RayRoPE: Projective Ray Positional Encoding for Multi-view Attention
作者: Yu Wu, Minsik Jeon, Jen-Hao Rick Chang, Oncel Tuzel, Shubham Tulsiani
分类: cs.CV, cs.LG
发布日期: 2026-01-21
备注: Project page: https://rayrope.github.io/
💡 一句话要点
RayRoPE:用于多视角注意力机制的射影光线位置编码,提升新视角合成与深度估计。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 多视角学习 位置编码 Transformer 新视角合成 深度估计
📋 核心要点
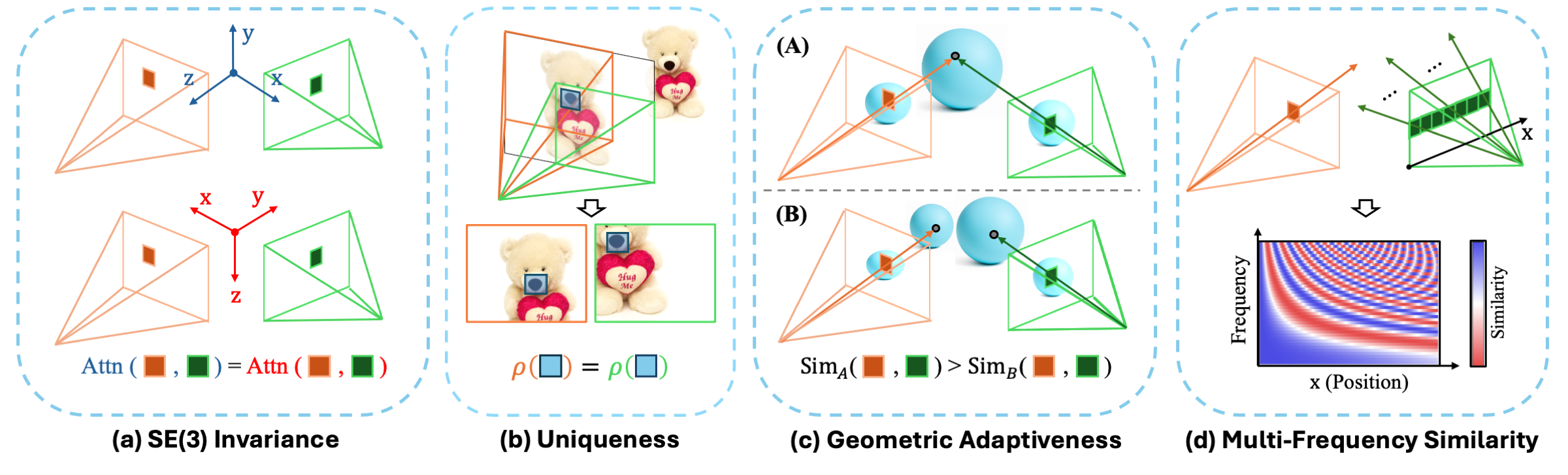
- 现有方法在多视角Transformer中,难以同时满足唯一编码patch、SE(3)不变注意力和适应场景几何结构的需求。
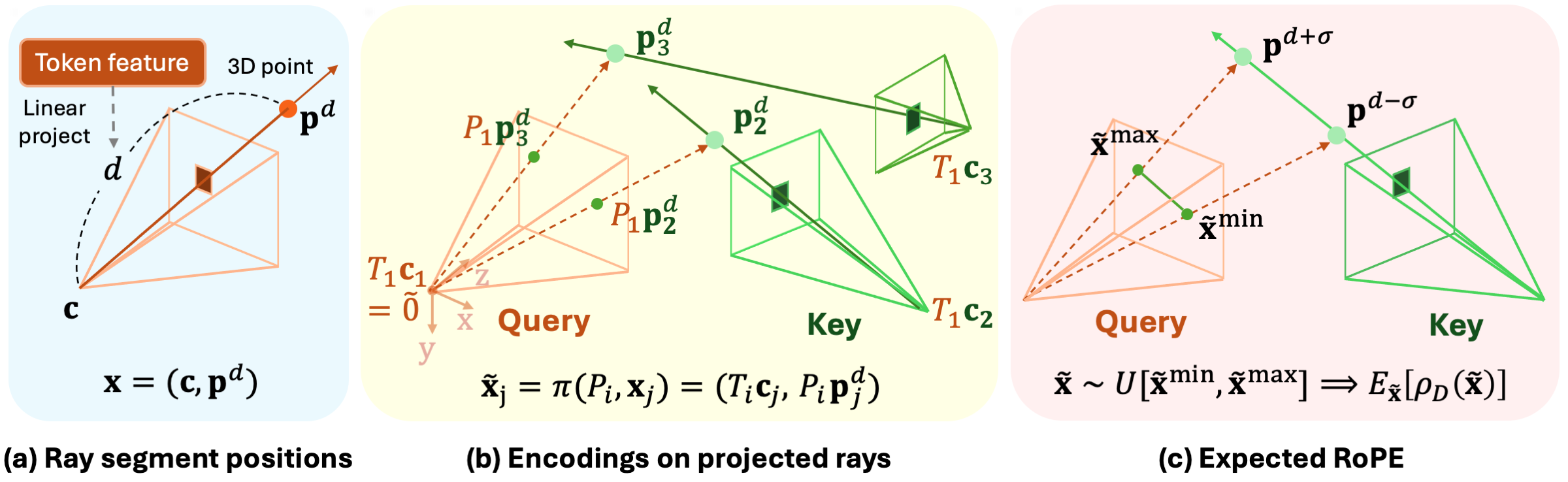
- RayRoPE通过预测光线上一点进行几何感知编码,并计算查询帧的射影坐标实现SE(3)不变性,解决上述问题。
- 实验表明,RayRoPE在CO3D数据集上,新视角合成的LPIPS指标相对提升15%,且能有效利用RGB-D信息。
📝 摘要(中文)
本文研究了多视角Transformer中的位置编码问题,该Transformer处理来自一组带有位姿信息的输入图像的tokens。目标是寻找一种能够唯一编码patches,实现具有多频率相似性的SE(3)不变注意力,并且能够适应底层场景几何结构的机制。研究发现,现有的多视角注意力编码方案(绝对或相对)无法满足上述需求,因此提出了RayRoPE来解决这个问题。RayRoPE基于相关的光线表示patch的位置,但利用光线上预测的点而不是方向来进行几何感知的编码。为了实现SE(3)不变性,RayRoPE计算查询帧的射影坐标以计算多频率相似性。最后,由于光线上“预测”的3D点可能不精确,RayRoPE提出了一种在不确定性下分析计算预期位置编码的机制。在 novel-view synthesis 和立体深度估计任务上验证了RayRoPE,结果表明它始终优于其他位置编码方案(例如,在CO3D上LPIPS相对提高了15%)。RayRoPE还可以无缝地结合RGB-D输入,从而获得比无法对该信息进行位置编码的替代方案更大的收益。
🔬 方法详解
问题定义:多视角Transformer需要有效的位置编码来处理来自不同视角的图像patches。现有的位置编码方法,如绝对位置编码和相对位置编码,在多视角场景下存在不足。绝对位置编码无法保证视角不变性,而简单的相对位置编码可能无法充分利用场景的几何信息,导致注意力机制无法准确捕捉patches之间的关系。此外,如何有效地融合RGB-D信息也是一个挑战。
核心思路:RayRoPE的核心思想是利用射影几何和光线信息来表示patches的位置,并设计一种SE(3)不变的位置编码。通过预测每条光线上的一个3D点,RayRoPE能够更好地感知场景的几何结构。同时,通过计算查询帧的射影坐标,RayRoPE实现了SE(3)不变性,使得注意力机制能够关注到不同视角下的相同场景区域。此外,RayRoPE还考虑了预测3D点的不确定性,并提出了一种分析计算预期位置编码的机制。
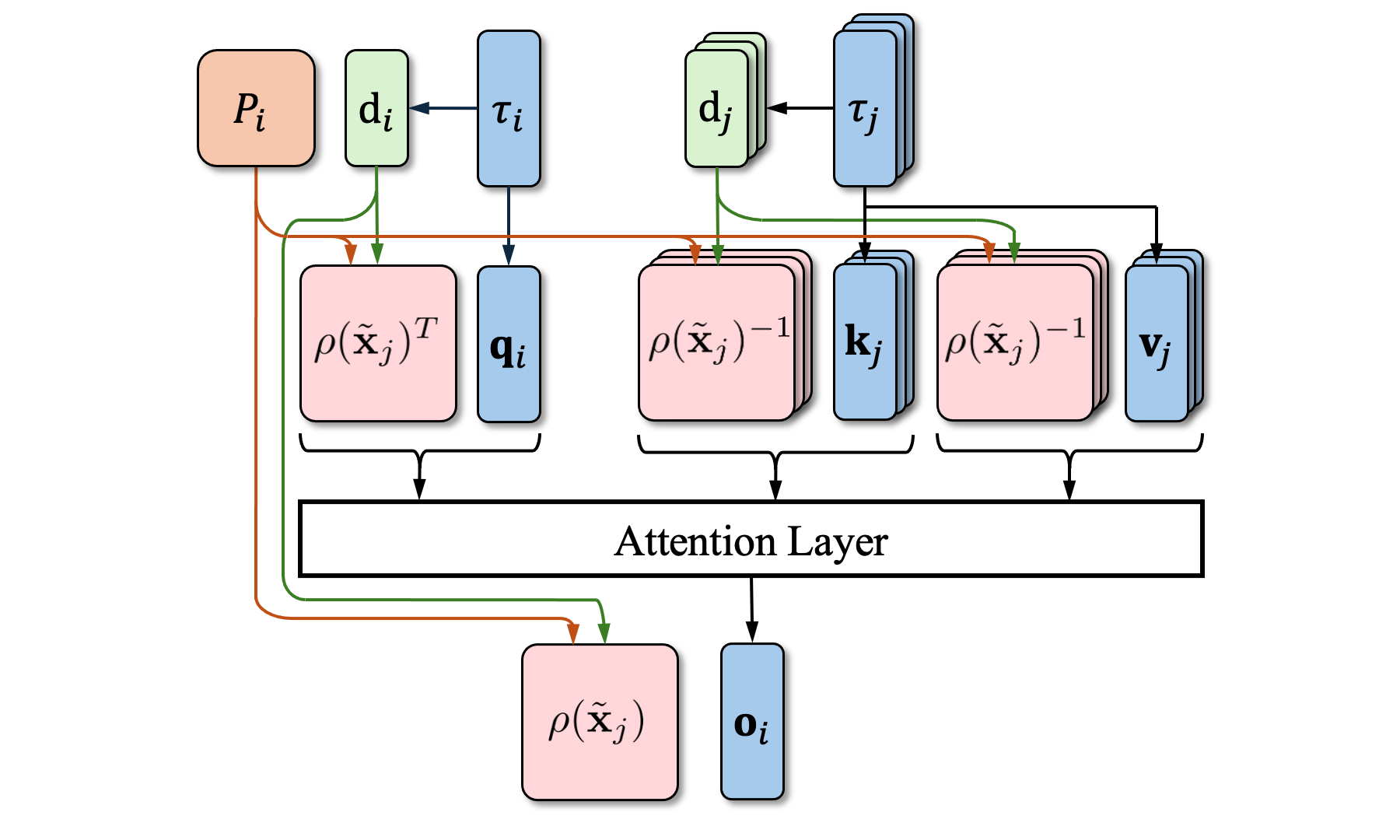
技术框架:RayRoPE主要包含以下几个模块:1) 光线生成模块:根据相机位姿和图像patches生成对应的光线。2) 3D点预测模块:预测每条光线上的一个3D点,用于表示patch的位置。3) 射影坐标计算模块:将预测的3D点投影到查询帧的图像平面上,得到射影坐标。4) 多频率相似性计算模块:利用射影坐标计算多频率相似性,作为注意力机制的输入。5) 不确定性处理模块:考虑预测3D点的不确定性,分析计算预期位置编码。整体流程是,首先对输入图像提取patches,然后通过光线生成模块和3D点预测模块得到patches对应的3D位置信息,接着通过射影坐标计算模块和多频率相似性计算模块得到SE(3)不变的注意力权重,最后利用注意力机制进行特征融合。
关键创新:RayRoPE的关键创新在于:1) 提出了一种基于射影几何和光线信息的几何感知位置编码方法,能够更好地适应多视角场景的几何结构。2) 设计了一种SE(3)不变的位置编码,使得注意力机制能够关注到不同视角下的相同场景区域。3) 提出了一种分析计算预期位置编码的机制,能够有效处理预测3D点的不确定性。
关键设计:RayRoPE的关键设计包括:1) 3D点预测模块的网络结构,可以使用MLP或者其他3D回归网络。2) 多频率相似性计算模块中频率的选择,需要根据具体场景进行调整。3) 不确定性处理模块中不确定性模型的选择,可以使用高斯分布或者其他概率分布。4) 损失函数的设计,可以包括3D点预测的回归损失和新视角合成的重建损失。
🖼️ 关键图片
📊 实验亮点
RayRoPE在CO3D数据集上的新视角合成任务中,LPIPS指标相对提升了15%,显著优于其他位置编码方法。此外,RayRoPE能够无缝地结合RGB-D输入,进一步提升性能。实验结果表明,RayRoPE是一种有效且通用的多视角位置编码方法。
🎯 应用场景
RayRoPE在三维重建、自动驾驶、机器人导航等领域具有广泛的应用前景。它可以用于提升多视角图像处理任务的性能,例如新视角合成、深度估计、三维目标检测等。通过更准确地理解场景的几何结构和视角关系,RayRoPE可以帮助机器人更好地感知周围环境,从而实现更安全、更高效的导航。
📄 摘要(原文)
We study positional encodings for multi-view transformers that process tokens from a set of posed input images, and seek a mechanism that encodes patches uniquely, allows SE(3)-invariant attention with multi-frequency similarity, and can be adaptive to the geometry of the underlying scene. We find that prior (absolute or relative) encoding schemes for multi-view attention do not meet the above desiderata, and present RayRoPE to address this gap. RayRoPE represents patch positions based on associated rays but leverages a predicted point along the ray instead of the direction for a geometry-aware encoding. To achieve SE(3) invariance, RayRoPE computes query-frame projective coordinates for computing multi-frequency similarity. Lastly, as the 'predicted' 3D point along a ray may not be precise, RayRoPE presents a mechanism to analytically compute the expected position encoding under uncertainty. We validate RayRoPE on the tasks of novel-view synthesis and stereo depth estimation and show that it consistently improves over alternate position encoding schemes (e.g. 15% relative improvement on LPIPS in CO3D). We also show that RayRoPE can seamlessly incorporate RGB-D input, resulting in even larger gains over alternatives that cannot positionally encode this information.