Walk through Paintings: Egocentric World Models from Internet Priors
作者: Anurag Bagchi, Zhipeng Bao, Homanga Bharadhwaj, Yu-Xiong Wang, Pavel Tokmakov, Martial Hebert
分类: cs.CV
发布日期: 2026-01-21
💡 一句话要点
提出EgoWM,利用互联网视频先验知识构建可控的自中心世界模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction) 支柱七:动作重定向 (Motion Retargeting)
关键词: 世界模型 视频扩散模型 自中心视觉 机器人导航 动作条件生成
📋 核心要点
- 现有世界模型难以准确预测动作对环境的影响,尤其是在复杂环境中。
- EgoWM通过轻量级条件反射层将动作指令注入预训练的视频扩散模型,利用其丰富的世界先验知识。
- 实验表明,EgoWM在结构一致性评分上显著优于现有方法,并具有更低的推理延迟和更好的泛化能力。
📝 摘要(中文)
本文提出了一种名为自中心世界模型(EgoWM)的简单且架构无关的方法,该方法可以将任何预训练的视频扩散模型转换为动作条件的世界模型,从而实现可控的未来预测。EgoWM并非从头开始训练,而是重新利用互联网规模视频模型中丰富的世界先验知识,并通过轻量级的条件反射层注入运动指令。这使得模型能够忠实地遵循动作,同时保持真实感和强大的泛化能力。该方法可以自然地扩展到不同的机器人形态和动作空间,从3自由度的移动机器人到25自由度的人形机器人。EgoWM为导航和操作任务生成连贯的轨迹,只需要适度的微调。为了独立于视觉外观评估物理正确性,本文引入了结构一致性评分(SCS),用于衡量稳定的场景元素是否与提供的动作一致地演变。EgoWM在SCS上比先前的最先进的导航世界模型提高了高达80%,同时实现了高达六倍的更低推理延迟,并对未见环境(包括绘画内部的导航)具有强大的泛化能力。
🔬 方法详解
问题定义:现有的世界模型在预测未来时,尤其是在复杂的自中心视角下,难以准确反映动作对环境的改变。它们通常需要从头开始训练,计算成本高昂,并且泛化能力有限。尤其是在高自由度机器人上,预测关节角度驱动的动态变化更具挑战性。
核心思路:EgoWM的核心思路是利用大规模互联网视频数据训练的视频扩散模型所蕴含的丰富世界先验知识。通过将动作指令以一种轻量级的方式注入到这些预训练模型中,使其能够根据给定的动作预测未来的场景变化,而无需从头开始训练。这样既能保证预测的真实感和泛化能力,又能提高训练效率。
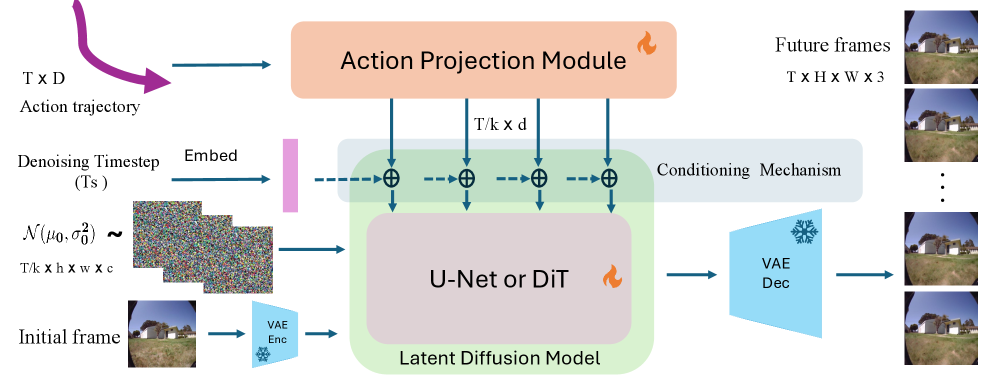
技术框架:EgoWM的整体框架包括一个预训练的视频扩散模型和一个轻量级的条件反射模块。首先,使用大规模视频数据集预训练一个视频扩散模型,使其具备生成逼真视频的能力。然后,设计一个条件反射模块,将动作指令(例如,机器人的关节角度或移动指令)作为输入,并将其嵌入到视频扩散模型的潜在空间中。最后,通过微调整个模型,使其能够根据给定的动作指令生成相应的未来视频。
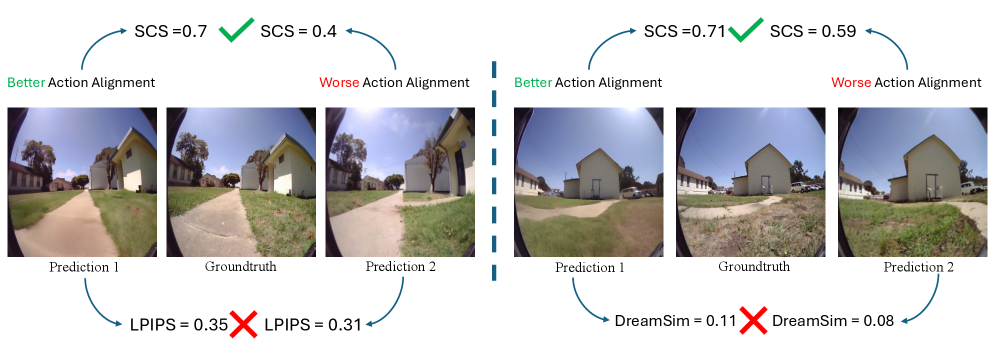
关键创新:EgoWM的关键创新在于它能够将预训练的视频扩散模型转化为动作条件的世界模型,而无需从头开始训练。这种方法充分利用了互联网规模视频数据中蕴含的丰富世界先验知识,从而提高了模型的泛化能力和训练效率。此外,本文还提出了结构一致性评分(SCS)来评估预测的物理正确性,这是一种独立于视觉外观的评估指标。
关键设计:EgoWM的关键设计包括:1) 轻量级的条件反射模块,该模块能够有效地将动作指令嵌入到视频扩散模型的潜在空间中,同时避免破坏预训练模型的先验知识。2) 结构一致性评分(SCS),该评分能够量化预测的物理正确性,并作为训练过程中的一个重要指标。3) 针对不同机器人形态和动作空间的自适应设计,使得EgoWM能够应用于各种不同的任务。
🖼️ 关键图片

📊 实验亮点
EgoWM在结构一致性评分(SCS)上比先前的最先进的导航世界模型提高了高达80%,同时实现了高达六倍的更低推理延迟。此外,EgoWM还展现了强大的泛化能力,能够成功地在未见过的环境中进行导航,甚至包括在绘画内部进行导航。这些实验结果表明,EgoWM是一种高效且通用的世界模型。
🎯 应用场景
EgoWM具有广泛的应用前景,例如机器人导航、操作、游戏AI和虚拟现实。它可以帮助机器人更好地理解环境,并根据自身的动作预测未来的场景变化,从而做出更明智的决策。在游戏AI和虚拟现实中,EgoWM可以生成更逼真和可控的虚拟环境,提升用户体验。此外,该技术还可以应用于自动驾驶领域,帮助车辆预测周围环境的变化,提高安全性。
📄 摘要(原文)
What if a video generation model could not only imagine a plausible future, but the correct one, accurately reflecting how the world changes with each action? We address this question by presenting the Egocentric World Model (EgoWM), a simple, architecture-agnostic method that transforms any pretrained video diffusion model into an action-conditioned world model, enabling controllable future prediction. Rather than training from scratch, we repurpose the rich world priors of Internet-scale video models and inject motor commands through lightweight conditioning layers. This allows the model to follow actions faithfully while preserving realism and strong generalization. Our approach scales naturally across embodiments and action spaces, ranging from 3-DoF mobile robots to 25-DoF humanoids, where predicting egocentric joint-angle-driven dynamics is substantially more challenging. The model produces coherent rollouts for both navigation and manipulation tasks, requiring only modest fine-tuning. To evaluate physical correctness independently of visual appearance, we introduce the Structural Consistency Score (SCS), which measures whether stable scene elements evolve consistently with the provided actions. EgoWM improves SCS by up to 80 percent over prior state-of-the-art navigation world models, while achieving up to six times lower inference latency and robust generalization to unseen environments, including navigation inside paintings.