ScenDi: 3D-to-2D Scene Diffusion Cascades for Urban Generation
作者: Hanlei Guo, Jiahao Shao, Xinya Chen, Xiyang Tan, Sheng Miao, Yujun Shen, Yiyi Liao
分类: cs.CV
发布日期: 2026-01-21
💡 一句话要点
ScenDi:结合3D和2D扩散模型的城市场景生成方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 城市场景生成 3D扩散模型 2D扩散模型 条件生成 3D高斯分布
📋 核心要点
- 现有方法在生成逼真的3D城市场景时面临挑战,单纯依赖3D扩散模型会导致外观细节退化。
- ScenDi通过结合3D和2D扩散模型,利用3D模型提供场景结构,2D模型增强细节,实现可控的城市场景生成。
- 实验表明,ScenDi在Waymo和KITTI-360数据集上表现出色,验证了其在真实场景生成方面的有效性。
📝 摘要(中文)
本文提出了一种名为ScenDi的城市场景生成方法,该方法集成了3D和2D扩散模型。首先,训练一个3D潜在扩散模型来生成3D高斯分布,从而能够以相对较低的分辨率渲染图像。为了实现可控合成,可以通过指定3D边界框、道路地图或文本提示等输入来有条件地进行3DGS生成。然后,训练一个2D视频扩散模型,以3D高斯渲染图像为条件,增强外观细节。通过利用粗糙的3D场景作为2D视频扩散的指导,ScenDi能够根据输入条件生成所需的场景,并成功地遵循精确的相机轨迹。在Waymo和KITTI-360两个具有挑战性的真实世界数据集上的实验证明了该方法的有效性。
🔬 方法详解
问题定义:现有3D城市场景生成方法存在局限性。单独使用3D扩散模型难以生成精细的外观细节,而仅使用2D扩散模型则缺乏相机控制能力,难以保证场景的一致性和可控性。因此,需要一种能够兼顾场景结构、外观细节和相机控制的生成方法。
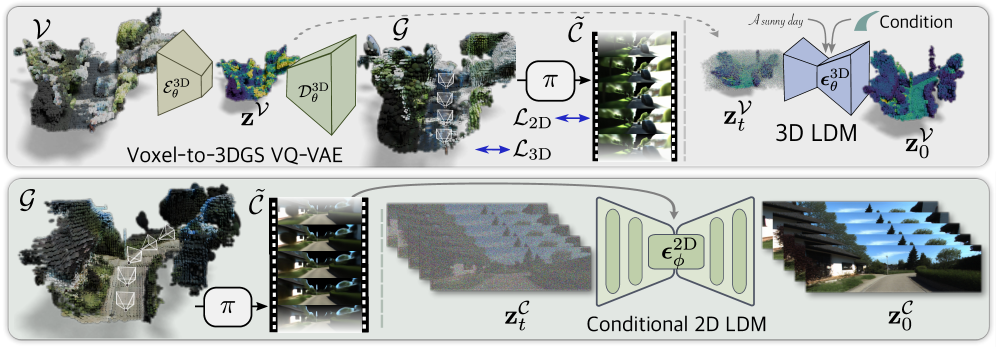
核心思路:ScenDi的核心思路是将3D和2D扩散模型结合起来,形成一个级联的生成流程。首先,使用3D扩散模型生成粗糙的3D场景结构,然后利用2D扩散模型在3D场景的引导下增强外观细节。这种方法既能保证场景的整体结构,又能生成逼真的细节,同时还能通过控制3D场景的生成过程来实现相机控制。
技术框架:ScenDi包含两个主要阶段:3D场景生成和2D细节增强。在3D场景生成阶段,使用3D潜在扩散模型生成3D高斯分布(3DGS),并渲染成低分辨率图像。该阶段可以接受3D边界框、道路地图或文本提示等条件输入,实现可控生成。在2D细节增强阶段,使用2D视频扩散模型,以3DGS渲染的图像为条件,生成高分辨率、细节丰富的图像序列。
关键创新:ScenDi的关键创新在于将3D和2D扩散模型以级联的方式结合起来,利用3D模型提供场景结构,2D模型增强细节。这种方法克服了单独使用3D或2D扩散模型的局限性,实现了高质量、可控的城市场景生成。此外,使用3D高斯分布作为3D场景的表示形式,方便渲染和与2D扩散模型进行交互。
关键设计:3D潜在扩散模型采用标准的扩散模型结构,损失函数为L2损失。2D视频扩散模型采用U-Net结构,以3DGS渲染图像作为条件输入。在训练过程中,分别训练3D和2D扩散模型,然后将它们组合起来进行推理。具体参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
ScenDi在Waymo和KITTI-360数据集上进行了实验,结果表明该方法能够生成高质量、细节丰富的城市场景。与现有方法相比,ScenDi在外观细节和相机控制方面都有显著提升。具体的性能数据和提升幅度未在摘要中给出,属于未知信息。
🎯 应用场景
ScenDi在城市规划、游戏开发、自动驾驶模拟等领域具有广泛的应用前景。它可以用于生成逼真的城市环境,为城市规划提供可视化工具,为游戏开发提供丰富的场景资源,为自动驾驶系统提供训练数据和测试环境。未来,ScenDi有望成为城市数字孪生和虚拟现实的重要组成部分。
📄 摘要(原文)
Recent advancements in 3D object generation using diffusion models have achieved remarkable success, but generating realistic 3D urban scenes remains challenging. Existing methods relying solely on 3D diffusion models tend to suffer a degradation in appearance details, while those utilizing only 2D diffusion models typically compromise camera controllability. To overcome this limitation, we propose ScenDi, a method for urban scene generation that integrates both 3D and 2D diffusion models. We first train a 3D latent diffusion model to generate 3D Gaussians, enabling the rendering of images at a relatively low resolution. To enable controllable synthesis, this 3DGS generation process can be optionally conditioned by specifying inputs such as 3d bounding boxes, road maps, or text prompts. Then, we train a 2D video diffusion model to enhance appearance details conditioned on rendered images from the 3D Gaussians. By leveraging the coarse 3D scene as guidance for 2D video diffusion, ScenDi generates desired scenes based on input conditions and successfully adheres to accurate camera trajectories. Experiments on two challenging real-world datasets, Waymo and KITTI-360, demonstrate the effectiveness of our approach.