PhysicsMind: Sim and Real Mechanics Benchmarking for Physical Reasoning and Prediction in Foundational VLMs and World Models
作者: Chak-Wing Mak, Guanyu Zhu, Boyi Zhang, Hongji Li, Xiaowei Chi, Kevin Zhang, Yichen Wu, Yangfan He, Chun-Kai Fan, Wentao Lu, Kuangzhi Ge, Xinyu Fang, Hongyang He, Kuan Lu, Tianxiang Xu, Li Zhang, Yongxin Ni, Youhua Li, Shanghang Zhang
分类: cs.CV, cs.AI
发布日期: 2026-01-22
💡 一句话要点
PhysicsMind:用于评估VLMs和世界模型物理推理能力的综合性基准测试
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 物理推理 多模态学习 基准测试 视觉问答 视频生成 世界模型 力学定律
📋 核心要点
- 现有物理推理基准依赖合成数据或关注与物理规律关联不大的感知视频质量,缺乏统一性。
- PhysicsMind构建了包含真实和模拟环境的基准,围绕质心、杠杆平衡和牛顿第一定律进行评估。
- 实验表明现有模型依赖表观启发式,难以遵循基本力学定律,表明物理理解能力仍有不足。
📝 摘要(中文)
本文提出了PhysicsMind,一个统一的基准测试,旨在评估多模态大型语言模型(MLLMs)和视频世界模型在物理规律一致性推理和生成方面的能力。该基准包含真实和模拟环境,涵盖三个经典物理原则:质心、杠杆平衡和牛顿第一定律。PhysicsMind包含两类任务:(1)视觉问答(VQA)任务,测试模型从图像或短视频中推理和确定物理量值的能力;(2)视频生成(VG)任务,评估预测的运动轨迹是否符合质心、扭矩和惯性约束。在PhysicsMind上对一系列最新模型和视频生成模型进行了评估,结果表明它们依赖于表观启发式,并且经常违反基本的力学定律。这些差距表明,当前的扩展和训练对于鲁棒的物理理解仍然不足,突显了PhysicsMind作为物理感知多模态模型的重点测试平台。
🔬 方法详解
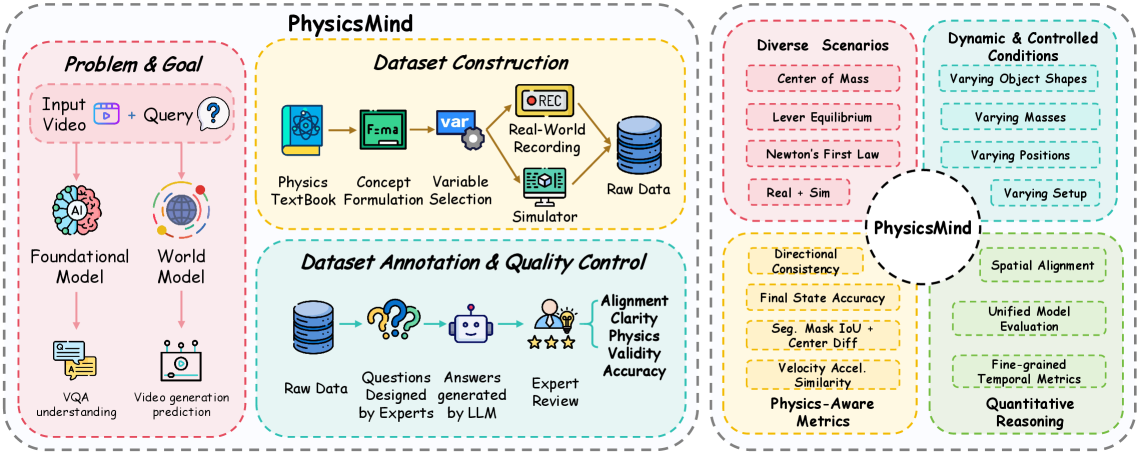
问题定义:现有基准测试在评估多模态大型语言模型(MLLMs)和视频世界模型对物理规律的理解方面存在局限性。它们通常依赖于合成数据、视觉问答模板,或者侧重于与物理规律关联性较弱的感知视频质量,缺乏一个统一的、能够全面评估模型物理推理能力的基准。因此,需要一个能够同时在真实和模拟环境中评估模型在核心物理原则上表现的基准。
核心思路:PhysicsMind的核心思路是构建一个涵盖多种物理原则(质心、杠杆平衡、牛顿第一定律)的综合性基准,通过视觉问答(VQA)和视频生成(VG)两种任务来评估模型对物理规律的理解和应用能力。VQA任务考察模型从视觉信息中提取和推理物理量的能力,而VG任务则评估模型生成符合物理规律的运动轨迹的能力。这种双重评估方式能够更全面地反映模型在物理推理方面的优缺点。
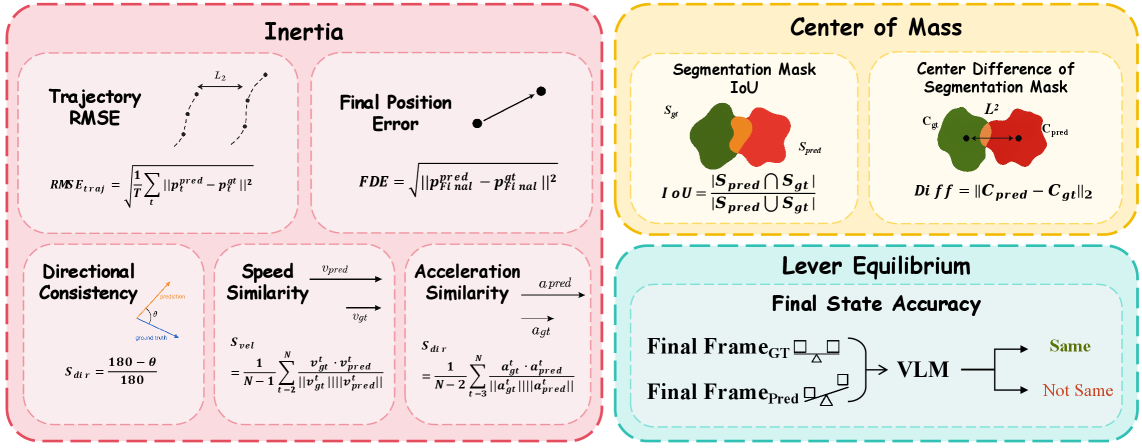
技术框架:PhysicsMind基准测试包含以下主要组成部分: 1. 数据集:包含真实世界和模拟环境中的图像和视频数据,涵盖质心、杠杆平衡和牛顿第一定律等物理场景。 2. VQA任务:模型需要根据图像或视频回答与物理量相关的问题,例如物体的位置、速度、受力情况等。 3. VG任务:模型需要根据初始状态预测物体的运动轨迹,并评估预测轨迹与真实轨迹的物理一致性。 4. 评估指标:用于衡量模型在VQA任务中的准确率和VG任务中轨迹的物理合理性。
关键创新:PhysicsMind的关键创新在于其统一性和综合性。它首次将真实世界和模拟环境结合起来,并涵盖了多个核心物理原则,从而提供了一个更全面、更具挑战性的物理推理评估平台。此外,PhysicsMind同时考察模型的推理能力和生成能力,能够更深入地了解模型对物理规律的理解程度。
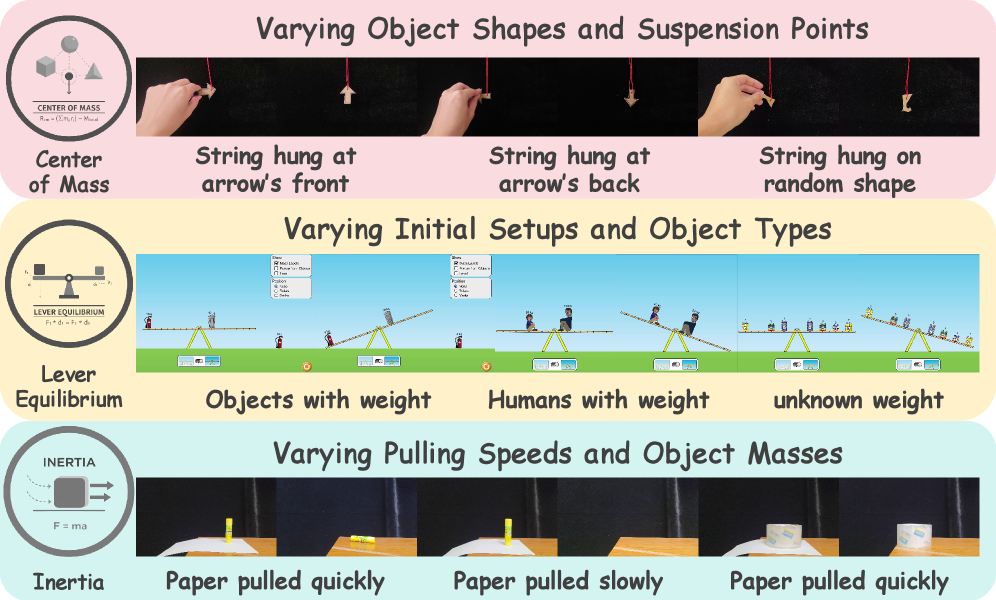
关键设计:PhysicsMind在数据集构建方面,力求覆盖各种不同的场景和物体,以增加模型的泛化能力。在VQA任务中,设计了多种类型的问题,包括选择题、填空题和开放式问题,以考察模型不同层次的推理能力。在VG任务中,采用了多种评估指标,包括轨迹的均方误差、能量守恒误差和动量守恒误差,以全面评估预测轨迹的物理合理性。具体的参数设置和网络结构取决于被评估的模型。
🖼️ 关键图片
📊 实验亮点
在PhysicsMind基准测试中,对一系列最新的多模态大型语言模型和视频生成模型进行了评估。实验结果表明,这些模型在物理推理方面表现不佳,通常依赖于表观启发式,并且经常违反基本的力学定律。例如,在VQA任务中,模型的准确率远低于人类水平;在VG任务中,模型生成的运动轨迹经常不符合能量守恒或动量守恒定律。这些结果表明,当前的扩展和训练对于鲁棒的物理理解仍然不足。
🎯 应用场景
PhysicsMind的研究成果可应用于提升机器人、自动驾驶等领域的智能系统对物理世界的理解和预测能力。通过在该基准上训练和评估模型,可以开发出更安全、更可靠的智能系统,例如能够更好地预测物体运动轨迹的机器人,以及能够更准确地感知和响应周围环境的自动驾驶汽车。此外,该基准还可以促进多模态学习和物理推理领域的研究进展。
📄 摘要(原文)
Modern foundational Multimodal Large Language Models (MLLMs) and video world models have advanced significantly in mathematical, common-sense, and visual reasoning, but their grasp of the underlying physics remains underexplored. Existing benchmarks attempting to measure this matter rely on synthetic, Visual Question Answer templates or focus on perceptual video quality that is tangential to measuring how well the video abides by physical laws. To address this fragmentation, we introduce PhysicsMind, a unified benchmark with both real and simulation environments that evaluates law-consistent reasoning and generation over three canonical principles: Center of Mass, Lever Equilibrium, and Newton's First Law. PhysicsMind comprises two main tasks: i) VQA tasks, testing whether models can reason and determine physical quantities and values from images or short videos, and ii) Video Generation(VG) tasks, evaluating if predicted motion trajectories obey the same center-of-mass, torque, and inertial constraints as the ground truth. A broad range of recent models and video generation models is evaluated on PhysicsMind and found to rely on appearance heuristics while often violating basic mechanics. These gaps indicate that current scaling and training are still insufficient for robust physical understanding, underscoring PhysicsMind as a focused testbed for physics-aware multimodal models. Our data will be released upon acceptance.