Towards Understanding Best Practices for Quantization of Vision-Language Models
作者: Gautom Das, Vincent La, Ethan Lau, Abhinav Shrivastava, Matthew Gwilliam
分类: cs.CV
发布日期: 2026-01-21
备注: 15 pages, 12 figures, 1 table
🔗 代码/项目: GITHUB
💡 一句话要点
研究视觉-语言模型量化的最佳实践,提升多模态任务效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 量化 模型压缩 多模态学习 低比特量化
📋 核心要点
- 现有视觉-语言模型部署受限于高昂的计算资源需求,尤其是大型语言模型对内存和计算速度的要求。
- 该研究探索了多种量化方法在视觉-语言模型pipeline中的应用,旨在降低模型大小和延迟,同时保持性能。
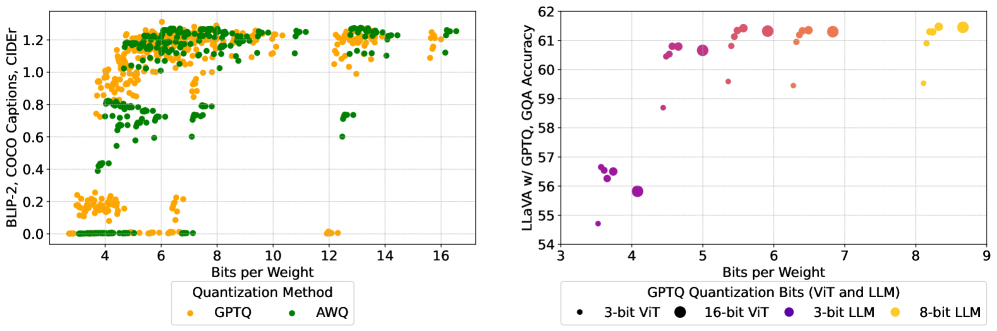
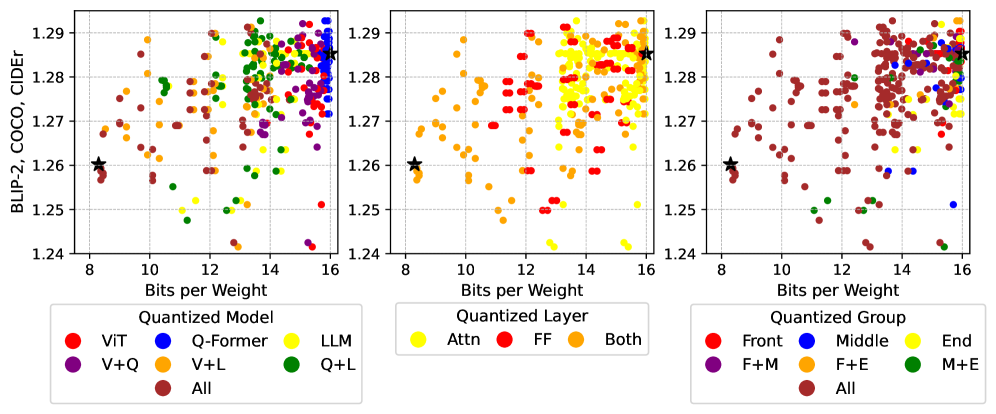
- 实验结果表明,视觉Transformer和语言模型在性能上具有可比性,并且对语言模型进行低比特量化可以在降低资源消耗的同时保持高精度。
📝 摘要(中文)
大型语言模型(LLM)在各种任务中表现出色,但最先进的系统需要配备大量内存的快速GPU。为了降低这些系统的内存和延迟,从业者通常以半精度量化其学习到的参数。越来越多的研究致力于使用更积极的位宽来保持模型性能,并且已经完成了一些工作以将这些策略应用于其他模型,例如视觉Transformer。在本研究中,我们调查了各种量化方法(包括最先进的GPTQ和AWQ)如何有效地应用于由视觉模型、语言模型及其连接器组成的多模态pipeline。我们研究了captioning、检索和问答的性能如何受到位宽、量化方法以及量化pipeline部分的影响。结果表明,尽管参数大小存在显着差异,但ViT和LLM在模型性能中表现出相当的重要性,并且LLM的低位量化以降低的每权重比特数(bpw)实现了高精度。这些发现为MLLM的有效部署提供了实践见解,并突出了探索以理解多模态模型中组件敏感性的价值。我们的代码可在https://github.com/gautomdas/mmq获得。
🔬 方法详解
问题定义:现有视觉-语言模型(MLLM)部署面临高内存和高延迟的挑战,尤其是在资源受限的环境中。直接部署大型模型成本高昂,而现有量化方法在MLLM上的应用效果和最佳实践尚不明确。因此,需要研究适用于MLLM的有效量化策略,以在降低资源需求的同时保持模型性能。
核心思路:该研究的核心思路是通过系统性地评估不同的量化方法(包括GPTQ和AWQ)在MLLM pipeline的不同组件(视觉模型、语言模型和连接器)上的效果,从而找到最佳的量化策略。研究关注位宽、量化方法和量化位置对下游任务性能的影响,旨在揭示MLLM中不同组件的敏感性,并为高效部署提供指导。
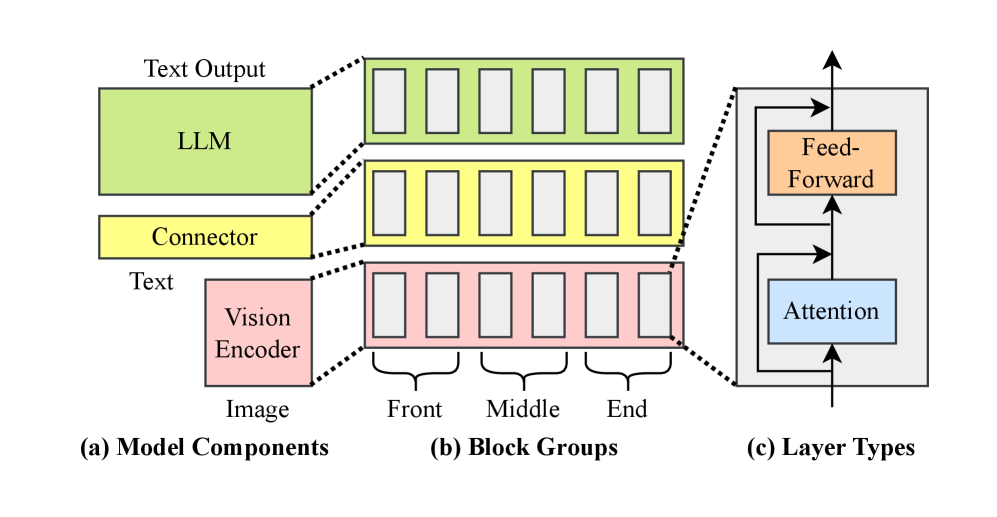
技术框架:该研究的技术框架主要包括以下几个部分:1) 选择典型的MLLM架构,包含视觉模型(ViT)、语言模型(LLM)以及连接它们的模块;2) 选取多种量化方法,包括GPTQ和AWQ等;3) 将这些量化方法应用于MLLM pipeline的不同部分,例如只量化LLM、只量化ViT或者同时量化两者;4) 在多个下游任务(如图像描述、图像检索和视觉问答)上评估量化后模型的性能;5) 分析不同量化策略对模型性能的影响,并找出最佳的量化配置。
关键创新:该研究的关键创新在于系统性地研究了量化方法在MLLM pipeline中的应用,并揭示了不同组件对量化的敏感性。与以往的研究主要关注单一模型(如LLM或ViT)的量化不同,该研究关注整个MLLM pipeline,并探讨了不同组件之间的相互作用。此外,该研究还发现,尽管参数大小存在差异,但ViT和LLM在模型性能中具有可比的重要性,这为MLLM的量化提供了新的视角。
关键设计:该研究的关键设计包括:1) 选择了具有代表性的MLLM架构,确保研究结果具有一定的通用性;2) 采用了多种先进的量化方法,包括GPTQ和AWQ,以覆盖不同的量化策略;3) 在多个下游任务上评估模型性能,以全面评估量化效果;4) 详细分析了不同量化策略对模型性能的影响,并给出了实际部署的建议。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使在较低的位宽下,对LLM进行量化也能保持较高的精度。研究发现,ViT和LLM在模型性能中具有相似的重要性,尽管它们的参数大小差异很大。通过对MLLM pipeline的不同部分进行量化,该研究为高效部署MLLM提供了实用的指导。
🎯 应用场景
该研究成果可应用于各种需要部署视觉-语言模型的场景,例如移动设备上的图像搜索、智能助手中的视觉问答、以及资源受限环境下的多模态内容理解。通过量化降低模型大小和延迟,可以使这些应用在更广泛的设备上运行,并提升用户体验。未来的研究可以进一步探索更先进的量化技术,并将其应用于更复杂的MLLM架构。
📄 摘要(原文)
Large language models (LLMs) deliver impressive results for a variety of tasks, but state-of-the-art systems require fast GPUs with large amounts of memory. To reduce both the memory and latency of these systems, practitioners quantize their learned parameters, typically at half precision. A growing body of research focuses on preserving the model performance with more aggressive bit widths, and some work has been done to apply these strategies to other models, like vision transformers. In our study we investigate how a variety of quantization methods, including state-of-the-art GPTQ and AWQ, can be applied effectively to multimodal pipelines comprised of vision models, language models, and their connectors. We address how performance on captioning, retrieval, and question answering can be affected by bit width, quantization method, and which portion of the pipeline the quantization is used for. Results reveal that ViT and LLM exhibit comparable importance in model performance, despite significant differences in parameter size, and that lower-bit quantization of the LLM achieves high accuracy at reduced bits per weight (bpw). These findings provide practical insights for efficient deployment of MLLMs and highlight the value of exploration for understanding component sensitivities in multimodal models. Our code is available at https://github.com/gautomdas/mmq.