Iterative Refinement Improves Compositional Image Generation
作者: Shantanu Jaiswal, Mihir Prabhudesai, Nikash Bhardwaj, Zheyang Qin, Amir Zadeh, Chuan Li, Katerina Fragkiadaki, Deepak Pathak
分类: cs.CV, cs.AI, cs.LG, cs.RO
发布日期: 2026-01-21
备注: Project webpage: https://iterative-img-gen.github.io/
💡 一句话要点
提出迭代优化框架,利用视觉-语言模型反馈提升组合图像生成质量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到图像生成 组合图像生成 迭代优化 视觉-语言模型 自我校正
📋 核心要点
- 现有文本到图像模型在处理复杂组合提示时面临挑战,难以同时满足多个对象、关系和属性约束。
- 论文提出一种迭代优化策略,利用视觉-语言模型作为评论者,逐步细化图像生成结果,实现自我校正。
- 实验表明,该方法在多个基准测试中显著提升了图像生成的质量和组合性,并获得了人类评估者的青睐。
📝 摘要(中文)
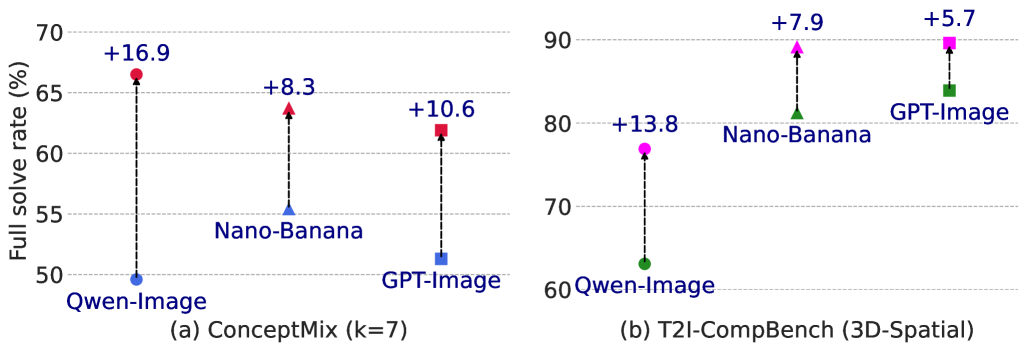
文本到图像(T2I)模型取得了显著进展,但仍然难以处理需要同时处理多个对象、关系和属性的复杂提示。现有的推理时策略,如带有验证器的并行采样或简单地增加去噪步骤,可以改善提示对齐,但对于必须满足许多约束的丰富组合设置仍然不足。受到大型语言模型中思维链推理成功的启发,我们提出了一种迭代测试时策略,其中T2I模型在多个步骤中逐步细化其生成结果,并由视觉-语言模型作为循环中的评论者提供反馈。我们的方法简单,不需要外部工具或先验知识,并且可以灵活地应用于各种图像生成器和视觉-语言模型。经验表明,我们在图像生成基准测试中获得了持续的收益:在ConceptMix(k=7)上,所有正确率提高了16.9%;在T2I-CompBench(3D-Spatial类别)上提高了13.8%;与计算量匹配的并行采样相比,在Visual Jenga场景分解上提高了12.5%。除了定量收益外,迭代细化通过将复杂的提示分解为顺序校正来产生更忠实的生成结果,人类评估者在58.7%的时间内更喜欢我们的方法,而并行基线为41.3%。总之,这些发现突出了迭代自我校正作为组合图像生成的一种广泛适用的原则。
🔬 方法详解
问题定义:现有的文本到图像生成模型在处理复杂场景,特别是需要精确控制多个对象及其相互关系的场景时,表现不佳。简单地增加采样次数或使用验证器并不能有效解决这个问题,因为这些方法无法有效地分解和逐步满足复杂的约束条件。现有方法的痛点在于缺乏一种有效的机制来迭代地改进生成结果,使其更符合复杂的文本描述。
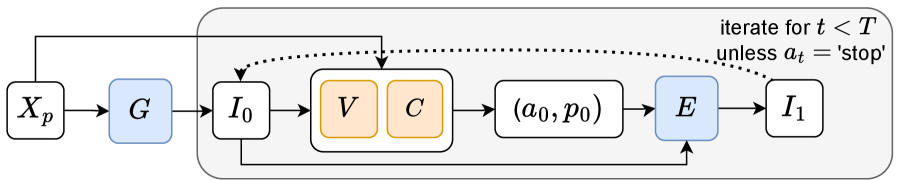
核心思路:论文的核心思路是借鉴大型语言模型中的思维链推理,将复杂的图像生成任务分解为一系列迭代的细化步骤。在每个步骤中,模型生成图像,然后使用视觉-语言模型评估生成结果与文本描述的匹配程度,并根据评估结果进行修正。通过这种迭代的自我校正过程,模型可以逐步逼近理想的生成结果。
技术框架:整体框架包含一个文本到图像生成模型和一个视觉-语言模型。首先,文本到图像生成模型根据文本提示生成初始图像。然后,视觉-语言模型评估生成的图像与文本提示的匹配程度,并生成反馈信息。最后,文本到图像生成模型根据反馈信息调整生成结果,重复这个过程多次,直到生成满意的图像。
关键创新:最重要的技术创新点在于将视觉-语言模型引入到图像生成的迭代优化循环中,作为生成结果的评论者。与现有方法相比,这种方法能够更有效地利用视觉-语言模型的知识来指导图像生成过程,从而生成更符合文本描述的图像。
关键设计:论文的关键设计包括:1) 如何选择合适的视觉-语言模型作为评论者;2) 如何设计视觉-语言模型的反馈信息,使其能够有效地指导图像生成模型的修正;3) 如何控制迭代的次数,以在生成质量和计算成本之间取得平衡。具体参数设置和网络结构细节在论文中未明确给出,属于未知信息。
🖼️ 关键图片
📊 实验亮点
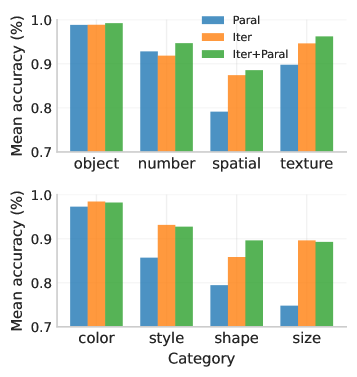
实验结果表明,该方法在ConceptMix(k=7)上,所有正确率提高了16.9%;在T2I-CompBench(3D-Spatial类别)上提高了13.8%;与计算量匹配的并行采样相比,在Visual Jenga场景分解上提高了12.5%。此外,人类评估者在58.7%的时间内更喜欢该方法生成的图像,表明该方法在生成质量和组合性方面均优于现有方法。
🎯 应用场景
该研究成果可应用于各种需要高质量、高精度图像生成的领域,例如:艺术创作、产品设计、虚拟现实、游戏开发等。通过迭代优化,可以生成更符合用户需求的图像,提高用户体验和创作效率。未来,该方法有望进一步扩展到视频生成、3D模型生成等领域。
📄 摘要(原文)
Text-to-image (T2I) models have achieved remarkable progress, yet they continue to struggle with complex prompts that require simultaneously handling multiple objects, relations, and attributes. Existing inference-time strategies, such as parallel sampling with verifiers or simply increasing denoising steps, can improve prompt alignment but remain inadequate for richly compositional settings where many constraints must be satisfied. Inspired by the success of chain-of-thought reasoning in large language models, we propose an iterative test-time strategy in which a T2I model progressively refines its generations across multiple steps, guided by feedback from a vision-language model as the critic in the loop. Our approach is simple, requires no external tools or priors, and can be flexibly applied to a wide range of image generators and vision-language models. Empirically, we demonstrate consistent gains on image generation across benchmarks: a 16.9% improvement in all-correct rate on ConceptMix (k=7), a 13.8% improvement on T2I-CompBench (3D-Spatial category) and a 12.5% improvement on Visual Jenga scene decomposition compared to compute-matched parallel sampling. Beyond quantitative gains, iterative refinement produces more faithful generations by decomposing complex prompts into sequential corrections, with human evaluators preferring our method 58.7% of the time over 41.3% for the parallel baseline. Together, these findings highlight iterative self-correction as a broadly applicable principle for compositional image generation. Results and visualizations are available at https://iterative-img-gen.github.io/