ResAgent: Entropy-based Prior Point Discovery and Visual Reasoning for Referring Expression Segmentation
作者: Yihao Wang, Jusheng Zhang, Ziyi Tang, Keze Wang, Meng Yang
分类: cs.CV, cs.AI
发布日期: 2026-01-23
备注: 23 pages, 7gigures
💡 一句话要点
ResAgent:提出基于熵的先验点发现和视觉推理方法,用于指代表达式分割。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指代表达式分割 视觉语言理解 多模态学习 熵引导 视觉推理
📋 核心要点
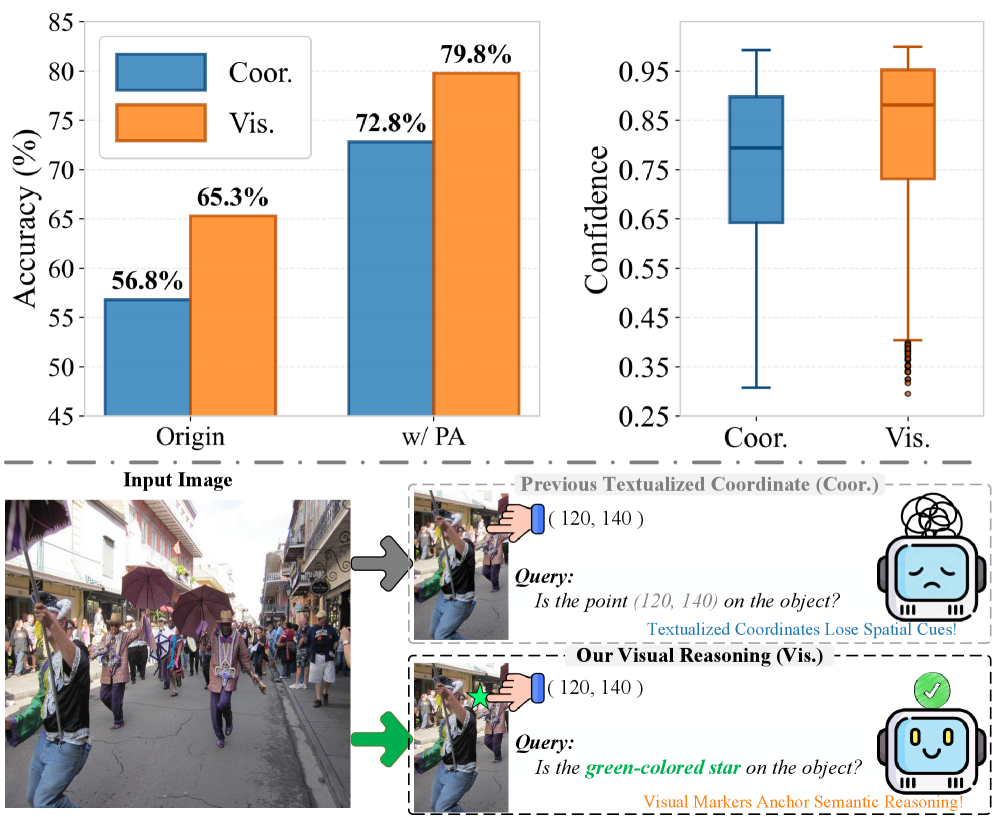
- 现有指代表达式分割方法依赖MLLM提供的粗糙边界框,导致点提示冗余且缺乏区分性。
- ResAgent通过熵引导的点发现和视觉推理,从粗到精地选择信息量大的点,并进行视觉验证。
- 实验结果表明,ResAgent在多个数据集上取得了SOTA性能,验证了其在生成精确分割掩码方面的有效性。
📝 摘要(中文)
指代表达式分割(RES)是一项核心的视觉-语言分割任务,它通过自由形式的语言表达实现对目标的像素级理解,支持人机交互和增强现实等关键应用。尽管基于多模态大型语言模型(MLLM)的方法取得了进展,但现有的RES方法仍然存在两个主要限制:首先,来自MLLM的粗糙边界框导致冗余或无区分性的点提示;其次,普遍依赖的文本坐标推理是不可靠的,因为它无法区分目标和视觉上相似的干扰物。为了解决这些问题,我们提出了ResAgent,一种新颖的RES框架,集成了基于熵的点发现(EBD)和基于视觉的推理(VBR)。具体来说,EBD通过建模粗糙边界框内的空间不确定性来识别高信息量的候选点,将点选择视为信息最大化过程。VBR通过联合视觉-语义对齐来验证点的正确性,放弃了仅基于文本的坐标推断,从而实现更稳健的验证。基于这些组件,ResAgent实现了从粗到精的工作流程:边界框初始化、熵引导的点发现、基于视觉的验证和掩码解码。在四个基准数据集(RefCOCO、RefCOCO+、RefCOCOg和ReasonSeg)上的大量评估表明,ResAgent在所有四个基准上都实现了新的最先进性能,突出了其在生成准确且语义明确的分割掩码方面的有效性,且仅需最少的提示。
🔬 方法详解
问题定义:论文旨在解决指代表达式分割(RES)任务中,现有方法依赖多模态大语言模型(MLLM)提供的粗糙边界框,导致点提示冗余且缺乏区分性,以及过度依赖文本坐标推理而无法区分视觉相似干扰物的问题。这些问题限制了RES在人机交互和增强现实等领域的应用。
核心思路:论文的核心思路是结合基于熵的点发现(EBD)和基于视觉的推理(VBR),构建一个从粗到精的RES框架。EBD用于从粗糙边界框中选择信息量最大的点,而VBR则通过视觉-语义对齐来验证这些点的正确性,从而避免了对文本坐标推理的过度依赖。
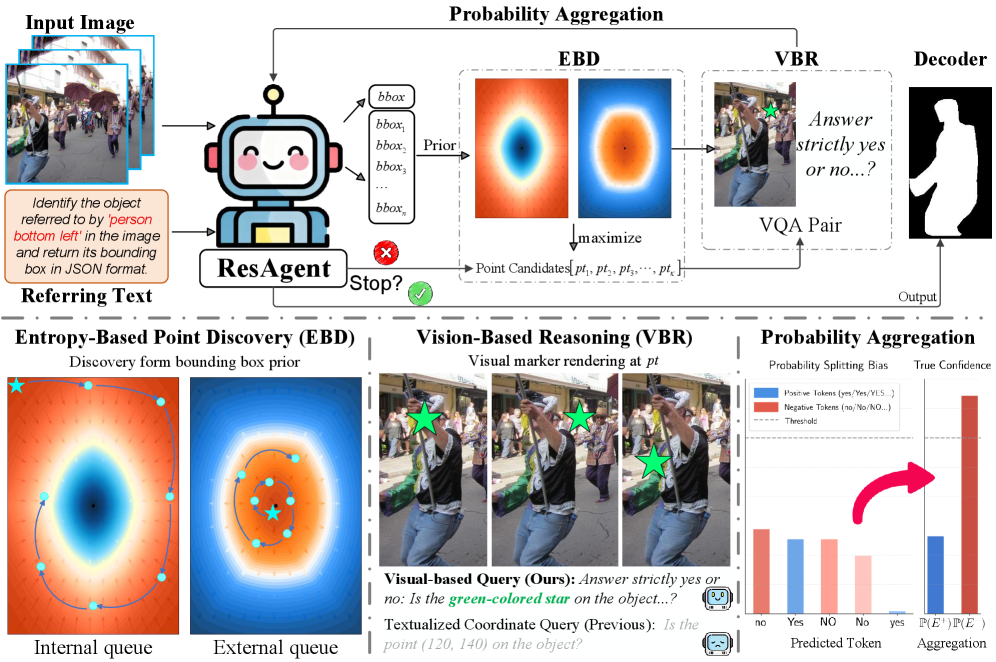
技术框架:ResAgent的整体框架包含四个主要阶段:1) 边界框初始化:利用MLLM生成目标的粗糙边界框;2) 熵引导的点发现(EBD):在边界框内,通过计算像素的空间不确定性(熵)来选择候选点;3) 基于视觉的验证(VBR):通过视觉-语义对齐来验证候选点的正确性,排除干扰物;4) 掩码解码:利用验证后的点提示生成最终的分割掩码。
关键创新:ResAgent的关键创新在于EBD和VBR的结合。EBD通过信息最大化的方式选择点提示,避免了冗余和无区分性的点。VBR则通过视觉信息来验证点的正确性,克服了文本坐标推理的局限性,提高了分割的鲁棒性。
关键设计:EBD模块使用交叉熵损失来建模像素的空间不确定性,选择熵值高的像素作为候选点。VBR模块使用视觉编码器提取图像特征,并与文本表达进行对齐,通过相似度计算来验证点的正确性。具体参数设置和网络结构细节在论文中有详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
ResAgent在RefCOCO、RefCOCO+、RefCOCOg和ReasonSeg四个基准数据集上均取得了最先进的性能。具体提升幅度在论文中有详细数据(未知),但总体而言,ResAgent在生成准确且语义明确的分割掩码方面表现出色,证明了其EBD和VBR模块的有效性。
🎯 应用场景
ResAgent在人机交互、增强现实、机器人导航等领域具有广泛的应用前景。例如,在人机交互中,它可以帮助机器人理解人类的指令,并精确分割出指令中提到的目标物体。在增强现实中,它可以实现对真实场景中特定物体的精确识别和分割,从而实现更自然的交互体验。该研究的成果有助于提升这些应用场景的智能化水平。
📄 摘要(原文)
Referring Expression Segmentation (RES) is a core vision-language segmentation task that enables pixel-level understanding of targets via free-form linguistic expressions, supporting critical applications such as human-robot interaction and augmented reality. Despite the progress of Multimodal Large Language Model (MLLM)-based approaches, existing RES methods still suffer from two key limitations: first, the coarse bounding boxes from MLLMs lead to redundant or non-discriminative point prompts; second, the prevalent reliance on textual coordinate reasoning is unreliable, as it fails to distinguish targets from visually similar distractors. To address these issues, we propose \textbf{\model}, a novel RES framework integrating \textbf{E}ntropy-\textbf{B}ased Point \textbf{D}iscovery (\textbf{EBD}) and \textbf{V}ision-\textbf{B}ased \textbf{R}easoning (\textbf{VBR}). Specifically, EBD identifies high-information candidate points by modeling spatial uncertainty within coarse bounding boxes, treating point selection as an information maximization process. VBR verifies point correctness through joint visual-semantic alignment, abandoning text-only coordinate inference for more robust validation. Built on these components, \model implements a coarse-to-fine workflow: bounding box initialization, entropy-guided point discovery, vision-based validation, and mask decoding. Extensive evaluations on four benchmark datasets (RefCOCO, RefCOCO+, RefCOCOg, and ReasonSeg) demonstrate that \model achieves new state-of-the-art performance across all four benchmarks, highlighting its effectiveness in generating accurate and semantically grounded segmentation masks with minimal prompts.