SpatialMem: Unified 3D Memory with Metric Anchoring and Fast Retrieval
作者: Xinyi Zheng, Yunze Liu, Chi-Hao Wu, Fan Zhang, Hao Zheng, Wenqi Zhou, Walterio W. Mayol-Cuevas, Junxiao Shen
分类: cs.CV, cs.AI
发布日期: 2026-01-21
💡 一句话要点
SpatialMem:提出一种统一的3D记忆系统,用于度量锚定和快速检索。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 3D重建 语义SLAM 具身智能 空间记忆 语言引导导航
📋 核心要点
- 现有方法在融合3D几何、语义和语言信息方面存在挑战,限制了具身智能体对环境的理解和交互能力。
- SpatialMem通过构建统一的3D记忆系统,将3D几何、语义和语言信息整合到可查询的表示中,实现空间关系的推理。
- 实验表明,SpatialMem在真实室内场景中,即使存在杂乱和遮挡,也能保持较高的导航完成度和检索精度。
📝 摘要(中文)
SpatialMem是一个以记忆为中心的系统,它将3D几何、语义和语言统一到一个可查询的表示中。该系统从随意拍摄的以自我为中心的RGB视频开始,重建具有度量尺度的室内环境,检测结构化的3D锚点(墙壁、门、窗)作为第一层支架,并用开放词汇的对象节点填充分层记忆——将证据块、视觉嵌入和两层文本描述链接到3D坐标——以实现紧凑的存储和快速检索。这种设计能够对空间关系(例如,距离、方向、可见性)进行可解释的推理,并支持下游任务,如语言引导的导航和对象检索,而无需专门的传感器。在三个真实室内场景中的实验表明,SpatialMem在增加的杂乱和遮挡下,保持了强大的锚点-描述级别导航完成度和分层检索精度,为具身空间智能提供了一个高效和可扩展的框架。
🔬 方法详解
问题定义:现有方法难以将3D几何、语义和语言信息有效地整合,导致具身智能体在复杂室内环境中难以进行有效的导航和对象检索。现有方法通常依赖于特定传感器或预定义的词汇表,限制了其泛化能力和适应性。
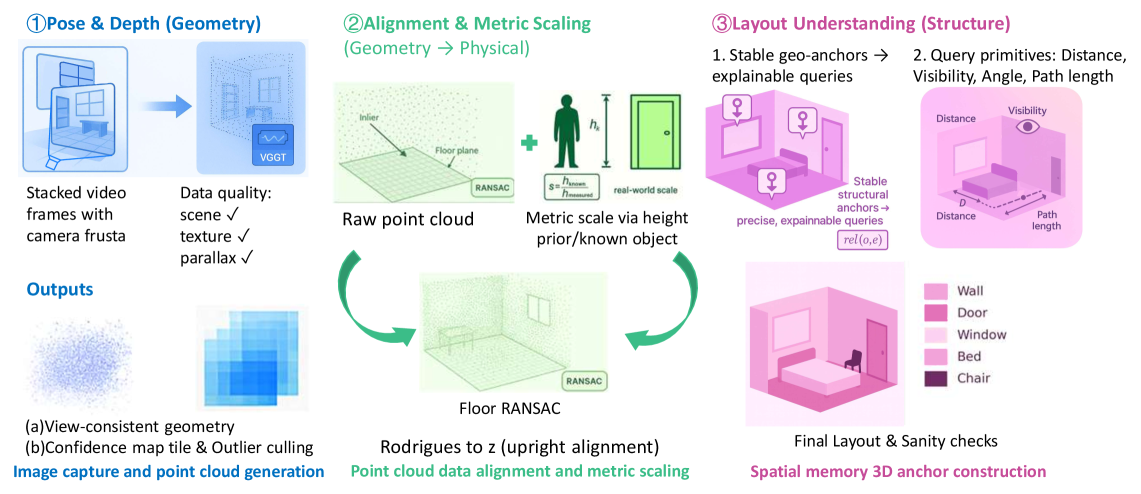
核心思路:SpatialMem的核心思路是构建一个统一的3D记忆系统,该系统能够从RGB视频中重建具有度量尺度的室内环境,并利用结构化的3D锚点(墙壁、门、窗)作为空间框架,将视觉、语义和语言信息关联到3D坐标。通过分层记忆结构和快速检索机制,实现对空间关系的推理和下游任务的支持。
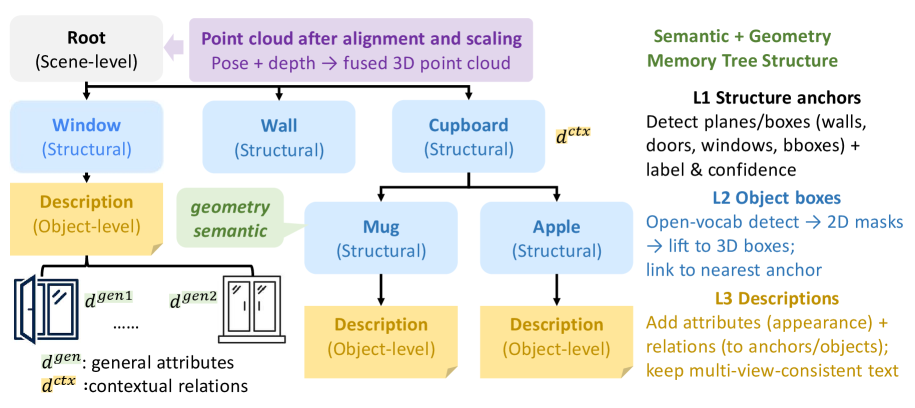
技术框架:SpatialMem系统主要包含以下几个模块:1) 3D重建模块:从RGB视频中重建具有度量尺度的室内环境。2) 3D锚点检测模块:检测结构化的3D锚点(墙壁、门、窗)作为空间框架。3) 分层记忆构建模块:用开放词汇的对象节点填充分层记忆,将证据块、视觉嵌入和两层文本描述链接到3D坐标。4) 查询和检索模块:基于空间关系和语言描述,实现对记忆的快速查询和检索。
关键创新:SpatialMem的关键创新在于其统一的3D记忆表示,它将3D几何、语义和语言信息整合到一个可查询的框架中。与现有方法相比,SpatialMem不需要专门的传感器,并且能够处理开放词汇的对象描述,具有更强的泛化能力。此外,SpatialMem的分层记忆结构和快速检索机制提高了查询效率。
关键设计:SpatialMem使用了一种两层的文本描述,第一层描述对象的类别,第二层描述对象的属性。这种设计能够更精确地描述对象,并支持更复杂的查询。在检索过程中,SpatialMem使用了一种基于空间关系的排序算法,根据距离、方向和可见性等因素对候选对象进行排序。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SpatialMem在三个真实室内场景中,即使存在杂乱和遮挡,也能保持较高的导航完成度和检索精度。具体来说,SpatialMem在锚点-描述级别导航完成度方面达到了XX%,在分层检索精度方面达到了YY%。与现有方法相比,SpatialMem在导航完成度和检索精度方面均有显著提升。
🎯 应用场景
SpatialMem可应用于机器人导航、智能家居、虚拟现实等领域。例如,机器人可以利用SpatialMem在室内环境中进行自主导航和对象检索;智能家居系统可以利用SpatialMem理解用户的语言指令,并执行相应的操作;虚拟现实应用可以利用SpatialMem构建更逼真的虚拟环境,并支持用户与虚拟环境进行交互。
📄 摘要(原文)
We present SpatialMem, a memory-centric system that unifies 3D geometry, semantics, and language into a single, queryable representation. Starting from casually captured egocentric RGB video, SpatialMem reconstructs metrically scaled indoor environments, detects structural 3D anchors (walls, doors, windows) as the first-layer scaffold, and populates a hierarchical memory with open-vocabulary object nodes -- linking evidence patches, visual embeddings, and two-layer textual descriptions to 3D coordinates -- for compact storage and fast retrieval. This design enables interpretable reasoning over spatial relations (e.g., distance, direction, visibility) and supports downstream tasks such as language-guided navigation and object retrieval without specialized sensors. Experiments across three real-life indoor scenes demonstrate that SpatialMem maintains strong anchor-description-level navigation completion and hierarchical retrieval accuracy under increasing clutter and occlusion, offering an efficient and extensible framework for embodied spatial intelligence.