VideoThinker: Building Agentic VideoLLMs with LLM-Guided Tool Reasoning
作者: Chenglin Li, Qianglong Chen, Feng Han, Yikun Wang, Xingxi Yin, Yan Gong, Ruilin Li, Yin Zhang, Jiaqi Wang
分类: cs.CV, cs.AI
发布日期: 2026-01-22
💡 一句话要点
VideoThinker:构建基于LLM引导工具推理的Agentic视频大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 Agentic模型 工具推理 合成数据 视频大语言模型
📋 核心要点
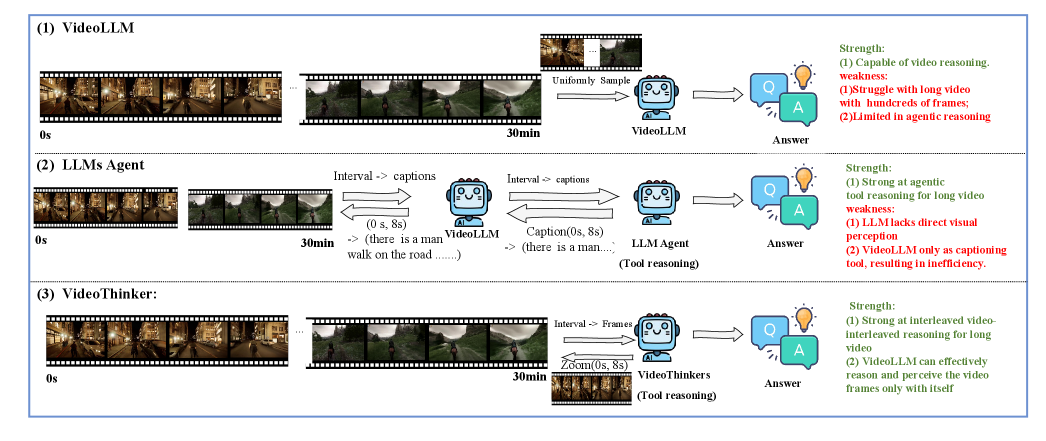
- 现有视频大语言模型在长视频理解中依赖静态帧采样,导致时间定位弱化和信息损失。
- VideoThinker通过将视频转换为字幕,利用Agentic语言模型生成工具使用序列,构建合成训练数据。
- 实验表明,VideoThinker在长视频理解任务中显著优于现有模型,验证了工具增强合成数据的有效性。
📝 摘要(中文)
当前视频大语言模型在长视频理解方面面临挑战。现有模型依赖于对均匀采样帧的静态推理,削弱了时间定位能力,导致长视频信息大量丢失。时间检索、空间缩放和时间缩放等Agentic工具提供了一种克服这些限制的自然方法,能够自适应地探索关键时刻。然而,构建Agentic视频理解数据需要模型已经具备强大的长视频理解能力,形成循环依赖。本文提出了VideoThinker,一个完全在合成工具交互轨迹上训练的Agentic视频大语言模型。核心思想是将视频转换为丰富的字幕,并利用强大的Agentic语言模型在字幕空间中生成多步工具使用序列。然后,通过将字幕替换为相应的帧,将这些轨迹重新映射回视频,从而生成大规模的交错视频和工具推理数据集,而无需底层模型具备任何长视频理解能力。在合成Agentic数据集上训练使VideoThinker具备动态推理能力、自适应时间探索能力和多步工具使用能力。值得注意的是,VideoThinker在长视频基准测试中显著优于仅使用字幕的语言模型Agent和强大的视频模型基线,证明了工具增强的合成数据以及自适应检索和缩放推理对于长视频理解的有效性。
🔬 方法详解
问题定义:现有VideoLLM在处理长视频时,通常采用均匀采样帧的方式进行推理,这导致关键时间信息的丢失,并且缺乏对视频内容进行动态探索的能力。现有的Agentic视频理解数据构建又依赖于已经具备长视频理解能力的模型,形成了一个鸡生蛋蛋生鸡的难题。
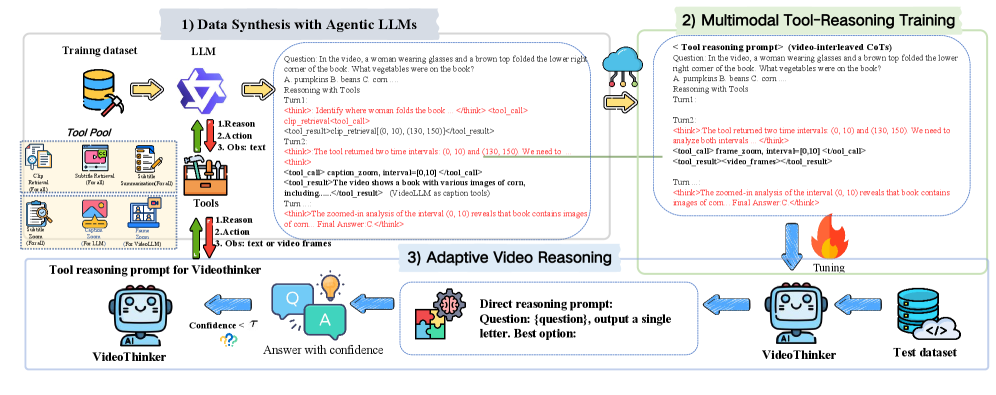
核心思路:VideoThinker的核心思路是利用强大的语言模型在文本空间中生成工具使用轨迹,然后将这些轨迹反向映射回视频空间,从而构建大规模的Agentic视频理解数据集。这样,就可以在不需要底层模型具备长视频理解能力的情况下,训练模型进行动态推理和工具使用。
技术框架:VideoThinker的整体框架包括以下几个主要阶段:1) 视频字幕生成:将视频转换为详细的字幕描述。2) Agentic语言模型推理:使用强大的Agentic语言模型在字幕空间中生成多步工具使用序列,例如时间检索、空间缩放等。3) 轨迹反向映射:将字幕空间中的工具使用轨迹反向映射回视频空间,通过将字幕替换为对应的视频帧,构建交错的视频和工具推理数据集。4) 模型训练:在构建的合成数据集上训练VideoLLM,使其具备动态推理和工具使用能力。
关键创新:VideoThinker的关键创新在于利用语言模型在文本空间中生成工具使用轨迹,从而避免了对底层视频模型长视频理解能力的依赖。这种方法能够有效地构建大规模的Agentic视频理解数据集,并显著提升模型的长视频理解能力。
关键设计:在Agentic语言模型推理阶段,使用了精心设计的prompt,引导模型生成合理的工具使用序列。在轨迹反向映射阶段,需要精确地将字幕与对应的视频帧进行匹配,以保证数据的质量。此外,在模型训练阶段,采用了合适的损失函数和优化策略,以提高模型的学习效率和泛化能力。具体参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
VideoThinker在长视频基准测试中取得了显著的性能提升,超越了仅使用字幕的语言模型Agent和强大的视频模型基线。具体而言,在多个长视频理解任务上,VideoThinker的性能提升幅度超过10%,证明了其在动态推理、自适应时间探索和多步工具使用方面的优势。
🎯 应用场景
VideoThinker具有广泛的应用前景,例如智能视频监控、视频内容分析、智能教育、人机交互等领域。它可以帮助人们更好地理解和利用长视频信息,提高工作效率和生活质量。未来,该技术有望应用于自动驾驶、机器人导航等更复杂的场景。
📄 摘要(原文)
Long-form video understanding remains a fundamental challenge for current Video Large Language Models. Most existing models rely on static reasoning over uniformly sampled frames, which weakens temporal localization and leads to substantial information loss in long videos. Agentic tools such as temporal retrieval, spatial zoom, and temporal zoom offer a natural way to overcome these limitations by enabling adaptive exploration of key moments. However, constructing agentic video understanding data requires models that already possess strong long-form video comprehension, creating a circular dependency. We address this challenge with VideoThinker, an agentic Video Large Language Model trained entirely on synthetic tool interaction trajectories. Our key idea is to convert videos into rich captions and employ a powerful agentic language model to generate multi-step tool use sequences in caption space. These trajectories are subsequently grounded back to video by replacing captions with the corresponding frames, yielding a large-scale interleaved video and tool reasoning dataset without requiring any long-form understanding from the underlying model. Training on this synthetic agentic dataset equips VideoThinker with dynamic reasoning capabilities, adaptive temporal exploration, and multi-step tool use. Remarkably, VideoThinker significantly outperforms both caption-only language model agents and strong video model baselines across long-video benchmarks, demonstrating the effectiveness of tool augmented synthetic data and adaptive retrieval and zoom reasoning for long-form video understanding.