DTP: A Simple yet Effective Distracting Token Pruning Framework for Vision-Language Action Models
作者: Chenyang Li, Jieyuan Liu, Bin Li, Bo Gao, Yilin Yuan, Yangfan He, Yuchen Li, Jingqun Tang
分类: cs.CV, cs.RO
发布日期: 2026-01-22
💡 一句话要点
提出DTP框架,通过剪枝干扰token提升视觉-语言动作模型在机器人操作任务中的成功率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言动作模型 机器人操作 干扰Token剪枝 注意力机制 模型优化
📋 核心要点
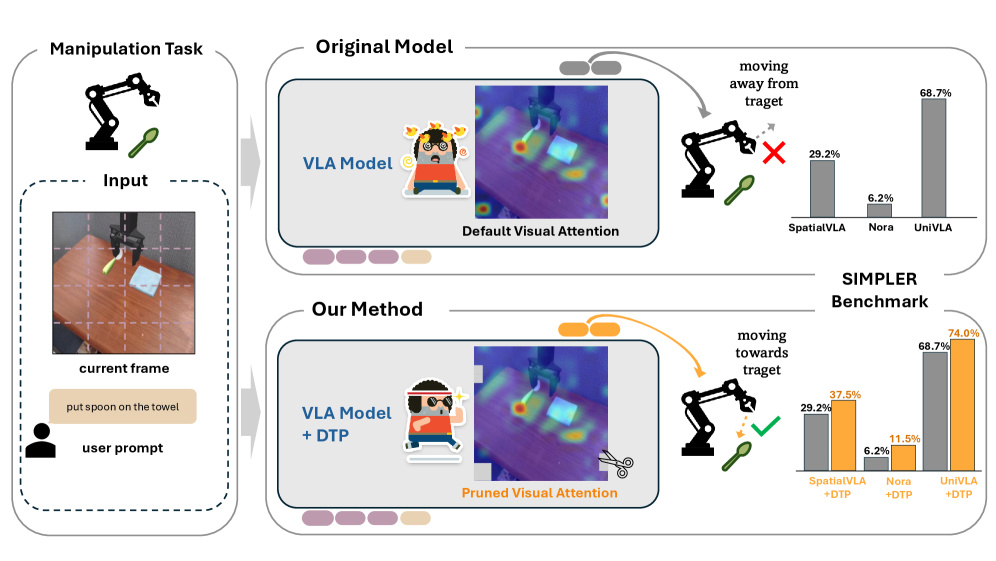
- VLA模型在机器人操作中易受与任务无关的“干扰token”影响,降低了动作生成的准确性和任务成功率。
- DTP框架通过动态检测和剪枝干扰token,纠正模型的视觉注意力模式,从而提升任务成功率。
- 实验表明,DTP框架在不同VLA模型上均能提升任务成功率,且任务成功率与干扰区域注意力存在负相关。
📝 摘要(中文)
视觉-语言动作(VLA)模型在机器人操作领域取得了显著进展,它们利用视觉-语言模型(VLMs)强大的感知能力来理解环境并直接输出动作。然而,VLA模型默认情况下可能会过度关注图像中与任务无关区域的token,我们称之为“干扰token”。这种行为会干扰模型生成期望的动作token,从而影响任务的成功率。本文提出了一种简单而有效的即插即用干扰Token剪枝(DTP)框架,该框架可以动态地检测和剪枝这些干扰图像token。通过纠正模型的视觉注意力模式,我们旨在提高任务成功率,并探索模型在不改变其原始架构或添加额外输入的情况下所能达到的性能上限。在SIMPLER基准测试上的实验表明,我们的方法在不同类型的新型VLA模型上始终如一地实现了任务成功率的相对提高,证明了其对基于Transformer的VLA的通用性。进一步的分析表明,对于所有测试的模型,任务成功率与任务无关区域的注意力量之间存在负相关关系,突出了VLA模型的一个普遍现象,可以指导未来的研究。我们还发布了我们的代码。
🔬 方法详解
问题定义:VLA模型在执行机器人操作任务时,容易受到图像中与任务无关区域的“干扰token”的影响。这些干扰token分散了模型对关键信息的注意力,导致动作生成不准确,最终降低任务成功率。现有方法通常依赖于更复杂的模型结构或额外的输入信息,而忽略了模型本身可能存在的注意力偏差问题。
核心思路:DTP的核心思路是通过动态地检测并剪枝这些干扰token,从而纠正模型的视觉注意力模式,使其更加关注与任务相关的区域。这种方法无需修改模型架构或添加额外输入,是一种即插即用的解决方案。通过减少干扰信息的干扰,模型可以更准确地生成动作token,从而提高任务成功率。
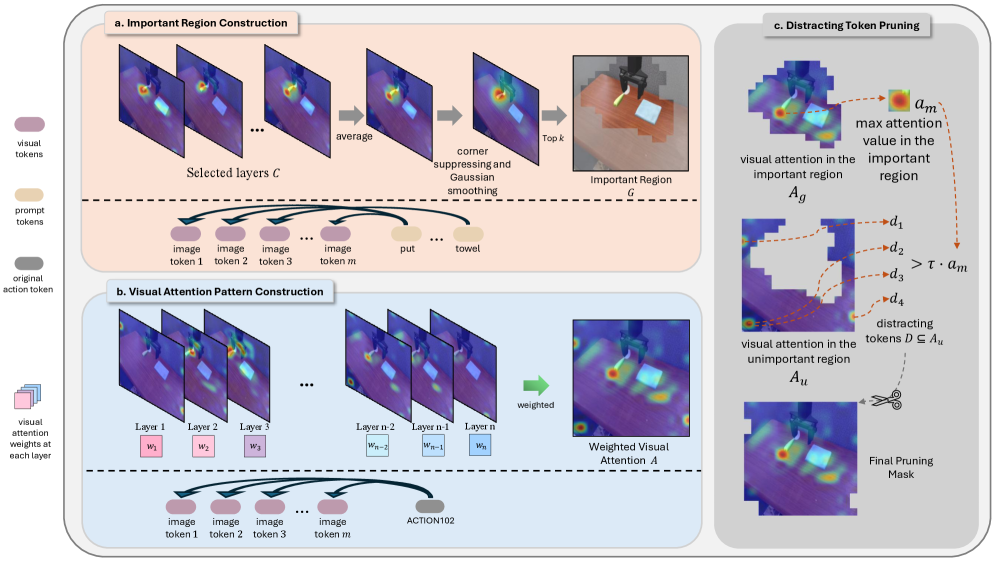
技术框架:DTP框架主要包含两个阶段:干扰token检测和token剪枝。首先,利用某种策略(例如,基于注意力权重的阈值)来识别图像token中哪些属于干扰token。然后,将这些干扰token从输入序列中移除,或者通过某种方式降低它们对后续层的影响。修改后的token序列被送入VLA模型的后续层进行处理,最终生成动作。
关键创新:DTP的关键创新在于其简单性和有效性。它不需要对VLA模型进行任何修改,可以作为插件直接集成到现有模型中。此外,DTP能够动态地检测和剪枝干扰token,这意味着它可以适应不同的任务和环境,具有很强的通用性。与现有方法相比,DTP更加轻量级,易于实现,并且能够有效地提高任务成功率。
关键设计:DTP的具体实现细节可能因不同的VLA模型而异。一种可能的实现方式是基于注意力权重的阈值来检测干扰token。例如,可以计算每个token的平均注意力权重,并将权重低于某个阈值的token视为干扰token。然后,可以将这些token的embedding设置为零,或者直接从输入序列中移除。阈值的选择可以根据具体任务进行调整。此外,还可以使用不同的剪枝策略,例如,只剪枝一部分干扰token,或者根据token的重要性进行加权剪枝。
🖼️ 关键图片

📊 实验亮点
在SIMPLER基准测试中,DTP框架在不同类型的VLA模型上均取得了显著的性能提升。实验结果表明,DTP能够始终如一地提高任务成功率,并且与任务无关区域的注意力量之间存在负相关关系。例如,在某个特定模型上,DTP可以将任务成功率提高5%-10%。这些结果表明,DTP是一种有效且通用的干扰token剪枝方法。
🎯 应用场景
DTP框架具有广泛的应用前景,可应用于各种基于视觉-语言动作模型的机器人操作任务中,例如物体抓取、装配、导航等。通过提高任务成功率,DTP可以提升机器人的自主性和可靠性,使其能够更好地适应复杂的现实环境。此外,DTP还可以用于分析VLA模型的注意力模式,从而指导模型的设计和优化。
📄 摘要(原文)
Vision-Language Action (VLA) models have shown remarkable progress in robotic manipulation by leveraging the powerful perception abilities of Vision-Language Models (VLMs) to understand environments and directly output actions. However, by default, VLA models may overly attend to image tokens in the task-irrelevant region, which we describe as 'distracting tokens'. This behavior can disturb the model from the generation of the desired action tokens in each step, affecting the success rate of tasks. In this paper, we introduce a simple yet effective plug-and-play Distracting Token Pruning (DTP) framework, which dynamically detects and prunes these distracting image tokens. By correcting the model's visual attention patterns, we aim to improve the task success rate, as well as exploring the performance upper boundaries of the model without altering its original architecture or adding additional inputs. Experiments on the SIMPLER Benchmark (Li et al., 2024) show that our method consistently achieving relative improvements in task success rates across different types of novel VLA models, demonstrating generalizability to transformer-based VLAs. Further analysis reveals a negative correlation between the task success rate and the amount of attentions in the task-irrelevant region for all models tested, highlighting a common phenomenon of VLA models that could guide future research. We also publish our code at: https://anonymous.4open.science/r/CBD3.