力基线相当。
📝 摘要(中文)
扩散变换器在视频生成中表现出色,但由于输入序列的长度,完全注意力机制导致了高计算延迟。现有的稀疏注意力机制虽然有所改进,但训练过程复杂且数据需求高。本文提出SALAD,通过引入轻量级线性注意力分支并结合输入依赖的门控机制,实现了90%的稀疏性和1.72倍的推理加速,同时保持了与完全注意力基线相当的生成质量。我们的微调过程高效,仅需2000个视频样本和1600个训练步骤。
🔬 方法详解
问题定义:本文旨在解决扩散变换器在视频生成中因输入序列长导致的高计算复杂度问题。现有的稀疏注意力机制虽然能提高效率,但在稀疏性和训练需求上存在不足。
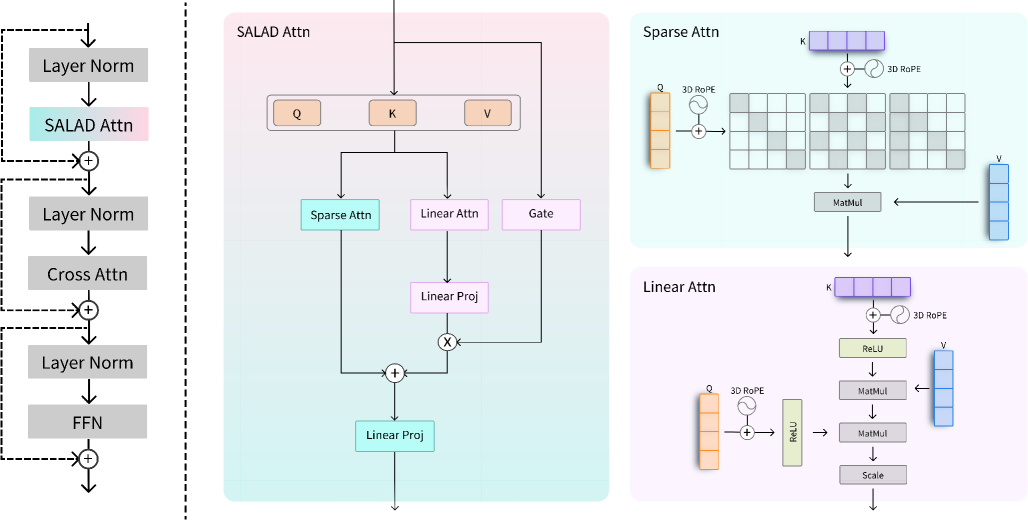
核心思路:SALAD的核心思路是引入一个轻量级的线性注意力分支,与稀疏注意力并行工作,通过输入依赖的门控机制来平衡两者的贡献,从而实现高效的注意力计算。
技术框架:SALAD的整体架构包括两个主要分支:稀疏注意力分支和线性注意力分支。输入数据通过门控机制动态调整两者的权重,以实现高稀疏性和快速推理。
关键创新:SALAD的主要创新在于其轻量级线性注意力分支的引入,以及输入依赖的门控机制,这使得模型在保持生成质量的同时,显著提升了推理速度和稀疏性。
关键设计:在设计中,SALAD仅需2000个视频样本和1600个训练步骤,使用批量大小为8的设置进行微调,确保了训练过程的高效性。
🖼️ 关键图片

📊 实验亮点
SALAD在实验中实现了90%的稀疏性和1.72倍的推理速度提升,与完全注意力基线相比,生成质量保持一致。这一结果表明,SALAD在高效视频生成任务中具有显著的优势,能够有效降低计算成本。
🎯 应用场景
SALAD的研究成果在视频生成、计算机视觉和人工智能等领域具有广泛的应用潜力。其高效的注意力机制可用于实时视频处理、增强现实和虚拟现实等场景,推动相关技术的发展与应用。未来,SALAD的设计思路可能会影响更多的深度学习模型,尤其是在处理长序列数据时。
📄 摘要(原文)
Diffusion Transformers have recently demonstrated remarkable performance in video generation. However, the long input sequences result in high computational latency due to the quadratic complexity of full attention. Various sparse attention mechanisms have been proposed. Training-free sparse attention is constrained by limited sparsity and thus offers modest acceleration, whereas training-based methods can reach much higher sparsity but demand substantial data and computation for training. In this work, we propose SALAD, introducing a lightweight linear attention branch in parallel with the sparse attention. By incorporating an input-dependent gating mechanism to finely balance the two branches, our method attains 90% sparsity and 1.72x inference speedup, while maintaining generation quality comparable to the full attention baseline. Moreover, our finetuning process is highly efficient, requiring only 2,000 video samples and 1,600 training steps with a batch size of 8.