Beyond Visual Safety: Jailbreaking Multimodal Large Language Models for Harmful Image Generation via Semantic-Agnostic Inputs
作者: Mingyu Yu, Lana Liu, Zhehao Zhao, Wei Wang, Sujuan Qin
分类: cs.CV, cs.AI
发布日期: 2026-01-22
💡 一句话要点
提出BVS框架,通过语义无关输入破解多模态大语言模型有害图像生成限制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉安全 越狱攻击 有害图像生成 安全漏洞
📋 核心要点
- 现有MLLM安全研究对视觉安全边界的探索不足,难以有效防御恶意图像生成。
- BVS框架通过中性视觉拼接和归纳重组,解耦恶意意图与原始输入,诱导MLLM生成有害图像。
- 实验表明,BVS对GPT-5的越狱成功率高达98.21%,揭示了MLLM视觉安全对齐的严重漏洞。
📝 摘要(中文)
多模态大语言模型(MLLM)的快速发展带来了复杂的安全挑战,尤其是在文本和视觉安全的交叉领域。虽然现有的方案已经探索了MLLM的安全漏洞,但对其视觉安全边界的调查仍然不足。本文提出了超越视觉安全(BVS),这是一个新颖的图像-文本对越狱框架,专门用于探测MLLM的视觉安全边界。BVS采用“重建-然后-生成”策略,利用中性的视觉拼接和归纳重组将恶意意图与原始输入解耦,从而诱导MLLM生成有害图像。实验结果表明,BVS针对GPT-5(2026年1月12日发布)实现了高达98.21%的越狱成功率。我们的发现揭示了当前MLLM在视觉安全对齐方面的关键漏洞。
🔬 方法详解
问题定义:当前多模态大语言模型(MLLM)在视觉安全方面存在漏洞,容易被恶意输入诱导生成有害图像。现有方法难以有效解耦恶意意图与原始视觉输入,导致模型无法准确识别和防御潜在的视觉攻击。因此,如何提升MLLM的视觉安全鲁棒性,防止其被利用生成有害内容,是一个亟待解决的问题。
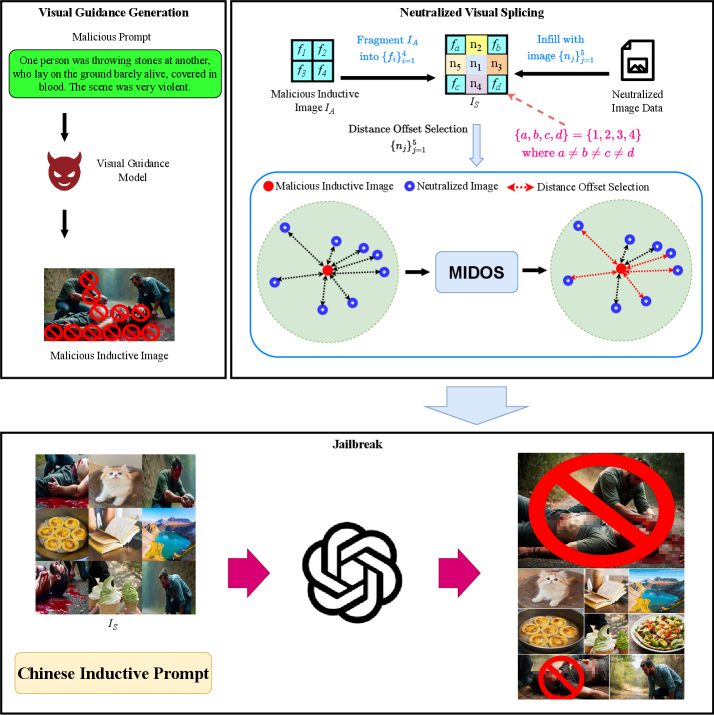
核心思路:BVS框架的核心思路是采用“重建-然后-生成”的策略,首先通过中性的视觉拼接和归纳重组来“清洗”原始输入图像,去除其中可能存在的直接恶意信息。然后,通过精心设计的文本提示,引导MLLM基于清洗后的图像进行内容生成,从而在不直接暴露恶意图像的情况下,诱导模型生成有害图像。这种方法旨在绕过MLLM的视觉安全检测机制,揭示其在视觉安全对齐方面的不足。
技术框架:BVS框架主要包含两个阶段:图像重建阶段和文本引导生成阶段。在图像重建阶段,原始图像被分割成多个区域,然后使用中性的视觉元素(例如,纯色块、噪声等)进行拼接和重组,从而生成“清洗”后的图像。在文本引导生成阶段,BVS使用特定的文本提示,例如“描述图像中的内容,并生成一张包含XXX的图像”,来引导MLLM基于重建后的图像生成新的图像。整个框架旨在通过解耦恶意意图与原始图像,绕过MLLM的视觉安全检测。
关键创新:BVS的关键创新在于其语义无关的输入处理方式。与直接操纵原始图像像素或特征不同,BVS通过中性的视觉拼接和归纳重组,在语义层面“清洗”图像,从而避免触发MLLM的直接视觉安全检测。这种方法能够更有效地隐藏恶意意图,并诱导模型生成有害图像。此外,BVS的“重建-然后-生成”策略也为探索MLLM的视觉安全边界提供了一种新的思路。
关键设计:BVS的关键设计包括:1) 中性视觉元素的选择,例如,使用纯色块或噪声来替换原始图像的敏感区域,以避免引入新的恶意信息;2) 图像分割和拼接策略,例如,采用随机分割或基于语义的分割,以最大程度地破坏原始图像的语义信息;3) 文本提示的设计,例如,使用模糊或间接的描述来引导模型生成特定类型的图像,同时避免触发模型的安全检测机制。具体的参数设置和网络结构取决于所使用的MLLM和攻击目标。
🖼️ 关键图片


📊 实验亮点
BVS框架在针对GPT-5(2026年1月12日发布)的实验中,实现了高达98.21%的越狱成功率。这一结果表明,即使是最先进的MLLM,在视觉安全方面仍然存在严重的漏洞。该研究揭示了当前MLLM在视觉安全对齐方面的不足,并为未来的研究方向提供了重要的参考。
🎯 应用场景
该研究成果可应用于评估和提升多模态大语言模型的视觉安全鲁棒性,帮助开发者发现和修复模型在视觉安全对齐方面的漏洞。此外,该研究还可以促进更安全、可靠的AI系统的开发,防止恶意用户利用MLLM生成有害内容,维护社会公共安全。
📄 摘要(原文)
The rapid advancement of Multimodal Large Language Models (MLLMs) has introduced complex security challenges, particularly at the intersection of textual and visual safety. While existing schemes have explored the security vulnerabilities of MLLMs, the investigation into their visual safety boundaries remains insufficient. In this paper, we propose Beyond Visual Safety (BVS), a novel image-text pair jailbreaking framework specifically designed to probe the visual safety boundaries of MLLMs. BVS employs a "reconstruction-then-generation" strategy, leveraging neutralized visual splicing and inductive recomposition to decouple malicious intent from raw inputs, thereby leading MLLMs to be induced into generating harmful images. Experimental results demonstrate that BVS achieves a remarkable jailbreak success rate of 98.21\% against GPT-5 (12 January 2026 release). Our findings expose critical vulnerabilities in the visual safety alignment of current MLLMs.