Understanding the Transfer Limits of Vision Foundation Models
作者: Shiqi Huang, Yipei Wang, Natasha Thorley, Alexander Ng, Shaheer Saeed, Mark Emberton, Shonit Punwani, Veeru Kasivisvanathan, Dean Barratt, Daniel Alexander, Yipeng Hu
分类: cs.CV, cs.AI
发布日期: 2026-01-22
备注: accepted in ISBI 2026
💡 一句话要点
研究视觉基础模型迁移学习的局限性,强调预训练目标与下游任务对齐的重要性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉基础模型 迁移学习 预训练目标 任务对齐 医学图像分析
📋 核心要点
- 视觉基础模型在下游任务中表现不一,现有预训练目标与下游任务需求存在错配。
- 通过分析预训练目标与下游任务的对齐程度,探究其对迁移学习性能的影响。
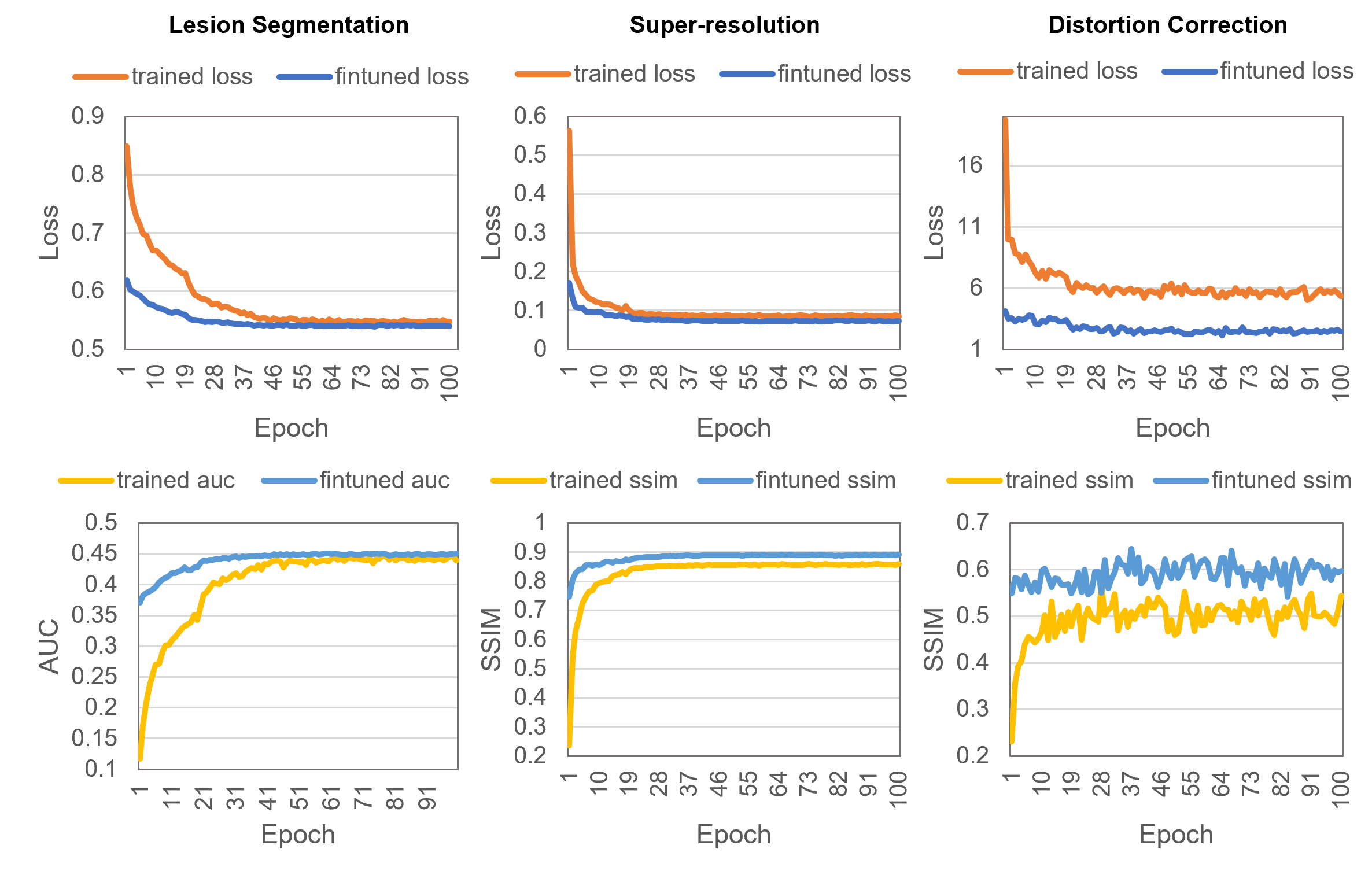
- 实验表明,预训练与下游任务对齐程度越高,模型性能提升越大,收敛速度越快。
📝 摘要(中文)
视觉基础模型(VFMs)虽然投入了大量计算资源,但在下游任务中的提升并不均衡。本文认为,这是由于预训练目标与下游视觉任务的需求不匹配造成的。诸如掩码图像重建或对比学习等预训练策略,旨在学习通用视觉模式或全局语义结构,但这可能与分割、分类或图像合成等下游任务的需求不一致。本文在临床前列腺多参数磁共振成像任务中,评估了基于MAE的ProFound模型和基于对比学习的ProViCNet模型,研究了任务对齐如何影响迁移性能。研究表明,预训练和下游任务之间更好的对齐(通过最大均值差异MMD等指标衡量)与更大的性能提升和更快的收敛速度相关,强调了在设计和分析预训练目标时,考虑下游适用性的重要性。
🔬 方法详解
问题定义:视觉基础模型(VFMs)在各种下游任务中的表现参差不齐,即使经过大量的计算资源投入。现有的预训练方法,如掩码图像重建和对比学习,旨在学习通用的视觉模式或全局语义结构,但这些学习到的表征可能与下游任务(如分割、分类和图像合成)的特定需求不一致。因此,如何设计更有效的预训练目标,使其更好地适应下游任务,是本文要解决的关键问题。
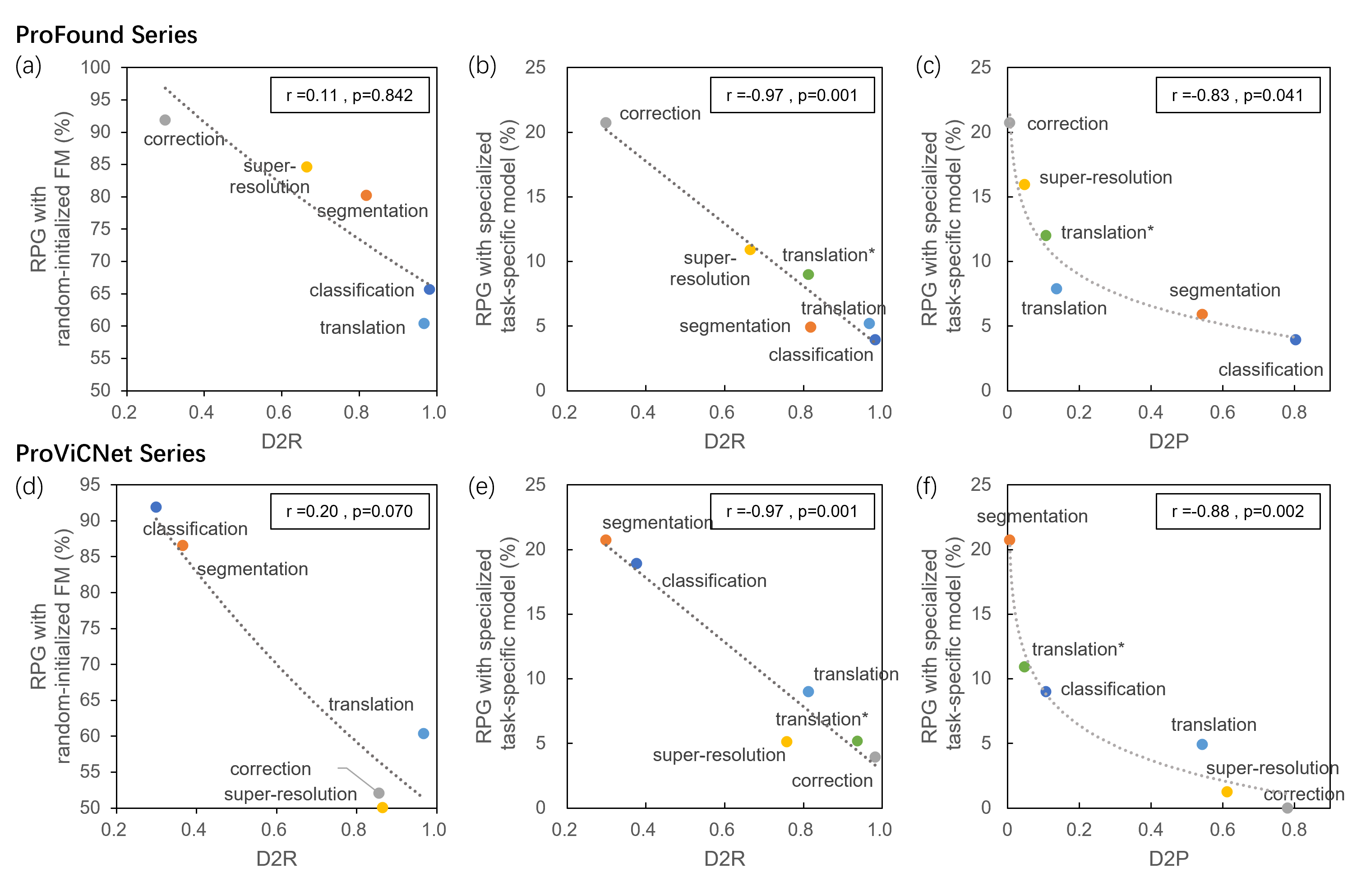
核心思路:本文的核心思路是,预训练目标与下游任务之间的对齐程度直接影响VFMs的迁移学习性能。如果预训练阶段学习到的表征能够更好地适应下游任务的需求,那么模型就能更快地收敛并取得更好的性能。为了量化这种对齐程度,本文采用了最大均值差异(MMD)等散度指标。
技术框架:本文的技术框架主要包括以下几个步骤:1) 选择两个具有代表性的VFMs:一个基于掩码图像重建(MAE)的ProFound模型和一个基于对比学习的ProViCNet模型。2) 在五个前列腺多参数磁共振成像任务上对这两个模型进行评估。3) 使用MMD等指标来衡量预训练和微调前后特征之间的差异,以此评估预训练目标与下游任务的对齐程度。4) 分析对齐程度与模型性能之间的关系。
关键创新:本文的关键创新在于,它将预训练目标与下游任务的对齐程度作为评估VFMs迁移学习性能的重要指标,并提出了使用MMD等散度指标来量化这种对齐程度的方法。此外,本文还通过实验验证了对齐程度与模型性能之间的正相关关系,为设计更有效的预训练目标提供了新的思路。
关键设计:本文的关键设计包括:1) 选择了具有代表性的基于MAE和对比学习的VFMs,以便比较不同预训练策略的影响。2) 选择了临床前列腺多参数磁共振成像任务作为评估平台,因为这些任务具有实际的应用价值,并且对模型的性能提出了较高的要求。3) 使用MMD作为衡量预训练和微调前后特征差异的指标,因为它能够捕捉到特征分布之间的细微差异。4) 通过实验分析了MMD值与模型性能之间的关系,从而验证了对齐程度与模型性能之间的正相关关系。
🖼️ 关键图片
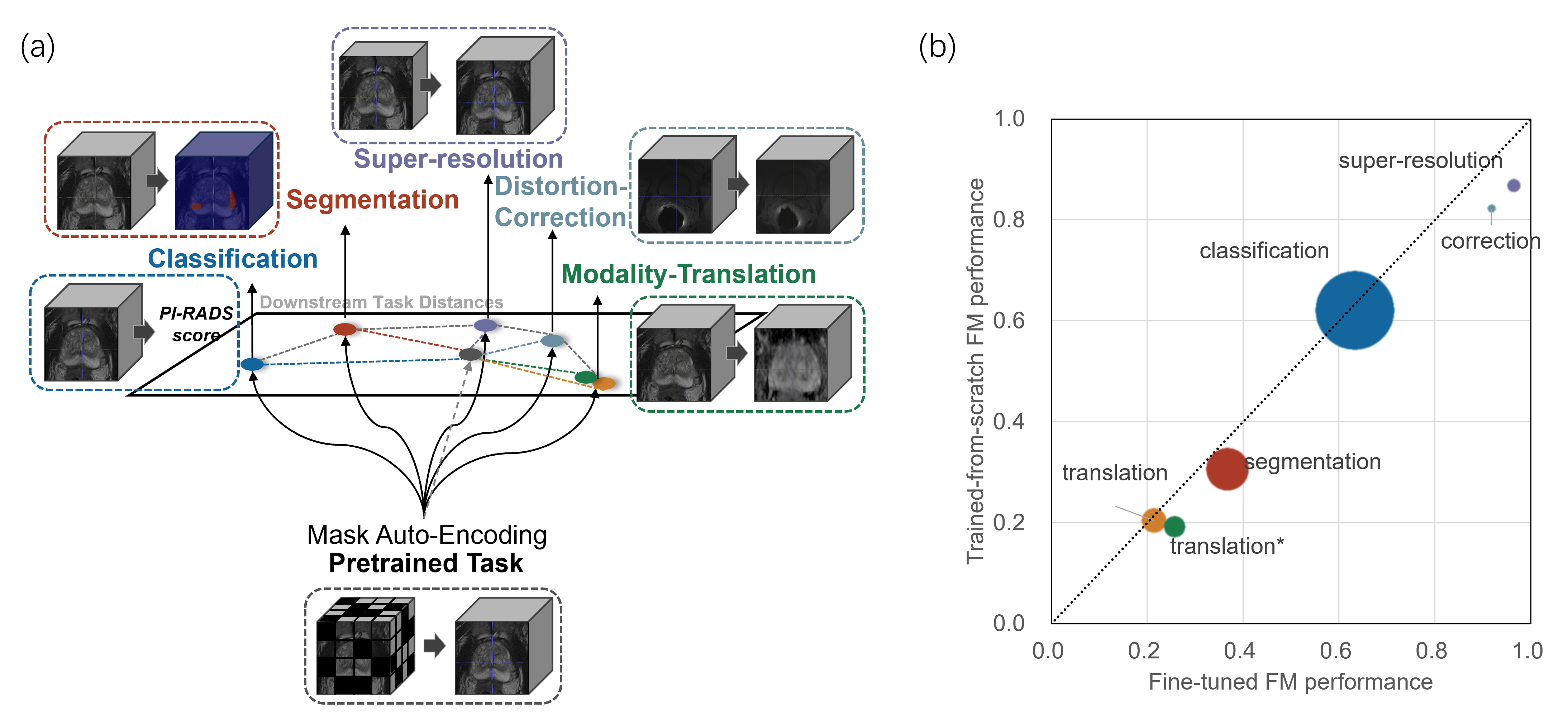
📊 实验亮点
实验结果表明,预训练目标与下游任务之间更好的对齐(通过最大均值差异MMD等指标衡量)与更大的性能提升和更快的收敛速度相关。具体来说,当预训练目标与下游任务更对齐时,模型在分割、分类等任务上的性能提升显著,并且收敛速度更快,这验证了预训练目标设计的重要性。
🎯 应用场景
该研究成果可应用于医学图像分析领域,例如前列腺癌的诊断和治疗。通过设计与特定医学成像任务对齐的预训练目标,可以提高模型的分割、分类和诊断性能,从而辅助医生进行更准确的诊断和治疗方案制定。此外,该研究思路也可以推广到其他视觉任务中,例如自动驾驶、遥感图像分析等。
📄 摘要(原文)
Foundation models leverage large-scale pretraining to capture extensive knowledge, demonstrating generalization in a wide range of language tasks. By comparison, vision foundation models (VFMs) often exhibit uneven improvements across downstream tasks, despite substantial computational investment. We postulate that this limitation arises from a mismatch between pretraining objectives and the demands of downstream vision-and-imaging tasks. Pretraining strategies like masked image reconstruction or contrastive learning shape representations for tasks such as recovery of generic visual patterns or global semantic structures, which may not align with the task-specific requirements of downstream applications including segmentation, classification, or image synthesis. To investigate this in a concrete real-world clinical area, we assess two VFMs, a reconstruction-focused MAE-based model (ProFound) and a contrastive-learning-based model (ProViCNet), on five prostate multiparametric MR imaging tasks, examining how such task alignment influences transfer performance, i.e., from pretraining to fine-tuning. Our findings indicate that better alignment between pretraining and downstream tasks, measured by simple divergence metrics such as maximum-mean-discrepancy (MMD) between the same features before and after fine-tuning, correlates with greater performance improvements and faster convergence, emphasizing the importance of designing and analyzing pretraining objectives with downstream applicability in mind.