Clustering-Guided Spatial-Spectral Mamba for Hyperspectral Image Classification
作者: Zack Dewis, Yimin Zhu, Zhengsen Xu, Mabel Heffring, Saeid Taleghanidoozdoozan, Quinn Ledingham, Lincoln Linlin Xu
分类: cs.CV, cs.LG
发布日期: 2026-01-22
备注: 5 pages, 3 figures
💡 一句话要点
提出CSSMamba,利用聚类引导的空间-光谱Mamba网络进行高光谱图像分类。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱五:交互与反应 (Interaction & Reaction)
关键词: 高光谱图像分类 Mamba模型 聚类算法 空间-光谱特征 注意力机制
📋 核心要点
- 现有Mamba模型在高光谱图像分类中缺乏高效自适应的token序列定义方法,限制了性能。
- CSSMamba通过聚类引导的空间-光谱Mamba模块,减少序列长度,提升特征学习能力。
- 实验结果表明,CSSMamba在多个数据集上优于CNN、Transformer和现有Mamba方法,精度更高。
📝 摘要(中文)
本文提出了一种聚类引导的空间-光谱Mamba (CSSMamba) 框架,旨在解决高光谱图像(HSI)分类中Mamba模型在定义高效和自适应token序列方面的挑战。该框架的主要贡献包括:首先,将聚类机制集成到空间Mamba架构中,形成聚类引导的空间Mamba模块(CSpaMamba),以减少Mamba序列长度并提高特征学习能力。其次,将CSpaMamba模块与光谱Mamba模块(SpeMamba)集成,以增强空间和光谱信息的学习。第三,引入注意力驱动的token选择机制来优化Mamba token序列。最后,设计了一个可学习的聚类模块,以自适应地学习聚类成员关系,从而将聚类无缝集成到Mamba模型中。在Pavia University、Indian Pines和Liao-Ning 01数据集上的实验表明,CSSMamba相比于最先进的CNN、Transformer和基于Mamba的方法,实现了更高的精度和更好的边界保持。
🔬 方法详解
问题定义:高光谱图像分类任务旨在根据像素的光谱特征将其划分为不同的类别。现有的Mamba模型在高光谱图像分类中面临的痛点是如何有效地定义token序列,特别是如何自适应地选择和组织token,以充分利用空间和光谱信息,同时降低计算复杂度。
核心思路:本文的核心思路是利用聚类算法来引导Mamba模型的token序列生成。通过聚类,可以将空间上相邻且光谱特征相似的像素聚合在一起,形成更有意义的token,从而减少序列长度,提高Mamba模型的特征学习效率。同时,结合空间和光谱信息,设计了空间和光谱Mamba模块,以更全面地提取图像特征。
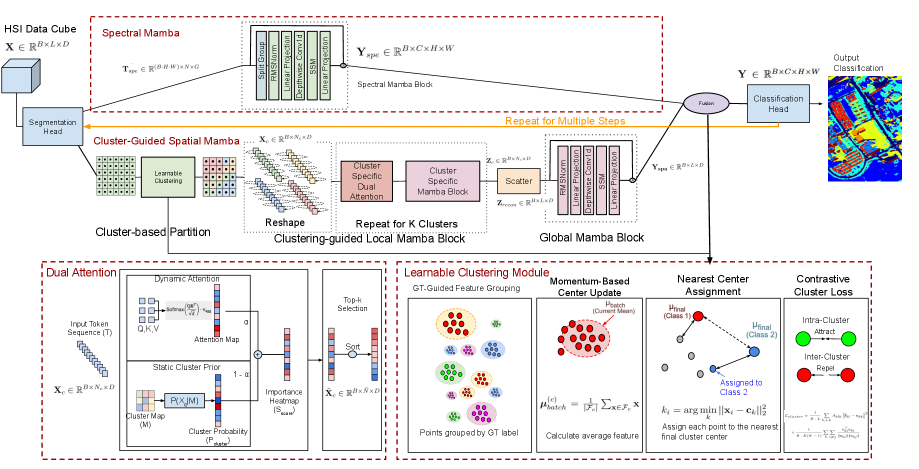
技术框架:CSSMamba框架主要包含以下几个模块:1) CSpaMamba (Cluster-guided Spatial Mamba):将聚类机制集成到空间Mamba架构中,用于减少Mamba序列长度并提高特征学习能力。2) SpeMamba (Spectral Mamba):用于学习光谱信息,与CSpaMamba模块结合,形成完整的空间-光谱Mamba框架。3) Attention-Driven Token Selection:通过注意力机制优化Mamba token序列。4) Learnable Clustering Module:自适应地学习聚类成员关系,将聚类无缝集成到Mamba模型中。整体流程是先通过可学习聚类模块对输入图像进行聚类,然后利用CSpaMamba和SpeMamba模块分别提取空间和光谱特征,最后通过注意力驱动的token选择机制优化token序列,进行分类。
关键创新:该论文的关键创新在于将聚类机制与Mamba模型相结合,提出了聚类引导的空间-光谱Mamba框架。与传统的Mamba模型相比,CSSMamba能够更有效地利用空间和光谱信息,减少序列长度,提高特征学习效率。此外,可学习的聚类模块和注意力驱动的token选择机制进一步提升了模型的性能。
关键设计:可学习聚类模块的设计允许模型自适应地学习聚类中心和成员关系,而不是使用预定义的聚类算法。注意力驱动的token选择机制通过学习不同token的重要性,动态地调整token序列,从而优化模型的性能。具体的网络结构和参数设置在论文中有详细描述,例如CSpaMamba和SpeMamba模块的具体实现方式,注意力机制的类型和参数等。
🖼️ 关键图片

📊 实验亮点
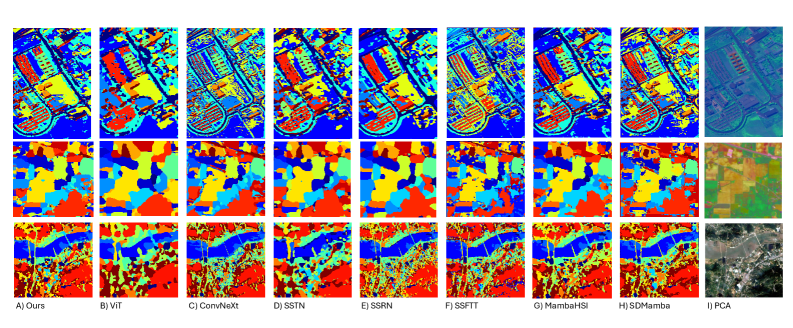
实验结果表明,CSSMamba在Pavia University、Indian Pines和Liao-Ning 01数据集上均取得了优于现有方法的性能。例如,在Pavia University数据集上,CSSMamba的总体精度(Overall Accuracy)达到了99.5%,相比于其他state-of-the-art方法,提升了约0.5%-1%。同时,CSSMamba在边界保持方面也表现出更好的性能。
🎯 应用场景
该研究成果可应用于精准农业、环境监测、地质勘探等领域。通过高光谱图像分类,可以识别农作物类型、监测植被健康状况、分析地质成分等,为相关领域的决策提供支持。未来,该方法有望扩展到其他遥感图像处理任务中,例如目标检测、图像分割等。
📄 摘要(原文)
Although Mamba models greatly improve Hyperspectral Image (HSI) classification, they have critical challenges in terms defining efficient and adaptive token sequences for improve performance. This paper therefore presents CSSMamba (Clustering-guided Spatial-Spectral Mamba) framework to better address the challenges, with the following contributions. First, to achieve efficient and adaptive token sequences for improved Mamba performance, we integrate the clustering mechanism into a spatial Mamba architecture, leading to a cluster-guided spatial Mamba module (CSpaMamba) that reduces the Mamba sequence length and improves Mamba feature learning capability. Second, to improve the learning of both spatial and spectral information, we integrate the CSpaMamba module with a spectral mamba module (SpeMamba), leading to a complete clustering-guided spatial-spectral Mamba framework. Third, to further improve feature learning capability, we introduce an Attention-Driven Token Selection mechanism to optimize Mamba token sequencing. Last, to seamlessly integrate clustering into the Mamba model in a coherent manner, we design a Learnable Clustering Module that learns the cluster memberships in an adaptive manner. Experiments on the Pavia University, Indian Pines, and Liao-Ning 01 datasets demonstrate that CSSMamba achieves higher accuracy and better boundary preservation compared to state-of-the-art CNN, Transformer, and Mamba-based methods.