FlowSSC: Universal Generative Monocular Semantic Scene Completion via One-Step Latent Diffusion
作者: Zichen Xi, Hao-Xiang Chen, Nan Xue, Hongyu Yan, Qi-Yuan Feng, Levent Burak Kara, Joaquim Jorge, Qun-Ce Xu
分类: cs.CV, cs.RO
发布日期: 2026-01-21
备注: Under Review
💡 一句话要点
FlowSSC:基于单步潜在扩散的通用生成式单目语义场景补全
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting)
关键词: 语义场景补全 单目视觉 生成模型 扩散模型 Flow-matching 三平面表示 自动驾驶
📋 核心要点
- 单目语义场景补全任务面临遮挡区域细节生成困难和空间关系保持不足的挑战。
- FlowSSC将场景补全视为条件生成问题,利用潜在空间单步扩散模型提升性能。
- 实验表明,FlowSSC在SemanticKITTI数据集上显著优于现有方法,达到SOTA水平。
📝 摘要(中文)
本文提出FlowSSC,首个直接应用于单目语义场景补全的生成式框架。单目RGB图像的语义场景补全(SSC)是一项基础但具有挑战性的任务,因为从单个视图推断被遮挡的3D几何体具有固有的模糊性。虽然前馈方法取得了一些进展,但它们通常难以在被遮挡区域生成合理的细节,并保持物体基本空间关系。这种对整个3D空间进行精确生成推理的能力在实际应用中至关重要。FlowSSC将SSC任务视为条件生成问题,并能与现有的前馈SSC方法无缝集成,从而显著提高它们的性能。为了在不影响质量的前提下实现实时推理,我们引入了在紧凑三平面潜在空间中运行的Shortcut Flow-matching。与需要数百步的标准扩散模型不同,我们的方法利用快捷机制在单步中实现高保真生成,从而能够在自动驾驶系统中实际部署。在SemanticKITTI上的大量实验表明,FlowSSC实现了最先进的性能,显著优于现有的基线。
🔬 方法详解
问题定义:单目语义场景补全(SSC)旨在从单张RGB图像中推断出完整的3D场景几何和语义信息,尤其是在被遮挡区域。现有前馈方法难以生成被遮挡区域的精细细节,并且难以保持场景中物体之间的空间关系,限制了其在实际场景中的应用。
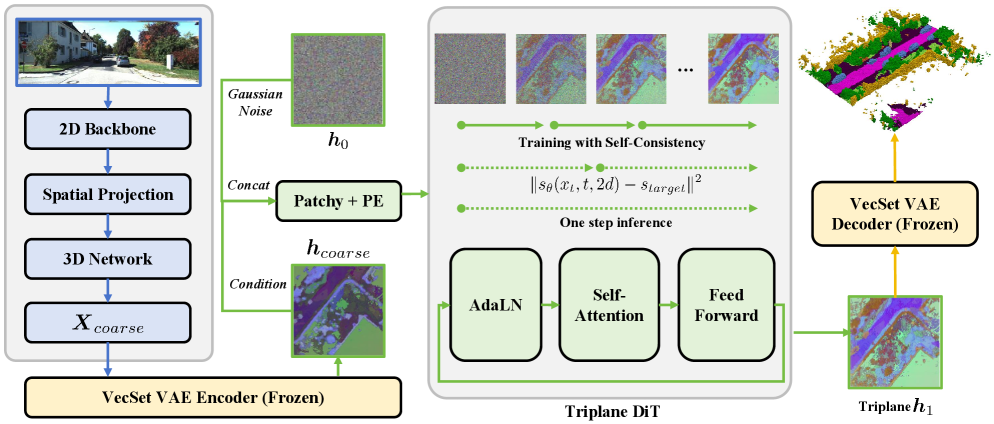
核心思路:FlowSSC的核心思路是将SSC任务建模为一个条件生成问题,利用生成模型强大的先验知识来补全被遮挡区域的信息。通过将前馈SSC方法的输出作为条件,FlowSSC可以生成更逼真、空间关系更合理的补全结果。
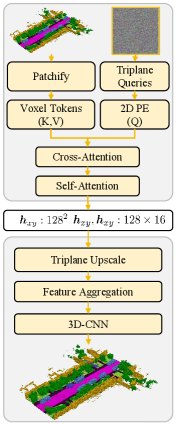
技术框架:FlowSSC框架主要包含两个阶段:首先,使用现有的前馈SSC方法生成初始的场景补全结果;然后,将该结果作为条件输入到基于Shortcut Flow-matching的生成模型中,生成最终的补全结果。Shortcut Flow-matching在紧凑的三平面潜在空间中运行,以提高生成效率。
关键创新:FlowSSC的关键创新在于将生成模型引入到单目语义场景补全任务中,并提出了Shortcut Flow-matching方法。与传统的扩散模型需要多步迭代不同,Shortcut Flow-matching通过快捷机制在单步内实现高保真生成,大大提高了推理速度,使其能够应用于实时场景。
关键设计:FlowSSC使用三平面潜在空间来表示3D场景,这是一种紧凑且高效的表示方法。Shortcut Flow-matching通过学习一个从噪声到数据的直接映射,避免了传统扩散模型的多步迭代过程。损失函数的设计旨在保证生成结果的真实性和与输入图像的一致性。具体而言,使用了对抗损失、感知损失和语义一致性损失等。
🖼️ 关键图片
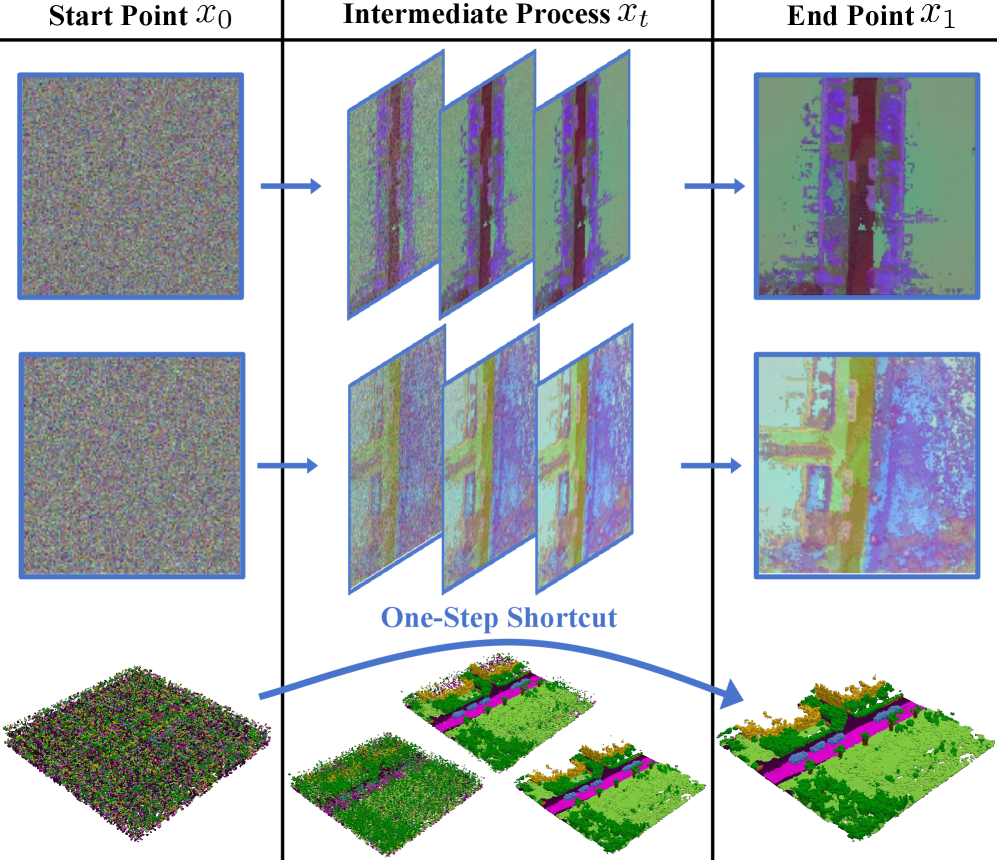
📊 实验亮点
FlowSSC在SemanticKITTI数据集上取得了显著的性能提升,超越了现有的SOTA方法。实验结果表明,FlowSSC能够生成更逼真、细节更丰富的场景补全结果,尤其是在被遮挡区域。与传统扩散模型相比,FlowSSC的推理速度更快,更适合实时应用。具体提升幅度未知,但原文强调了“significantly outperforming existing baselines”。
🎯 应用场景
FlowSSC在自动驾驶、机器人导航、虚拟现实和增强现实等领域具有广泛的应用前景。它可以帮助自动驾驶系统更好地理解周围环境,提高导航的准确性和安全性。在机器人领域,它可以用于场景理解和物体识别,从而实现更智能的交互。在VR/AR领域,它可以用于生成更逼真的3D场景,提升用户体验。
📄 摘要(原文)
Semantic Scene Completion (SSC) from monocular RGB images is a fundamental yet challenging task due to the inherent ambiguity of inferring occluded 3D geometry from a single view. While feed-forward methods have made progress, they often struggle to generate plausible details in occluded regions and preserve the fundamental spatial relationships of objects. Such accurate generative reasoning capability for the entire 3D space is critical in real-world applications. In this paper, we present FlowSSC, the first generative framework applied directly to monocular semantic scene completion. FlowSSC treats the SSC task as a conditional generation problem and can seamlessly integrate with existing feed-forward SSC methods to significantly boost their performance. To achieve real-time inference without compromising quality, we introduce Shortcut Flow-matching that operates in a compact triplane latent space. Unlike standard diffusion models that require hundreds of steps, our method utilizes a shortcut mechanism to achieve high-fidelity generation in a single step, enabling practical deployment in autonomous systems. Extensive experiments on SemanticKITTI demonstrate that FlowSSC achieves state-of-the-art performance, significantly outperforming existing baselines.