Keyframe-Based Feed-Forward Visual Odometry
作者: Weichen Dai, Wenhan Su, Da Kong, Yuhang Ming, Wanzeng Kong
分类: cs.CV, cs.RO
发布日期: 2026-01-22
💡 一句话要点
提出基于强化学习的关键帧前馈视觉里程计,提升效率与精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉里程计 关键帧选择 强化学习 前馈网络 位姿估计
📋 核心要点
- 现有基于视觉基础模型的前馈VO方法忽略了关键帧选择,导致计算冗余和性能下降。
- 提出基于强化学习的关键帧选择策略,自适应地选择信息量大的帧,提升VO的效率和精度。
- 实验表明,该方法在多个真实数据集上显著优于现有前馈VO方法,验证了其有效性。
📝 摘要(中文)
视觉基础模型的出现彻底改变了视觉里程计(VO)和SLAM,使得在单个前馈网络中进行位姿估计和稠密重建成为可能。然而,与利用关键帧方法来提高效率和精度的传统流程不同,当前基于基础模型的方法,如VGGT-Long,通常不加区分地处理原始图像序列。这导致了计算冗余,并因帧间视差小而导致性能下降,因为帧间视差提供的上下文立体信息有限。将传统的几何启发式方法集成到这些方法中并非易事,因为它们的性能取决于高维潜在表示,而不是显式的几何度量。为了弥合这一差距,我们提出了一种新的基于关键帧的前馈VO。我们的方法没有依赖于手工设计的规则,而是采用强化学习以数据驱动的方式推导出自适应关键帧策略,使选择与底层基础模型的内在特征对齐。我们在TartanAir数据集上训练我们的agent,并在多个真实世界数据集上进行了广泛的评估。实验结果表明,所提出的方法在最先进的前馈VO方法上实现了持续且显著的改进。
🔬 方法详解
问题定义:现有基于视觉基础模型的前馈视觉里程计方法,如VGGT-Long,直接处理所有图像帧,忽略了帧间视差较小带来的信息冗余。这导致计算资源的浪费,并且由于缺乏有效的立体信息,降低了位姿估计的精度。因此,如何有效地选择关键帧,以减少计算量并提高性能,是一个关键问题。
核心思路:论文的核心思路是利用强化学习来学习一个自适应的关键帧选择策略。该策略能够根据当前帧的特征,判断其是否应该被选为关键帧。通过数据驱动的方式,让agent学习到与底层视觉基础模型特性相匹配的关键帧选择方式,避免了手工设计规则的局限性。
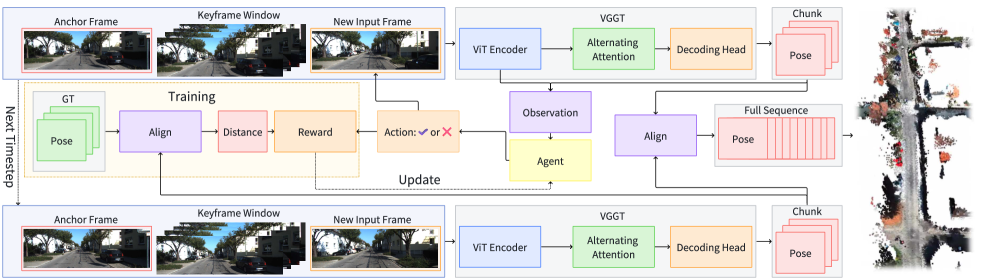
技术框架:整体框架包含两个主要部分:视觉基础模型(例如VGGT-Long)和强化学习agent。首先,图像序列输入到强化学习agent中,agent根据当前帧的特征决定是否将其选为关键帧。被选中的关键帧序列被送入视觉基础模型进行位姿估计。强化学习agent根据位姿估计的误差和计算效率等指标获得奖励,并不断优化其关键帧选择策略。
关键创新:最重要的创新点在于使用强化学习来学习关键帧选择策略,而不是依赖于手工设计的规则。这种数据驱动的方法能够更好地适应不同的视觉基础模型和场景,并且能够自动平衡位姿估计的精度和计算效率。
关键设计:强化学习agent使用Actor-Critic架构,Actor网络负责输出关键帧选择的概率,Critic网络负责评估当前状态的价值。奖励函数的设计至关重要,需要综合考虑位姿估计的误差、计算效率以及关键帧的数量。具体而言,奖励函数可能包含以下几项:位姿估计误差的负值、计算时间的负值、关键帧数量的负值等。通过调整这些项的权重,可以控制agent在精度和效率之间的权衡。
🖼️ 关键图片
📊 实验亮点
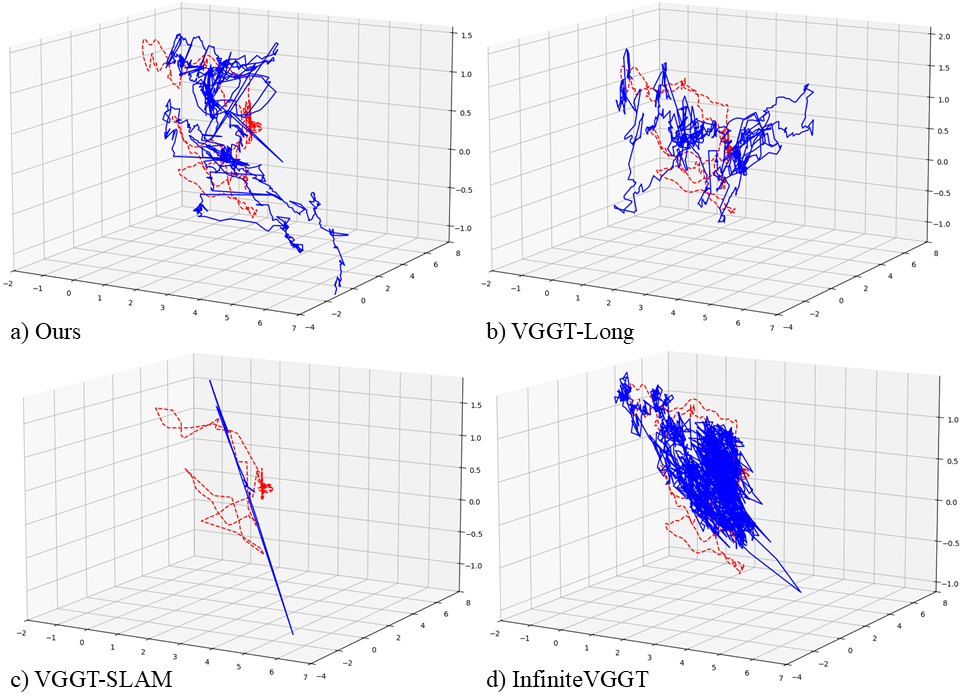
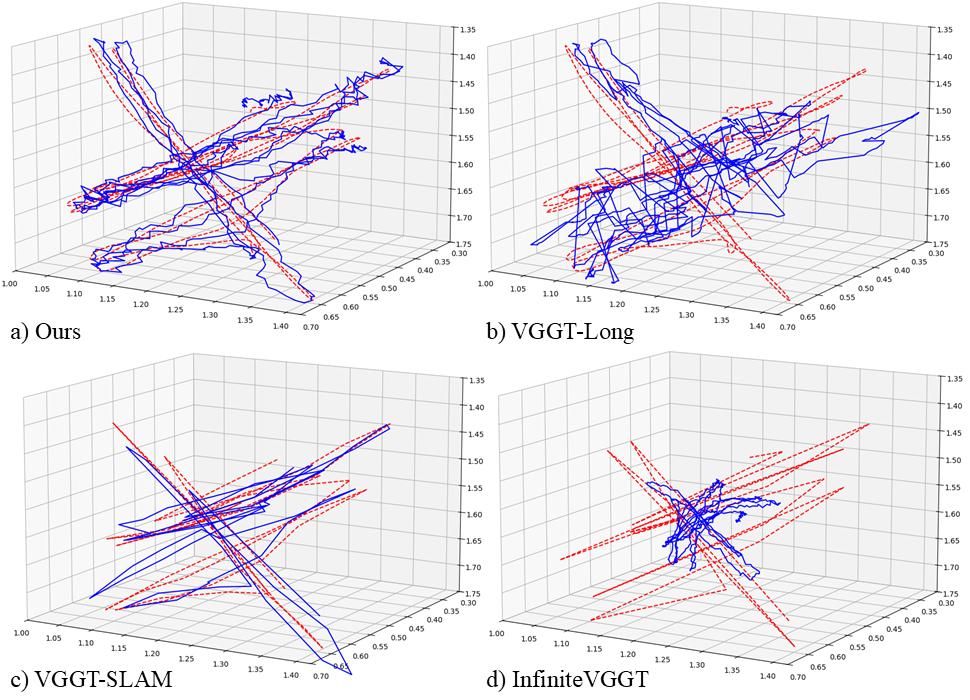
实验结果表明,该方法在多个真实数据集上显著优于现有前馈VO方法。例如,在KITTI数据集上,该方法在translation error和rotation error上均取得了明显的降低。与VGGT-Long相比,该方法在保持甚至提高精度的同时,显著减少了计算量。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、增强现实等领域。通过减少视觉里程计的计算量,可以降低对硬件的要求,并提高系统的实时性。此外,自适应的关键帧选择策略可以提高在复杂环境下的定位精度,增强系统的鲁棒性。
📄 摘要(原文)
The emergence of visual foundation models has revolutionized visual odometry~(VO) and SLAM, enabling pose estimation and dense reconstruction within a single feed-forward network. However, unlike traditional pipelines that leverage keyframe methods to enhance efficiency and accuracy, current foundation model based methods, such as VGGT-Long, typically process raw image sequences indiscriminately. This leads to computational redundancy and degraded performance caused by low inter-frame parallax, which provides limited contextual stereo information. Integrating traditional geometric heuristics into these methods is non-trivial, as their performance depends on high-dimensional latent representations rather than explicit geometric metrics. To bridge this gap, we propose a novel keyframe-based feed-forward VO. Instead of relying on hand-crafted rules, our approach employs reinforcement learning to derive an adaptive keyframe policy in a data-driven manner, aligning selection with the intrinsic characteristics of the underlying foundation model. We train our agent on TartanAir dataset and conduct extensive evaluations across several real-world datasets. Experimental results demonstrate that the proposed method achieves consistent and substantial improvements over state-of-the-art feed-forward VO methods.