Deep Leakage with Generative Flow Matching Denoiser
作者: Isaac Baglin, Xiatian Zhu, Simon Hadfield
分类: cs.CV
发布日期: 2026-01-21
💡 一句话要点
提出基于生成流匹配去噪器的深度泄露攻击,提升联邦学习隐私破解效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 深度泄露攻击 生成模型 流匹配 隐私保护
📋 核心要点
- 联邦学习面临深度泄露攻击的威胁,现有攻击方法在保真度、稳定性和鲁棒性方面存在不足。
- 该论文提出了一种新的深度泄露攻击方法,利用生成流匹配模型作为先验知识,提升数据重建的质量。
- 实验表明,该方法在多种数据集和防御策略下,均优于现有攻击方法,表明其有效性和鲁棒性。
📝 摘要(中文)
联邦学习(FL)作为一种去中心化模型训练的强大范例,但仍容易受到深度泄露(DL)攻击的影响,攻击者可以从共享的模型更新中重建私有客户端数据。虽然先前的DL方法已经展示了不同程度的成功,但它们通常存在不稳定性、有限的保真度或在实际FL设置下鲁棒性较差的问题。我们提出了一种新的DL攻击,它将生成流匹配(FM)先验集成到重建过程中。通过将优化引导到真实图像的分布(由流匹配基础模型表示),我们的方法提高了重建保真度,而无需了解私有数据。在多个数据集和目标模型上的大量实验表明,我们的方法在像素级、感知和基于特征的相似性指标上始终优于最先进的攻击。至关重要的是,该方法在不同的训练epoch、更大的客户端批量大小以及常见的防御措施(如噪声注入、裁剪和稀疏化)下仍然有效。我们的发现呼吁开发新的防御策略,明确考虑配备强大生成先验的攻击者。
🔬 方法详解
问题定义:联邦学习中的深度泄露攻击旨在从共享的模型更新中恢复客户端的私有数据。现有的深度泄露攻击方法通常依赖于直接优化像素空间,容易陷入局部最优,导致重建图像质量差,且对噪声、裁剪等防御手段的鲁棒性不足。这些方法往往需要大量的迭代和精细的参数调整才能获得较好的结果,泛化能力有限。
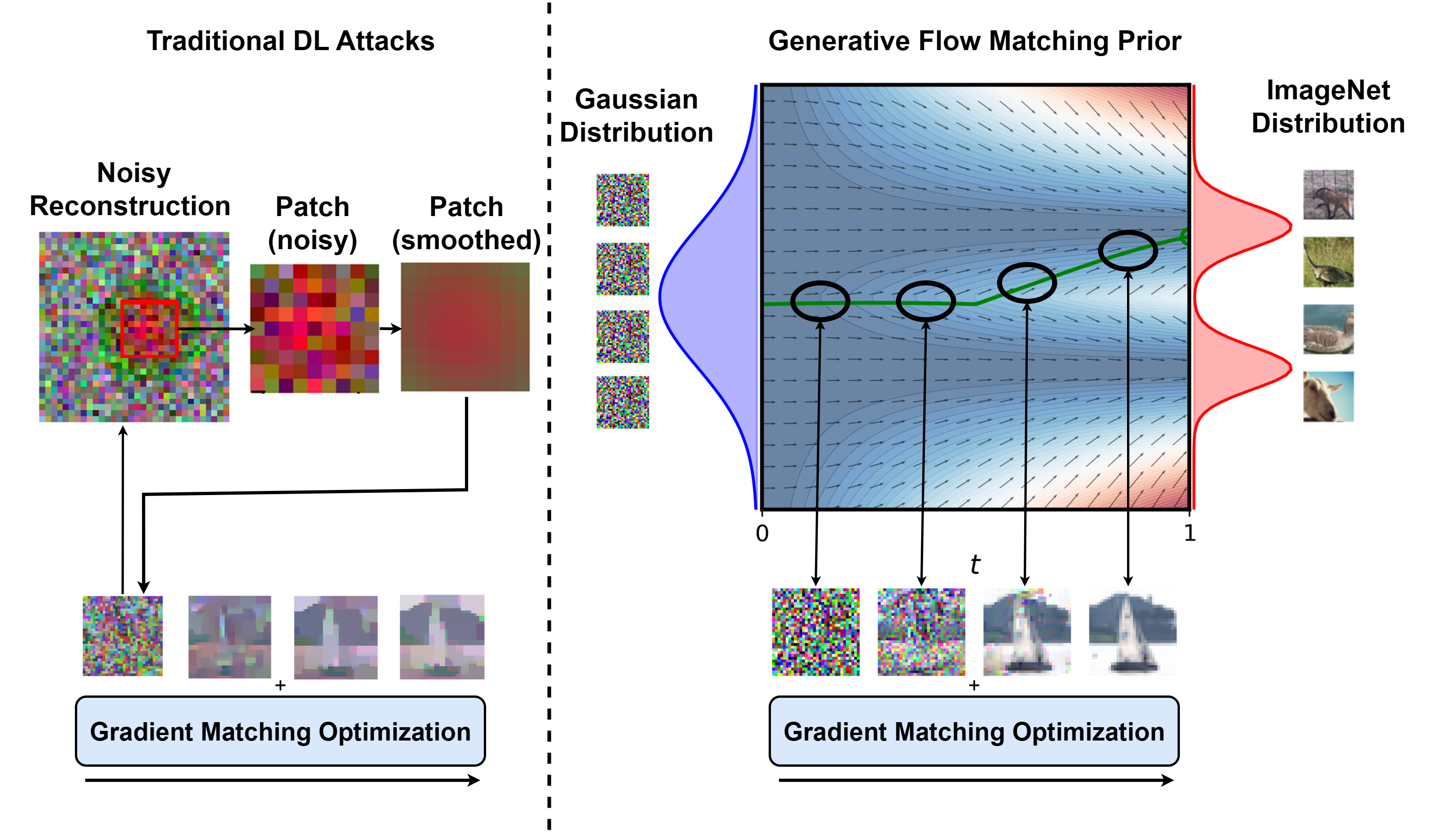
核心思路:该论文的核心思路是将生成模型(具体而言是Flow Matching模型)作为先验知识引入到深度泄露攻击中。通过将重建过程约束在生成模型的潜在空间中,可以有效地提高重建图像的真实性和保真度,同时增强对各种防御手段的鲁棒性。Flow Matching模型能够学习到真实图像的分布,从而引导重建过程朝着更合理的方向进行。
技术框架:该攻击框架主要包含两个部分:目标模型(联邦学习训练的模型)和攻击模型。攻击模型的目标是根据目标模型泄露的信息(例如梯度)重建出原始数据。攻击模型利用Flow Matching模型作为生成先验,在优化过程中,不仅要最小化重建图像与泄露信息之间的差异,还要确保重建图像位于Flow Matching模型学习到的真实图像分布附近。整体流程可以概括为:1)获取目标模型泄露的信息;2)初始化重建图像;3)迭代优化重建图像,优化目标包括数据一致性损失和生成先验损失;4)输出重建图像。
关键创新:该论文的关键创新在于将生成流匹配模型引入到深度泄露攻击中,作为一种强大的先验知识。与传统的基于像素空间优化的方法相比,该方法能够更好地利用图像的结构信息,提高重建图像的质量和鲁棒性。此外,该方法不需要关于私有数据的任何先验知识,具有更强的通用性。
关键设计:关键设计包括:1)选择合适的Flow Matching模型作为生成先验,该模型需要能够有效地捕捉到目标数据集的图像分布;2)设计合适的损失函数,平衡数据一致性损失和生成先验损失,确保重建图像既能够与泄露的信息一致,又能够保持真实性;3)采用合适的优化算法,例如Adam,加速收敛并避免陷入局部最优。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在多个数据集(如MNIST、CIFAR-10)和目标模型上,均显著优于现有的深度泄露攻击方法。在像素级相似度、感知相似度和特征相似度等指标上,该方法均取得了更好的结果。此外,该方法在不同的训练epoch、更大的客户端批量大小以及常见的防御措施(如噪声注入、裁剪和稀疏化)下仍然有效,表明其具有很强的鲁棒性。
🎯 应用场景
该研究成果可用于评估和改进联邦学习系统的安全性,帮助开发者更好地理解深度泄露攻击的威胁,并设计更有效的防御机制。此外,该方法也可应用于其他需要从有限信息中重建数据的场景,例如图像修复、超分辨率等。未来的研究可以探索更高效的生成模型和更鲁棒的优化算法,进一步提升深度泄露攻击的性能。
📄 摘要(原文)
Federated Learning (FL) has emerged as a powerful paradigm for decentralized model training, yet it remains vulnerable to deep leakage (DL) attacks that reconstruct private client data from shared model updates. While prior DL methods have demonstrated varying levels of success, they often suffer from instability, limited fidelity, or poor robustness under realistic FL settings. We introduce a new DL attack that integrates a generative Flow Matching (FM) prior into the reconstruction process. By guiding optimization toward the distribution of realistic images (represented by a flow matching foundation model), our method enhances reconstruction fidelity without requiring knowledge of the private data. Extensive experiments on multiple datasets and target models demonstrate that our approach consistently outperforms state-of-the-art attacks across pixel-level, perceptual, and feature-based similarity metrics. Crucially, the method remains effective across different training epochs, larger client batch sizes, and under common defenses such as noise injection, clipping, and sparsification. Our findings call for the development of new defense strategies that explicitly account for adversaries equipped with powerful generative priors.