EVolSplat4D: Efficient Volume-based Gaussian Splatting for 4D Urban Scene Synthesis
作者: Sheng Miao, Sijin Li, Pan Wang, Dongfeng Bai, Bingbing Liu, Yue Wang, Andreas Geiger, Yiyi Liao
分类: cs.CV
发布日期: 2026-01-22
💡 一句话要点
EVolSplat4D:高效的体素化高斯溅射方法,用于4D城市场景合成
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 新视角合成 动态场景重建 高斯溅射 体素化表示 前馈网络 自动驾驶仿真 4D场景合成
📋 核心要点
- 现有方法难以平衡动态城市场景新视角合成的重建时间和质量,特别是复杂动态环境下的3D一致性。
- EVolSplat4D通过统一体素化和像素化高斯预测,分别处理近距离静态、动态物体和远景,实现高效高质量的4D场景重建。
- 实验表明,EVolSplat4D在多个数据集上优于现有逐场景优化和前馈方法,在精度和一致性上均有提升。
📝 摘要(中文)
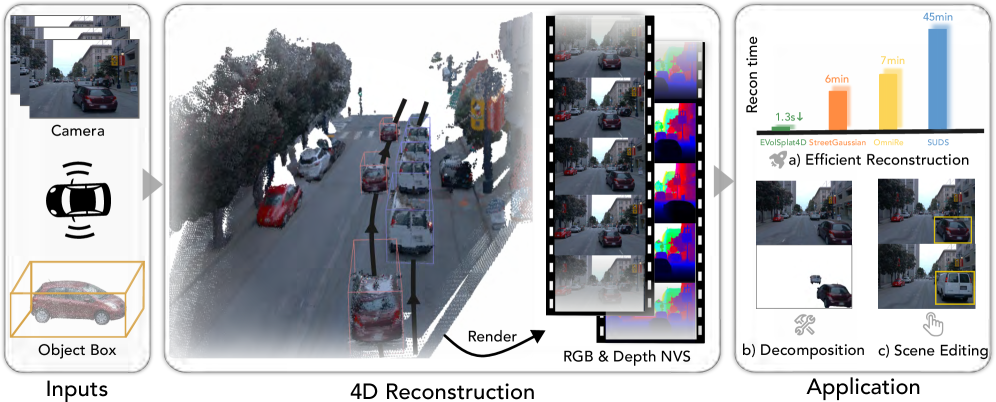
本文提出EVolSplat4D,一个用于动态城市场景新视角合成的前馈框架,旨在平衡重建时间和质量。该方法通过统一基于体素和基于像素的高斯预测,超越了现有的逐像素范式。对于近距离静态区域,直接从3D特征体预测多帧一致的3D高斯几何,并使用语义增强的图像渲染模块预测其外观。对于动态物体,利用以物体为中心的规范空间和运动调整的渲染模块来聚合时间特征,确保在有噪声的运动先验下也能实现稳定的4D重建。远景则通过高效的逐像素高斯分支处理,以确保完整的场景覆盖。在KITTI-360、KITTI、Waymo和PandaSet数据集上的实验结果表明,EVolSplat4D能够以卓越的精度和一致性重建静态和动态环境,优于逐场景优化和最先进的前馈基线。
🔬 方法详解
问题定义:现有神经辐射场(NeRF)和3D高斯溅射(3DGS)方法虽然能实现逼真的新视角合成,但需要耗时的逐场景优化。新兴的前馈方法虽然速度快,但通常采用逐像素高斯表示,在复杂动态环境中聚合多视角预测时容易出现3D不一致性。因此,如何高效且一致地重建动态城市场景是一个关键问题。
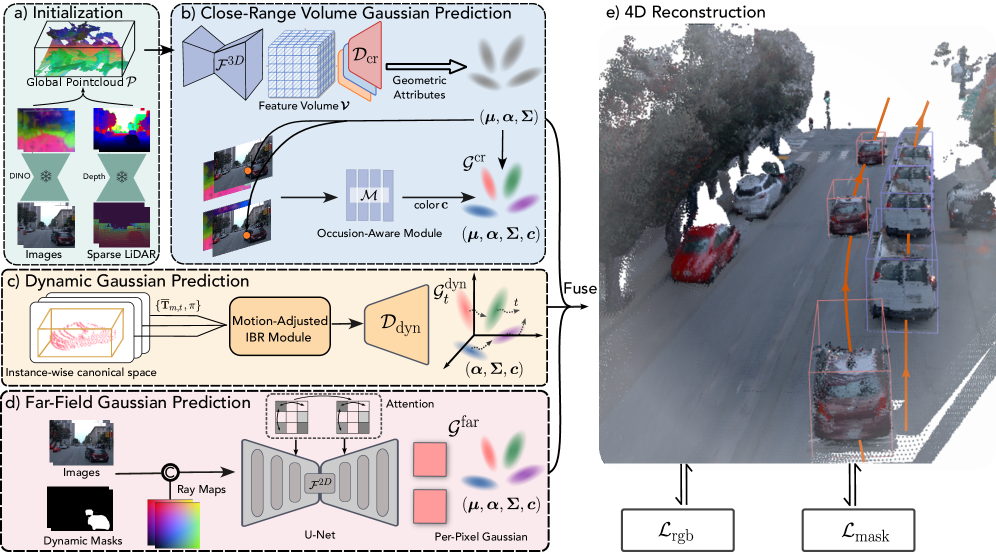
核心思路:EVolSplat4D的核心思路是针对不同场景区域采用不同的高斯表示和渲染策略。对于近距离静态区域,利用3D特征体直接预测3D高斯,保证几何一致性;对于动态物体,引入物体为中心的规范空间和运动调整渲染,处理运动噪声;对于远景,采用高效的逐像素高斯表示,保证场景覆盖。这种混合策略旨在平衡重建质量和效率。
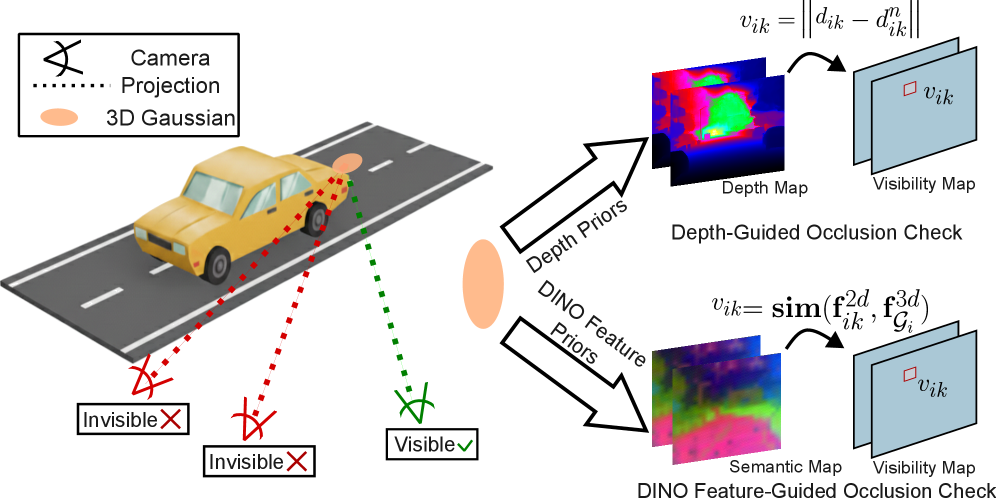
技术框架:EVolSplat4D包含三个主要分支:1) 近距离静态区域分支:从3D特征体预测3D高斯参数,并使用语义增强的图像渲染模块预测外观。2) 动态物体分支:利用物体为中心的规范空间和运动调整渲染模块聚合时间特征。3) 远景分支:使用高效的逐像素高斯表示。整体流程是首先对场景进行分割,然后将不同区域输入到对应的分支进行处理,最后将结果融合得到最终的渲染图像。
关键创新:EVolSplat4D的关键创新在于其混合高斯表示方法,它将基于体素的3D高斯预测与基于像素的2D高斯预测相结合,并针对不同场景区域进行优化。与现有方法相比,EVolSplat4D避免了逐场景优化,同时保证了3D一致性和渲染质量。此外,针对动态物体的运动调整渲染模块也是一个重要的创新点。
关键设计:在近距离静态区域分支中,3D特征体通过3D CNN提取,然后使用MLP预测3D高斯参数。语义增强的图像渲染模块利用语义信息来提高渲染质量。在动态物体分支中,运动调整渲染模块使用光流信息来对齐不同帧的特征。损失函数包括渲染损失、深度损失和正则化项,用于优化高斯参数和运动估计。
🖼️ 关键图片
📊 实验亮点
EVolSplat4D在KITTI-360、KITTI、Waymo和PandaSet数据集上进行了评估,实验结果表明,EVolSplat4D在重建精度和一致性方面均优于现有方法。与逐场景优化方法相比,EVolSplat4D显著提高了重建速度。与最先进的前馈方法相比,EVolSplat4D在动态场景的重建质量方面有显著提升。具体性能数据在论文中详细给出。
🎯 应用场景
EVolSplat4D在自动驾驶仿真、虚拟现实、增强现实等领域具有广泛的应用前景。它可以用于生成逼真的动态城市环境,为自动驾驶算法的训练和测试提供高质量的数据。此外,EVolSplat4D还可以用于创建沉浸式的虚拟现实体验,例如城市漫游和游戏。该研究的未来影响在于推动城市场景的数字化和智能化。
📄 摘要(原文)
Novel view synthesis (NVS) of static and dynamic urban scenes is essential for autonomous driving simulation, yet existing methods often struggle to balance reconstruction time with quality. While state-of-the-art neural radiance fields and 3D Gaussian Splatting approaches achieve photorealism, they often rely on time-consuming per-scene optimization. Conversely, emerging feed-forward methods frequently adopt per-pixel Gaussian representations, which lead to 3D inconsistencies when aggregating multi-view predictions in complex, dynamic environments. We propose EvolSplat4D, a feed-forward framework that moves beyond existing per-pixel paradigms by unifying volume-based and pixel-based Gaussian prediction across three specialized branches. For close-range static regions, we predict consistent geometry of 3D Gaussians over multiple frames directly from a 3D feature volume, complemented by a semantically-enhanced image-based rendering module for predicting their appearance. For dynamic actors, we utilize object-centric canonical spaces and a motion-adjusted rendering module to aggregate temporal features, ensuring stable 4D reconstruction despite noisy motion priors. Far-Field scenery is handled by an efficient per-pixel Gaussian branch to ensure full-scene coverage. Experimental results on the KITTI-360, KITTI, Waymo, and PandaSet datasets show that EvolSplat4D reconstructs both static and dynamic environments with superior accuracy and consistency, outperforming both per-scene optimization and state-of-the-art feed-forward baselines.