Evolving Without Ending: Unifying Multimodal Incremental Learning for Continual Panoptic Perception
作者: Bo Yuan, Danpei Zhao, Wentao Li, Tian Li, Zhiguo Jiang
分类: cs.CV
发布日期: 2026-01-22
备注: arXiv admin note: substantial text overlap with arXiv:2407.14242
💡 一句话要点
提出CPP模型,统一多模态增量学习,实现持续全景感知
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续学习 多模态学习 全景感知 跨模态对齐 知识蒸馏 灾难性遗忘 增量学习
📋 核心要点
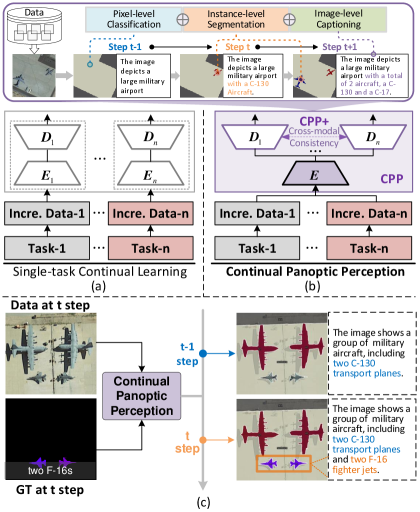
- 传统持续学习主要集中于单任务,限制了其在多任务和多模态场景中的潜力,且存在灾难性遗忘和语义混淆问题。
- 提出CPP模型,通过协同跨模态编码器、可塑性知识继承模块和跨模态一致性约束,解决多模态增量学习中的灾难性遗忘和语义对齐问题。
- 实验结果表明,该模型在多模态数据集和多种持续学习任务中表现出色,尤其是在细粒度持续学习任务中。
📝 摘要(中文)
本文将持续学习(CL)扩展到持续全景感知(CPP),通过像素级、实例级和图像级联合解释,整合多模态和多任务CL,以增强全面的图像感知。我们形式化了多模态场景下的CL任务,并提出了一个端到端的持续全景感知模型。具体而言,CPP模型采用协同跨模态编码器(CCE)进行多模态嵌入。我们还提出了一个通过对比特征蒸馏和实例蒸馏实现的可塑性知识继承模块,以任务交互增强的方式解决灾难性遗忘问题。此外,我们提出了跨模态一致性约束并开发了CPP+,确保多任务增量场景下模型更新的多模态语义对齐。此外,我们提出的模型采用非对称伪标签方式,无需示例回放即可实现模型演进。在多模态数据集和各种CL任务上的大量实验表明了所提出模型的优越性,尤其是在细粒度CL任务中。
🔬 方法详解
问题定义:现有的持续学习方法主要集中在单任务场景,无法有效处理多模态和多任务的持续学习问题。在多模态场景下,由于跨模态对齐的语义混淆,以及灾难性遗忘问题,导致模型在增量训练过程中性能严重下降。因此,需要解决多模态持续学习中的灾难性遗忘和语义对齐问题。
核心思路:本文的核心思路是通过协同跨模态编码器(CCE)实现多模态特征的有效嵌入,利用可塑性知识继承模块缓解灾难性遗忘,并通过跨模态一致性约束确保多模态语义对齐。通过非对称伪标签方式,避免了对旧数据的回放,从而实现模型的持续演进。
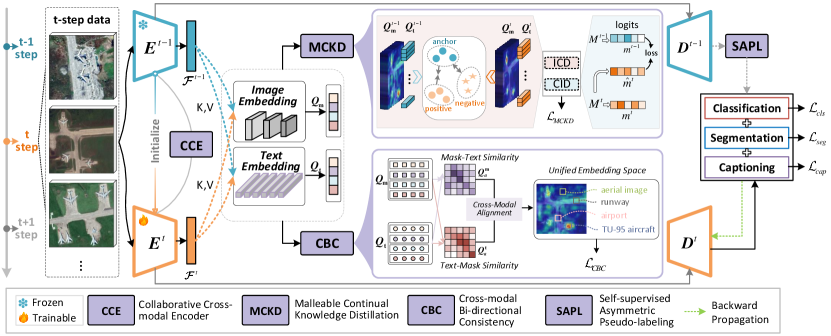
技术框架:CPP模型主要包含以下几个模块:1) 协同跨模态编码器(CCE),用于提取多模态特征;2) 可塑性知识继承模块,通过对比特征蒸馏和实例蒸馏,保留旧知识并适应新知识;3) 跨模态一致性约束,保证不同模态之间的语义一致性;4) 非对称伪标签模块,用于生成伪标签,辅助模型训练,避免灾难性遗忘。
关键创新:本文的关键创新在于:1) 将持续学习扩展到持续全景感知(CPP)任务,整合了多模态和多任务学习;2) 提出了协同跨模态编码器(CCE),用于有效融合多模态特征;3) 提出了可塑性知识继承模块,通过对比特征蒸馏和实例蒸馏,缓解灾难性遗忘;4) 提出了跨模态一致性约束,保证多模态语义对齐;5) 提出了非对称伪标签方法,无需示例回放即可实现模型演进。
关键设计:在可塑性知识继承模块中,采用了对比特征蒸馏和实例蒸馏两种方式,分别从特征层面和实例层面保留旧知识。跨模态一致性约束通过最小化不同模态特征之间的差异来实现语义对齐。非对称伪标签模块采用不同的置信度阈值来生成伪标签,以平衡新旧知识的学习。
🖼️ 关键图片

📊 实验亮点
实验结果表明,提出的CPP模型在多模态数据集和多种持续学习任务中表现出色,尤其是在细粒度持续学习任务中。相较于现有方法,CPP模型在多个指标上取得了显著提升,证明了其在解决多模态持续学习问题上的有效性。具体性能数据未知,但强调了优越性。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人感知、智能监控等领域。通过持续学习,模型能够不断适应新的环境和任务,提高感知系统的鲁棒性和泛化能力。例如,在自动驾驶中,模型可以不断学习新的交通场景和交通规则,从而提高驾驶安全性。
📄 摘要(原文)
Continual learning (CL) is a great endeavour in developing intelligent perception AI systems. However, the pioneer research has predominantly focus on single-task CL, which restricts the potential in multi-task and multimodal scenarios. Beyond the well-known issue of catastrophic forgetting, the multi-task CL also brings semantic obfuscation across multimodal alignment, leading to severe model degradation during incremental training steps. In this paper, we extend CL to continual panoptic perception (CPP), integrating multimodal and multi-task CL to enhance comprehensive image perception through pixel-level, instance-level, and image-level joint interpretation. We formalize the CL task in multimodal scenarios and propose an end-to-end continual panoptic perception model. Concretely, CPP model features a collaborative cross-modal encoder (CCE) for multimodal embedding. We also propose a malleable knowledge inheritance module via contrastive feature distillation and instance distillation, addressing catastrophic forgetting from task-interactive boosting manner. Furthermore, we propose a cross-modal consistency constraint and develop CPP+, ensuring multimodal semantic alignment for model updating under multi-task incremental scenarios. Additionally, our proposed model incorporates an asymmetric pseudo-labeling manner, enabling model evolving without exemplar replay. Extensive experiments on multimodal datasets and diverse CL tasks demonstrate the superiority of the proposed model, particularly in fine-grained CL tasks.