Emotion-LLaMAv2 and MMEVerse: A New Framework and Benchmark for Multimodal Emotion Understanding
作者: Xiaojiang Peng, Jingyi Chen, Zebang Cheng, Bao Peng, Fengyi Wu, Yifei Dong, Shuyuan Tu, Qiyu Hu, Huiting Huang, Yuxiang Lin, Jun-Yan He, Kai Wang, Zheng Lian, Zhi-Qi Cheng
分类: cs.CV, cs.AI
发布日期: 2026-01-23
💡 一句话要点
Emotion-LLaMAv2:多模态情感理解的端到端框架与基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态情感理解 大型语言模型 指令微调 多视角编码器 特征预融合
📋 核心要点
- 现有MLLM在情感推理方面能力不足,且缺乏大规模高质量情感标注数据集和标准化评估基准。
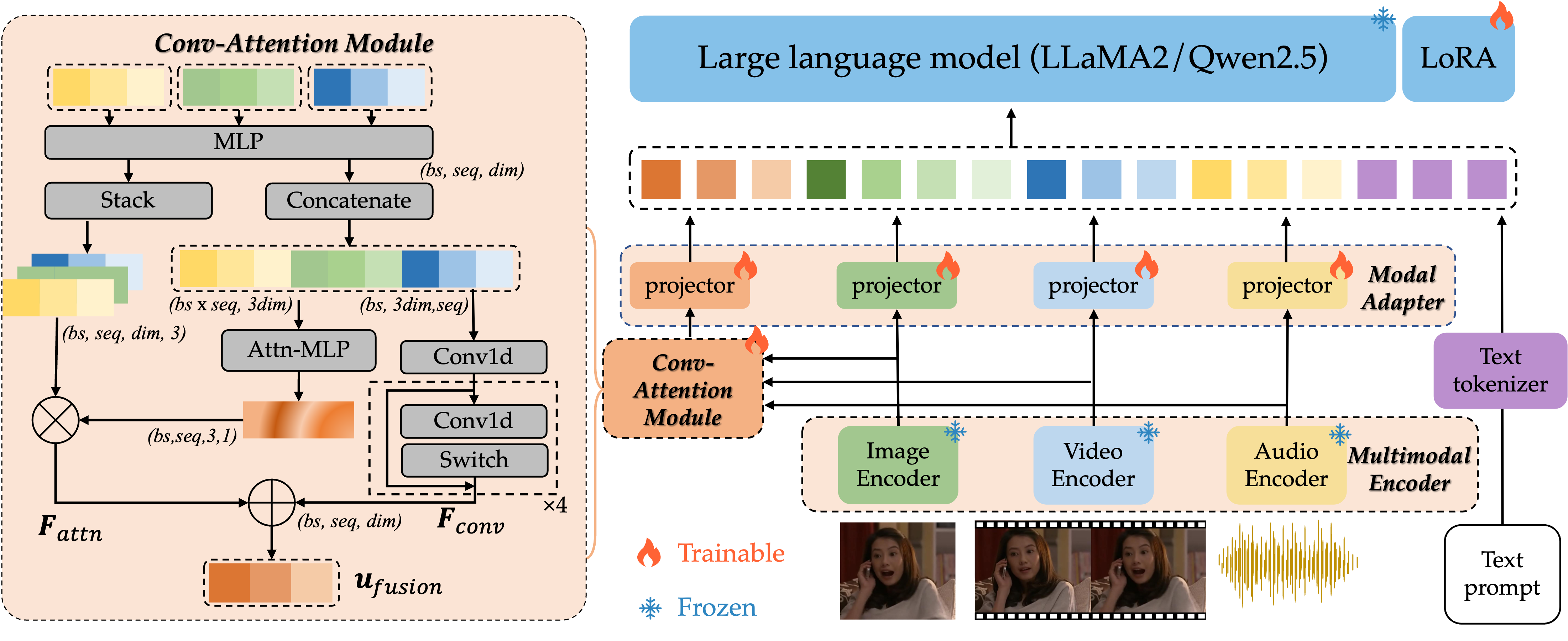
- Emotion-LLaMAv2通过端到端多视角编码器、Conv Attention预融合模块和感知到认知的课程指令微调方案,提升情感理解能力。
- MMEVerse基准整合多个数据集并重新标注,提供大规模训练数据和标准化评估,促进情感理解研究。
📝 摘要(中文)
本文提出Emotion-LLaMAv2框架和MMEVerse基准,旨在解决多模态情感理解中的挑战。现有方法在情感推理方面能力有限,缺乏高质量、大规模情感标注数据集和标准化评估基准。Emotion-LLaMAv2通过引入端到端的多视角编码器,消除了对外部人脸检测器的依赖,并通过更丰富的时空多视角tokens捕捉细微的情感线索。同时,设计了Conv Attention预融合模块,实现了LLM backbone外部的局部和全局多模态特征交互。此外,在LLaMA2 backbone中采用了一种感知到认知的课程指令微调方案,统一了情感识别和自由形式的情感推理。MMEVerse基准整合了IEMOCAP、MELD、DFEW和MAFW等十二个公开情感数据集,并通过Qwen2 Audio、Qwen2.5 VL和GPT 4o等多智能体流水线进行重新标注,生成了包含13万个训练片段和3.6万个测试片段的数据集,涵盖18个评估基准。
🔬 方法详解
问题定义:多模态情感理解旨在从视觉、听觉等多种信号中理解人类情感。现有方法依赖于外部人脸检测器,融合策略隐式,训练数据质量和规模有限,导致情感推理能力不足。
核心思路:Emotion-LLaMAv2的核心思路是构建一个端到端的框架,通过多视角编码器捕捉细微的情感线索,利用预融合模块实现多模态特征的有效交互,并采用课程学习的方式提升模型的情感推理能力。这样设计的目的是为了消除对外部模块的依赖,增强模型的鲁棒性和泛化能力。
技术框架:Emotion-LLaMAv2框架主要包含三个模块:1) 端到端多视角编码器,用于提取多模态特征;2) Conv Attention预融合模块,用于融合多模态特征;3) LLaMA2 backbone,用于情感识别和推理。整个流程是先通过多视角编码器提取特征,然后通过预融合模块进行特征融合,最后输入到LLaMA2 backbone进行情感识别和推理。
关键创新:Emotion-LLaMAv2的关键创新在于:1) 提出了端到端的多视角编码器,无需外部人脸检测器;2) 设计了Conv Attention预融合模块,实现了局部和全局多模态特征的有效交互;3) 采用了感知到认知的课程指令微调方案,统一了情感识别和自由形式的情感推理。与现有方法相比,Emotion-LLaMAv2更加简洁高效,且具有更强的情感推理能力。
关键设计:多视角编码器使用多个卷积层和Transformer层提取时空特征。Conv Attention预融合模块使用卷积操作提取局部特征,使用Attention机制提取全局特征。课程指令微调方案包含多个阶段,从简单到复杂,逐步提升模型的情感理解能力。损失函数包括交叉熵损失和对比学习损失,用于优化情感识别和推理性能。具体参数设置细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
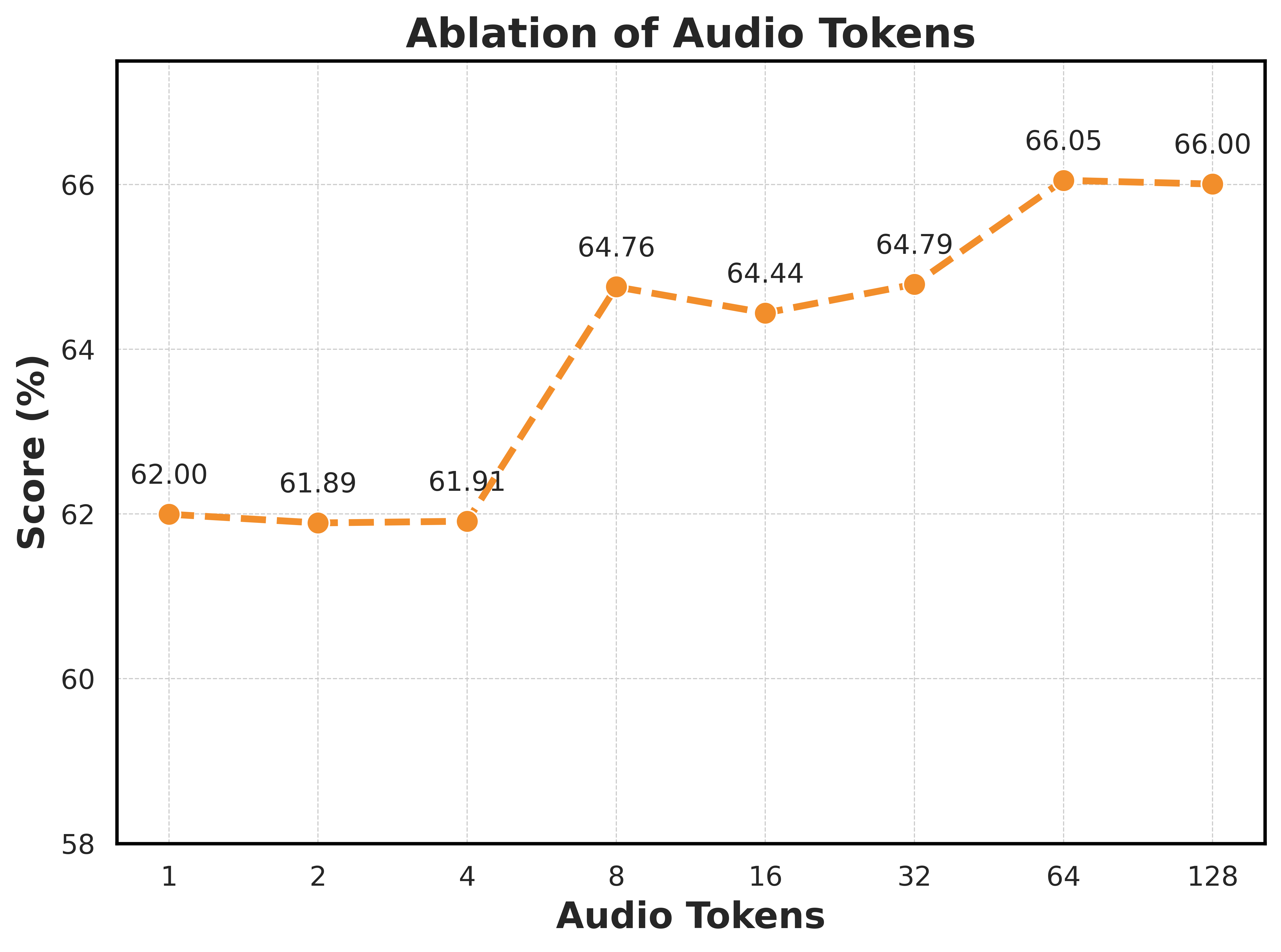
MMEVerse基准包含13万训练片段和3.6万测试片段,涵盖18个评估基准。Emotion-LLaMAv2在多个情感识别和推理任务上取得了显著的性能提升,表明了其有效性和优越性。具体的性能数据和对比基线在论文中有详细展示。
🎯 应用场景
该研究成果可应用于人机交互、情感计算、心理健康监测等领域。例如,在人机交互中,机器人可以根据用户的情感状态做出相应的反应,提高交互的自然性和流畅性。在心理健康监测中,可以通过分析用户的语音、面部表情等信息,及时发现潜在的心理问题。
📄 摘要(原文)
Understanding human emotions from multimodal signals poses a significant challenge in affective computing and human-robot interaction. While multimodal large language models (MLLMs) have excelled in general vision-language tasks, their capabilities in emotional reasoning remain limited. The field currently suffers from a scarcity of large-scale datasets with high-quality, descriptive emotion annotations and lacks standardized benchmarks for evaluation. Our preliminary framework, Emotion-LLaMA, pioneered instruction-tuned multimodal learning for emotion reasoning but was restricted by explicit face detectors, implicit fusion strategies, and low-quality training data with limited scale. To address these limitations, we present Emotion-LLaMAv2 and the MMEVerse benchmark, establishing an end-to-end pipeline together with a standardized evaluation setting for emotion recognition and reasoning. Emotion-LLaMAv2 introduces three key advances. First, an end-to-end multiview encoder eliminates external face detection and captures nuanced emotional cues via richer spatial and temporal multiview tokens. Second, a Conv Attention pre-fusion module is designed to enable simultaneous local and global multimodal feature interactions external to the LLM backbone. Third, a perception-to-cognition curriculum instruction tuning scheme within the LLaMA2 backbone unifies emotion recognition and free-form emotion reasoning. To support large-scale training and reproducible evaluation, MMEVerse aggregates twelve publicly available emotion datasets, including IEMOCAP, MELD, DFEW, and MAFW, into a unified multimodal instruction format. The data are re-annotated via a multi-agent pipeline involving Qwen2 Audio, Qwen2.5 VL, and GPT 4o, producing 130k training clips and 36k testing clips across 18 evaluation benchmarks.