Explainable Deepfake Detection with RL Enhanced Self-Blended Images
作者: Ning Jiang, Dingheng Zeng, Yanhong Liu, Haiyang Yi, Shijie Yu, Minghe Weng, Haifeng Shen, Ying Li
分类: cs.CV
发布日期: 2026-01-22
备注: Accepted at ICASSP 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于强化学习增强的自混合图像可解释Deepfake检测方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Deepfake检测 可解释性AI 强化学习 自混合图像 Chain-of-Thought 多模态大语言模型 数据增强
📋 核心要点
- 现有Deepfake检测方法缺乏可解释性,且高质量标注数据难以获取,限制了多模态大语言模型在该领域的应用。
- 提出一种基于自混合图像的自动CoT数据生成框架,并结合强化学习增强Deepfake检测,降低标注成本。
- 实验表明,该方法在多个跨数据集基准测试中达到SOTA水平,验证了CoT数据构建流程和强化学习机制的有效性。
📝 摘要(中文)
现有Deepfake检测方法缺乏可解释性输出。随着多模态大型语言模型(MLLM)的兴起,研究人员开始探索其在可解释Deepfake检测中的应用。然而,将MLLM应用于此任务的主要障碍是缺乏高质量的、具有详细伪造归因注释的数据集,因为文本注释成本高昂且具有挑战性,特别是对于高保真伪造图像或视频。此外,多项研究表明,强化学习(RL)可以显著提高视觉任务的性能,尤其是在提高跨域泛化方面。为了促进主流MLLM框架在Deepfake检测中的应用,并降低注释成本,以及研究RL在此背景下的潜力,我们提出了一种基于自混合图像的自动Chain-of-Thought(CoT)数据生成框架,以及一种RL增强的Deepfake检测框架。大量实验验证了我们的CoT数据构建流程、定制奖励机制和反馈驱动的合成数据生成方法的有效性。我们的方法在多个跨数据集基准测试中实现了与最先进方法(SOTA)相媲美的性能。
🔬 方法详解
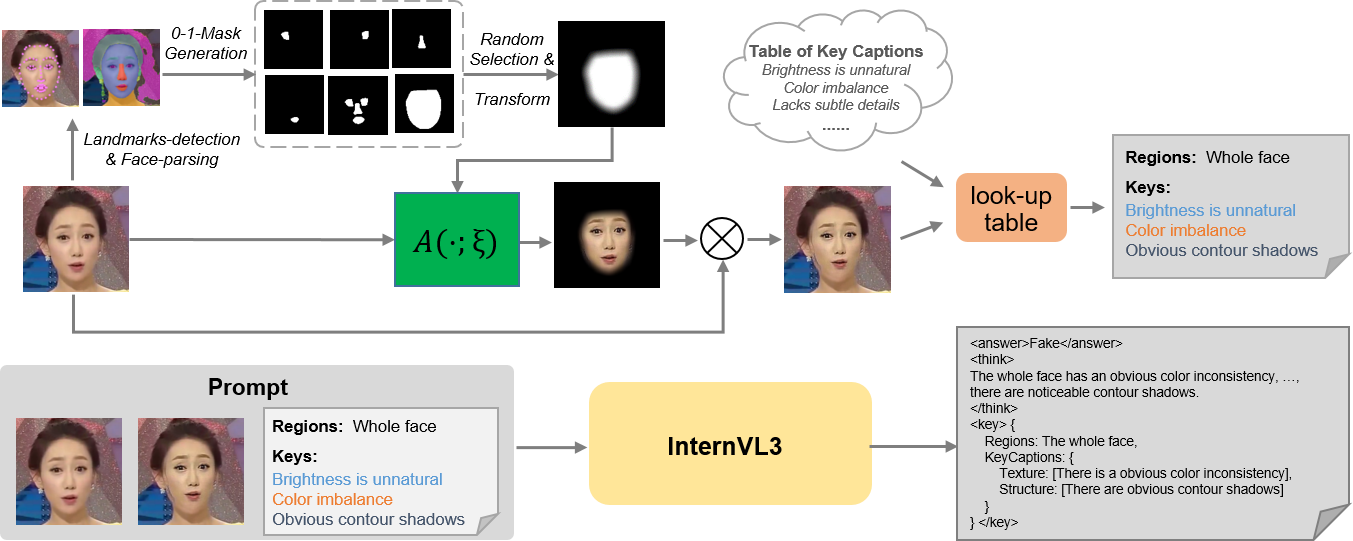
问题定义:当前Deepfake检测方法主要集中在判别真伪,缺乏对伪造区域和手段的解释能力。同时,训练可解释Deepfake检测模型需要大量带有详细伪造归因注释的数据,而人工标注成本高昂,特别是对于高保真Deepfake图像,标注难度更大。
核心思路:论文的核心思路是利用自混合图像(Self-Blended Images)自动生成带有Chain-of-Thought(CoT)推理过程的标注数据,并结合强化学习(RL)优化Deepfake检测模型,从而在降低标注成本的同时,提高模型的可解释性和跨域泛化能力。
技术框架:该框架包含两个主要部分:1) 基于自混合图像的CoT数据生成流程:通过将图像的不同区域进行混合,并利用大语言模型自动生成描述伪造区域和手段的CoT推理过程。2) RL增强的Deepfake检测框架:利用生成的CoT数据训练Deepfake检测模型,并使用强化学习方法优化模型的跨域泛化能力。
关键创新:该方法最重要的创新点在于利用自混合图像和CoT技术,实现了自动化的、低成本的Deepfake数据标注。与传统的人工标注相比,该方法可以显著降低标注成本,并生成更丰富、更具解释性的标注信息。此外,结合强化学习进一步提升了模型的泛化能力。
关键设计:在CoT数据生成方面,关键在于如何设计自混合策略,以及如何利用大语言模型生成高质量的CoT推理过程。在RL增强方面,关键在于如何设计合适的奖励函数,以引导模型学习到更具泛化能力的特征表示。具体的网络结构和损失函数细节在论文中提供了更详细的描述(具体细节未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在多个跨数据集基准测试中取得了与SOTA方法相媲美的性能,验证了CoT数据构建流程和强化学习机制的有效性。具体性能数据和提升幅度可在论文原文中找到(具体数据未知)。
🎯 应用场景
该研究成果可应用于在线社交媒体平台、新闻媒体机构等,用于自动检测和解释Deepfake内容,提高公众对虚假信息的辨别能力,维护网络信息安全。同时,该方法也可推广至其他需要可解释性AI模型的领域,如医疗诊断、金融风控等。
📄 摘要(原文)
Most prior deepfake detection methods lack explainable outputs. With the growing interest in multimodal large language models (MLLMs), researchers have started exploring their use in interpretable deepfake detection. However, a major obstacle in applying MLLMs to this task is the scarcity of high-quality datasets with detailed forgery attribution annotations, as textual annotation is both costly and challenging - particularly for high-fidelity forged images or videos. Moreover, multiple studies have shown that reinforcement learning (RL) can substantially enhance performance in visual tasks, especially in improving cross-domain generalization. To facilitate the adoption of mainstream MLLM frameworks in deepfake detection with reduced annotation cost, and to investigate the potential of RL in this context, we propose an automated Chain-of-Thought (CoT) data generation framework based on Self-Blended Images, along with an RL-enhanced deepfake detection framework. Extensive experiments validate the effectiveness of our CoT data construction pipeline, tailored reward mechanism, and feedback-driven synthetic data generation approach. Our method achieves performance competitive with state-of-the-art (SOTA) approaches across multiple cross-dataset benchmarks. Implementation details are available at https://github.com/deon1219/rlsbi.