Rethinking Composed Image Retrieval Evaluation: A Fine-Grained Benchmark from Image Editing
作者: Tingyu Song, Yanzhao Zhang, Mingxin Li, Zhuoning Guo, Dingkun Long, Pengjun Xie, Siyue Zhang, Yilun Zhao, Shu Wu
分类: cs.CV, cs.CL, cs.IR
发布日期: 2026-01-22
备注: Under review
💡 一句话要点
提出EDIR:一个基于图像编辑的细粒度组合图像检索评测基准。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 组合图像检索 图像编辑 多模态理解 评测基准 细粒度检索
📋 核心要点
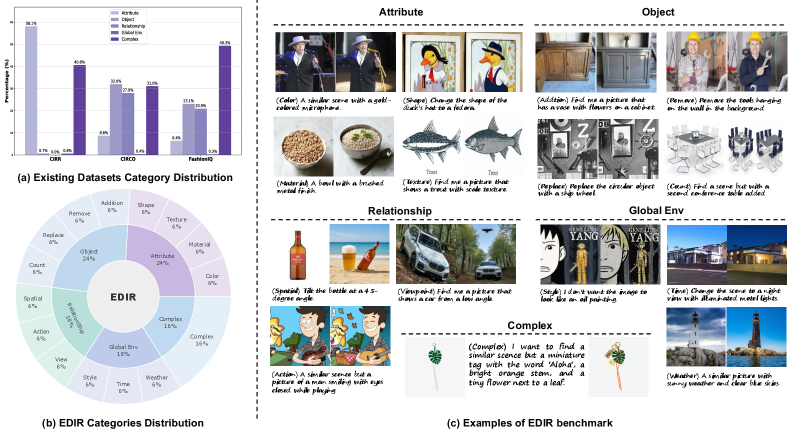
- 现有组合图像检索基准类别有限,难以覆盖真实场景的多样性需求,评估存在差距。
- 利用图像编辑技术,精确控制修改类型和内容,构建了一个新的细粒度组合图像检索基准EDIR。
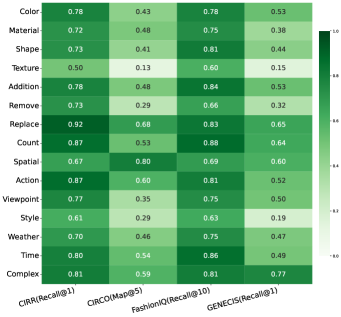
- 实验表明,现有SOTA模型在EDIR上表现不佳,揭示了现有基准的局限性,并验证了EDIR的可行性。
📝 摘要(中文)
组合图像检索(CIR)是多模态理解中一个关键且复杂的任务。现有的CIR基准通常具有有限的查询类别,并且无法捕捉真实场景的多样化需求。为了弥补这一评估差距,我们利用图像编辑来实现对修改类型和内容的精确控制,从而实现跨越广泛类别的查询合成流程。利用该流程,我们构建了EDIR,这是一个新的细粒度CIR基准。EDIR包含5000个高质量查询,这些查询结构化地分布在五个主要类别和十五个子类别中。我们对13个多模态嵌入模型进行的全面评估揭示了显著的能力差距;即使是最先进的模型(例如,RzenEmbed和GME)也难以在所有子类别中保持一致的性能,突显了我们基准的严格性。通过对比分析,我们进一步揭示了现有基准的内在局限性,例如模态偏差和类别覆盖不足。此外,一个域内训练实验证明了我们基准的可行性。该实验通过区分可以通过目标数据解决的类别和那些暴露当前模型架构内在局限性的类别,从而阐明了任务挑战。
🔬 方法详解
问题定义:组合图像检索(CIR)旨在根据文本描述对图像进行检索,现有基准数据集存在类别覆盖不足、模态偏差等问题,无法全面评估模型在真实场景下的性能。现有方法难以在细粒度的图像编辑任务上保持一致的性能,暴露了模型架构的内在局限性。
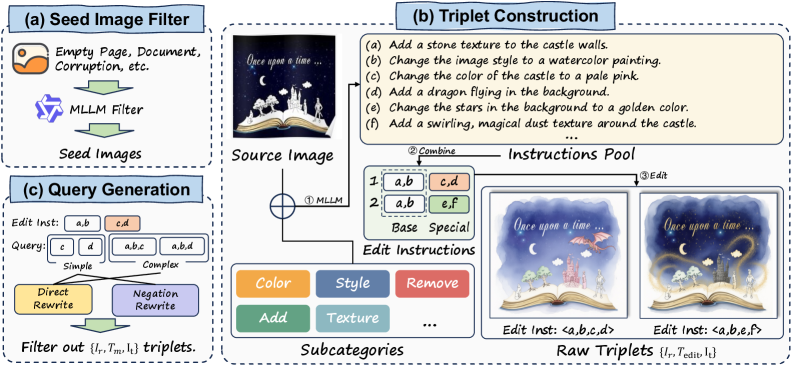
核心思路:利用图像编辑技术生成高质量的组合图像检索查询,通过精确控制修改类型和内容,构建一个细粒度的、具有挑战性的评测基准EDIR。该基准旨在更全面地评估模型在不同类别和细粒度修改下的检索能力,从而推动CIR领域的发展。
技术框架:EDIR的构建流程主要包括:1) 选择高质量的图像数据集;2) 定义五个主要类别和十五个子类别的图像编辑类型;3) 利用图像编辑模型,根据文本描述对图像进行修改,生成组合图像查询;4) 对生成的查询进行质量评估和筛选,最终构建包含5000个高质量查询的EDIR基准。
关键创新:EDIR的关键创新在于利用图像编辑技术生成组合图像查询,从而实现了对修改类型和内容的精确控制,构建了一个细粒度的评测基准。与现有基准相比,EDIR具有更广泛的类别覆盖、更细粒度的修改类型和更高质量的查询,能够更全面地评估模型的检索能力。
关键设计:EDIR基准包含五个主要类别(例如,颜色变化、对象添加/删除)和十五个子类别(例如,将颜色更改为红色、添加帽子)。图像编辑模型选择方面,论文未明确说明具体使用的模型,但强调了对生成查询的质量评估和筛选,以确保基准的可靠性。损失函数和网络结构方面,论文主要关注基准的构建,并未涉及特定的模型训练细节。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有最先进的模型(如RzenEmbed和GME)在EDIR基准上表现不佳,尤其是在某些子类别上,性能下降明显。这表明现有模型在处理细粒度的图像编辑任务时存在局限性。域内训练实验表明,针对特定类别的数据可以提升模型性能,但也暴露了当前模型架构的内在局限性。
🎯 应用场景
该研究成果可应用于智能图像搜索、图像编辑辅助、人机交互等领域。通过更准确地理解用户对图像的修改意图,可以提升图像检索的准确性和效率,为用户提供更智能化的图像处理服务。未来,该基准可以促进多模态理解和图像编辑技术的发展。
📄 摘要(原文)
Composed Image Retrieval (CIR) is a pivotal and complex task in multimodal understanding. Current CIR benchmarks typically feature limited query categories and fail to capture the diverse requirements of real-world scenarios. To bridge this evaluation gap, we leverage image editing to achieve precise control over modification types and content, enabling a pipeline for synthesizing queries across a broad spectrum of categories. Using this pipeline, we construct EDIR, a novel fine-grained CIR benchmark. EDIR encompasses 5,000 high-quality queries structured across five main categories and fifteen subcategories. Our comprehensive evaluation of 13 multimodal embedding models reveals a significant capability gap; even state-of-the-art models (e.g., RzenEmbed and GME) struggle to perform consistently across all subcategories, highlighting the rigorous nature of our benchmark. Through comparative analysis, we further uncover inherent limitations in existing benchmarks, such as modality biases and insufficient categorical coverage. Furthermore, an in-domain training experiment demonstrates the feasibility of our benchmark. This experiment clarifies the task challenges by distinguishing between categories that are solvable with targeted data and those that expose intrinsic limitations of current model architectures.