Event-VStream: Event-Driven Real-Time Understanding for Long Video Streams
作者: Zhenghui Guo, Yuanbin Man, Junyuan Sheng, Bowen Lin, Ahmed Ahmed, Bo Jiang, Boyuan Zhang, Miao Yin, Sian Jin, Omprakash Gnawal, Chengming Zhang
分类: cs.CV, cs.AI
发布日期: 2026-01-22
💡 一句话要点
Event-VStream:事件驱动的长视频流实时理解框架
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 事件驱动 实时处理 多模态学习 大语言模型 记忆网络 视频流 状态转换
📋 核心要点
- 现有长视频流理解方法依赖固定间隔解码或缓存修剪,导致输出重复或丢失关键时间信息。
- Event-VStream通过检测视频中的事件边界,仅在状态转换时触发语言生成,减少冗余计算。
- Event-VStream构建持久记忆库,整合事件嵌入,实现长时程推理,并在多个数据集上取得显著提升。
📝 摘要(中文)
针对多模态大语言模型在长视频流实时理解中存在的冗余帧处理和快速遗忘过去上下文的问题,本文提出了Event-VStream,一个事件感知的框架,将连续视频表示为一系列离散的、语义连贯的事件。该系统通过整合运动、语义和预测线索来检测有意义的状态转换,并且仅在这些边界处触发语言生成。每个事件的嵌入被整合到一个持久的记忆库中,从而实现长时程推理并保持低延迟。在OVOBench-Realtime和长时Ego4D评估中,Event-VStream取得了具有竞争力的性能。相比VideoLLM-Online-8B基线,在OVOBench-Realtime上提高了+10.4个点,性能接近Flash-VStream-7B,同时仅使用了通用的LLaMA-3-8B文本骨干网络,并且在2小时的Ego4D流上保持了约70%的GPT-5胜率。
🔬 方法详解
问题定义:现有的多模态大语言模型在处理长视频流时,面临着两个主要问题:一是冗余帧处理,即对视频中大量无意义的帧进行重复计算,浪费资源;二是快速遗忘过去上下文,难以进行长时程推理,导致理解不完整。现有方法,如固定间隔解码,会产生重复输出;而缓存修剪则会丢弃关键的时间信息。
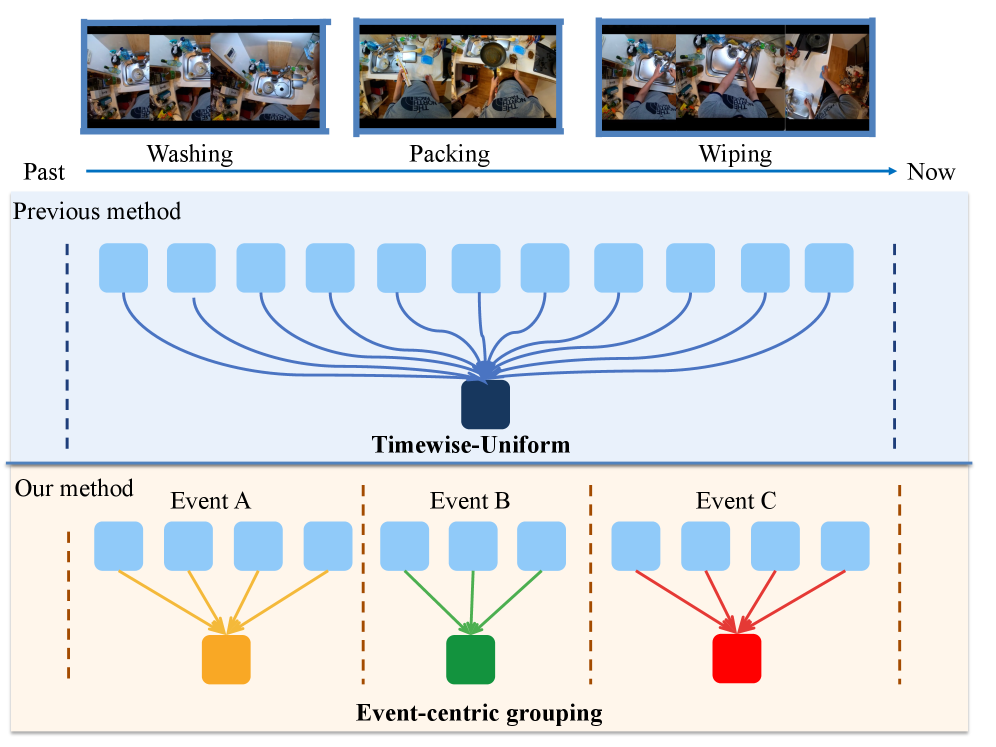
核心思路:Event-VStream的核心思路是将连续的视频流分解为一系列离散的、语义连贯的事件。通过检测视频中的事件边界(即有意义的状态转换),仅在这些边界处触发语言生成。这样可以避免对冗余帧的重复处理,并减少计算量。同时,将每个事件的嵌入存储到持久的记忆库中,从而实现长时程推理。
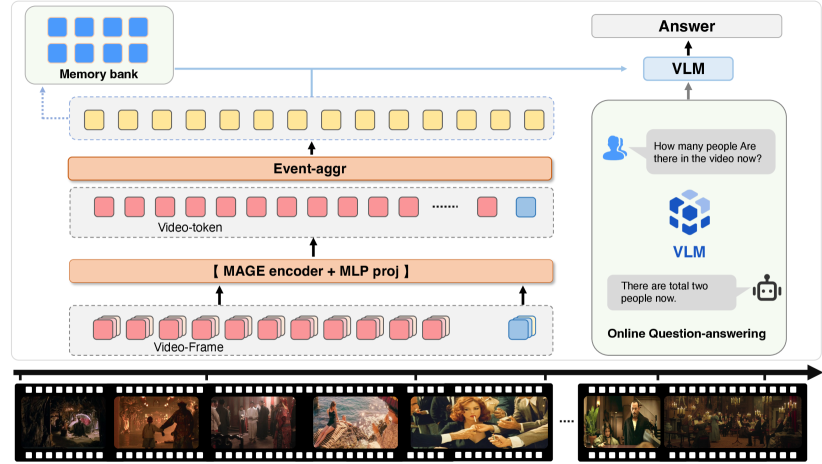
技术框架:Event-VStream的整体框架包含以下几个主要模块:1) 事件检测模块:该模块通过整合运动、语义和预测线索来检测视频中的事件边界。2) 语言生成模块:该模块仅在事件边界处被触发,生成对当前事件的描述。3) 记忆库模块:该模块用于存储每个事件的嵌入,并支持长时程推理。框架首先接收视频流,事件检测模块识别事件边界,然后语言生成模块根据当前事件和记忆库中的历史信息生成描述,最后将当前事件的嵌入更新到记忆库中。
关键创新:Event-VStream的关键创新在于其事件感知的处理方式。与传统的基于帧的处理方法不同,Event-VStream只关注视频中发生状态转换的关键时刻,从而大大减少了计算量,并提高了效率。此外,持久记忆库的设计使得系统能够进行长时程推理,更好地理解视频内容。
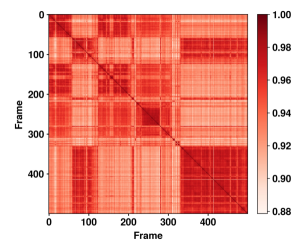
关键设计:事件检测模块融合了多种线索,包括运动信息(例如光流)、语义信息(例如目标检测结果)和预测信息(例如对未来帧的预测)。这些线索被整合到一个统一的框架中,用于判断当前帧是否为事件边界。记忆库采用了一种基于嵌入的存储方式,每个事件都被表示为一个向量,并存储在记忆库中。在进行长时程推理时,系统会检索记忆库中相关的事件,并将其与当前事件进行融合。
🖼️ 关键图片
📊 实验亮点
Event-VStream在OVOBench-Realtime数据集上相比VideoLLM-Online-8B基线提高了10.4个点,并且在性能上接近Flash-VStream-7B,尽管Event-VStream仅使用了通用的LLaMA-3-8B文本骨干网络。在2小时的Ego4D长视频流测试中,Event-VStream保持了约70%的GPT-5胜率,表明其在长时程理解方面具有显著优势。
🎯 应用场景
Event-VStream具有广泛的应用前景,例如智能监控、自动驾驶、视频摘要、人机交互等领域。在智能监控中,它可以用于实时检测异常事件并发出警报。在自动驾驶中,它可以用于理解周围环境并做出决策。在视频摘要中,它可以用于提取视频的关键片段。在人机交互中,它可以用于理解用户的意图并做出相应的反应。该研究的实际价值在于提高了长视频流理解的效率和准确性,未来可能推动视频理解技术在更多场景落地。
📄 摘要(原文)
Real-time understanding of long video streams remains challenging for multimodal large language models (VLMs) due to redundant frame processing and rapid forgetting of past context. Existing streaming systems rely on fixed-interval decoding or cache pruning, which either produce repetitive outputs or discard crucial temporal information. We introduce Event-VStream, an event-aware framework that represents continuous video as a sequence of discrete, semantically coherent events. Our system detects meaningful state transitions by integrating motion, semantic, and predictive cues, and triggers language generation only at those boundaries. Each event embedding is consolidated into a persistent memory bank, enabling long-horizon reasoning while maintaining low latency. Across OVOBench-Realtime, and long-form Ego4D evaluations, Event-VStream achieves competitive performance. It improves over a VideoLLM-Online-8B baseline by +10.4 points on OVOBench-Realtime, achieves performance close to Flash-VStream-7B despite using only a general-purpose LLaMA-3-8B text backbone, and maintains around 70% GPT-5 win rate on 2-hour Ego4D streams.