HVD: Human Vision-Driven Video Representation Learning for Text-Video Retrieval
作者: Zequn Xie, Xin Liu, Boyun Zhang, Yuxiao Lin, Sihang Cai, Tao Jin
分类: cs.CV, cs.IR
发布日期: 2026-01-22
备注: Accepted by ICASSP 2026
💡 一句话要点
提出HVD模型,通过模拟人类视觉认知机制提升文本-视频检索性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 文本-视频检索 多模态学习 人类视觉认知 注意力机制 特征选择
📋 核心要点
- 现有文本-视频检索方法难以有效区分关键视觉信息与背景噪声,导致检索性能受限。
- HVD模型模拟人类视觉认知过程,通过帧特征选择和块特征压缩实现由粗到精的视觉信息提取。
- 实验结果表明,HVD模型在多个基准数据集上取得了state-of-the-art的性能,验证了其有效性。
📝 摘要(中文)
CLIP的成功推动了文本-视频检索领域的显著进展。然而,现有方法常常受到“盲目”特征交互的困扰,由于文本查询的稀疏性,模型难以从背景噪声中辨别关键视觉信息。为了弥合这一差距,我们从人类认知行为中汲取灵感,提出了人类视觉驱动(HVD)模型。我们的框架建立了一个由粗到精的对齐机制,包括两个关键组件:帧特征选择模块(FFSM)和块特征压缩模块(PFCM)。FFSM通过选择关键帧来消除时间冗余,模拟人类的宏观感知能力。随后,PFCM通过先进的注意力机制将块特征聚合为显著的视觉实体,模拟微观感知,从而实现精确的实体级匹配。在五个基准数据集上的大量实验表明,HVD不仅捕捉到了类人的视觉焦点,而且实现了最先进的性能。
🔬 方法详解
问题定义:现有文本-视频检索方法在处理视频数据时,由于文本查询的稀疏性,模型难以有效区分视频中的关键信息和背景噪声,导致特征交互效率低下,检索性能受到影响。现有的方法缺乏对视频内容进行有效聚焦的能力,容易受到冗余信息干扰。
核心思路:HVD模型的核心思路是模拟人类的视觉认知过程,即先进行宏观的场景感知(选择关键帧),再进行微观的细节观察(关注显著视觉实体)。通过这种由粗到精的策略,模型能够更有效地提取视频中的关键视觉信息,并与文本查询进行对齐。
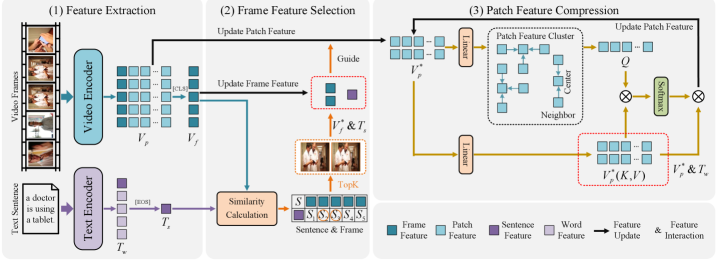
技术框架:HVD模型包含两个主要模块:帧特征选择模块(FFSM)和块特征压缩模块(PFCM)。首先,FFSM从视频中选择最具代表性的关键帧,以减少时间冗余。然后,PFCM将每个关键帧划分为多个图像块,并通过注意力机制将这些图像块聚合为显著的视觉实体。最后,将提取的视觉特征与文本特征进行对齐,用于文本-视频检索。
关键创新:HVD模型的关键创新在于其模仿人类视觉认知的 coarse-to-fine 的特征提取方式。与以往方法直接对所有帧或所有图像块进行处理不同,HVD模型首先通过FFSM进行关键帧选择,然后通过PFCM关注显著视觉实体,从而更有效地提取视频中的关键信息。这种方法能够减少计算量,并提高特征的表达能力。
关键设计:FFSM使用一个可学习的权重来评估每一帧的重要性,并选择权重最高的帧作为关键帧。PFCM使用一个多头注意力机制来聚合图像块特征,从而捕捉图像块之间的关系。损失函数包括一个对比学习损失,用于拉近匹配的文本-视频对的距离,并推开不匹配的文本-视频对的距离。具体的网络结构和参数设置在论文中有详细描述,但未在摘要中体现。
🖼️ 关键图片


📊 实验亮点
HVD模型在五个基准数据集上进行了广泛的实验,结果表明HVD模型在文本-视频检索任务上取得了state-of-the-art的性能。具体的数据提升幅度在摘要中未明确给出,但强调了超越现有方法的优越性。实验结果验证了HVD模型模拟人类视觉认知机制的有效性。
🎯 应用场景
HVD模型可应用于视频搜索、视频推荐、视频内容理解等领域。通过更有效地提取视频中的关键信息,HVD模型可以提高视频检索的准确性和效率,改善用户体验。该研究对于开发更智能的视频分析和理解系统具有重要意义,并为未来的多模态学习研究提供了新的思路。
📄 摘要(原文)
The success of CLIP has driven substantial progress in text-video retrieval. However, current methods often suffer from "blind" feature interaction, where the model struggles to discern key visual information from background noise due to the sparsity of textual queries. To bridge this gap, we draw inspiration from human cognitive behavior and propose the Human Vision-Driven (HVD) model. Our framework establishes a coarse-to-fine alignment mechanism comprising two key components: the Frame Features Selection Module (FFSM) and the Patch Features Compression Module (PFCM). FFSM mimics the human macro-perception ability by selecting key frames to eliminate temporal redundancy. Subsequently, PFCM simulates micro-perception by aggregating patch features into salient visual entities through an advanced attention mechanism, enabling precise entity-level matching. Extensive experiments on five benchmarks demonstrate that HVD not only captures human-like visual focus but also achieves state-of-the-art performance.